“Silent Majority”
When it comes to watching YouTube videos, I often categorize myself as part of that “silent majority” group. As one of the 1.5 billion viewers of BTS’s most viewed music video, I managed not to smash that like button even though I played it probably more than 100 times.
In the dictionary of AI bias, my unconventional user behavior is a perfect example of selection bias, a common bias in recommendation system applications such as YouTube. Given recommended videos, the user can choose whether to rate and what to rate, making the observed rating distribution less representative of the hidden true rating distribution.
Biases in Recommendation Systems
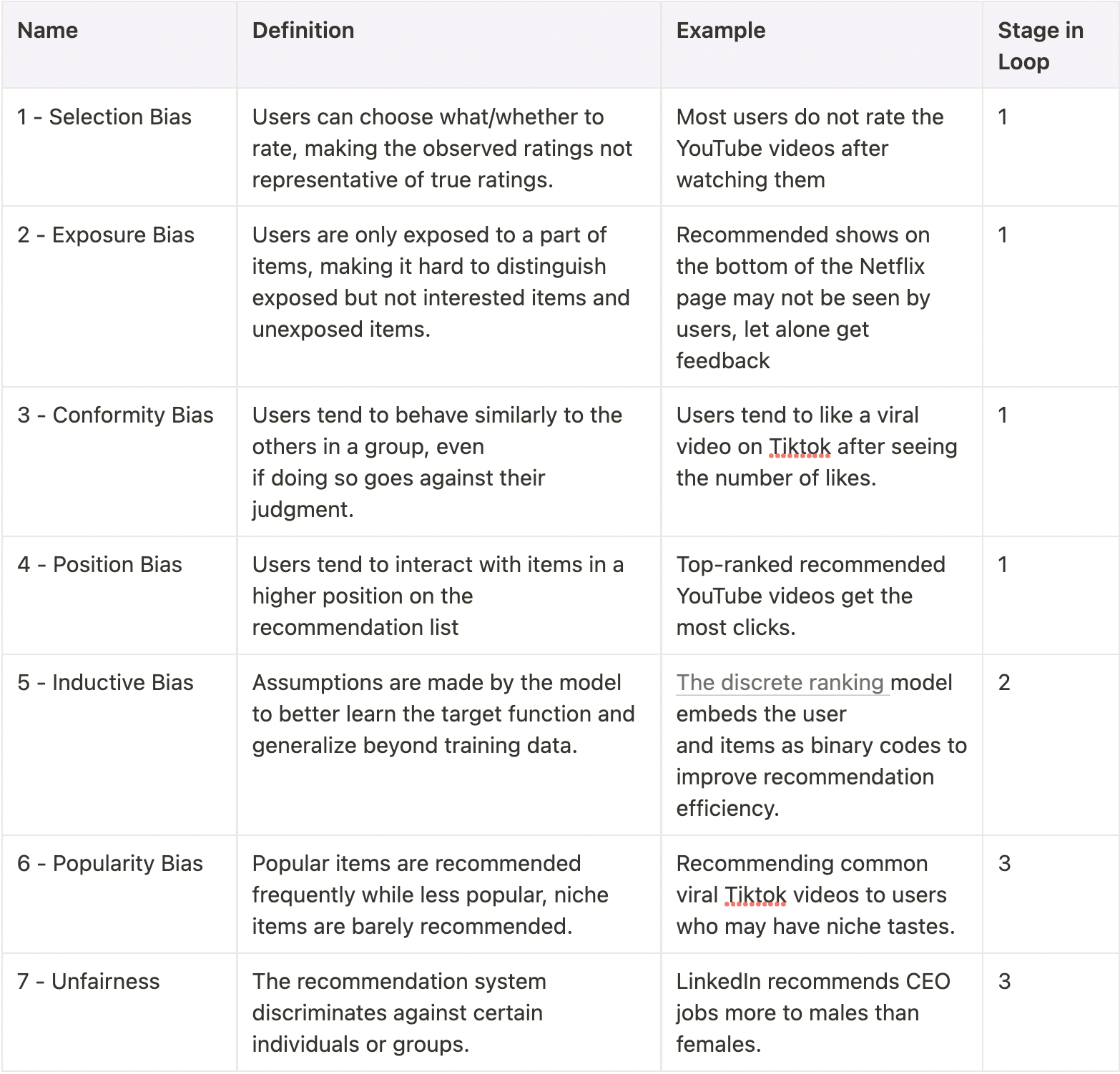
Besides the selection bias, many other biases can emerge in the recommendation system. The following table summarises the seven typical biases in recommendation systems, which follow the taxonomy of this latest survey paper. The illustrating examples in the context of recommendation systems are also provided to help you understand these biases more concretely.
Depending on the specific generation stage, these biases can be further clustered over the following feedback loop, which is an abstracted lifecycle of recommendations with three stages. Specifically, stage 1 (data collection) aims to collect the data from users, leading to the generation of data-associated biases such as selection bias, exposure bias, conformity bias, and position bias. Once data are collected, Stage 2 (model learning) learns the recommendation model from the data with model assumptions, i.e., inductive bias. Finally, in Stage 3 (recommendation), the learned model will return its recommendations to the users, which may involve recommendation-associated biases such as popularity bias and unfairness. These same three stages will keep iterating along the loop, collecting the latest user data for model updates and more recommendations.
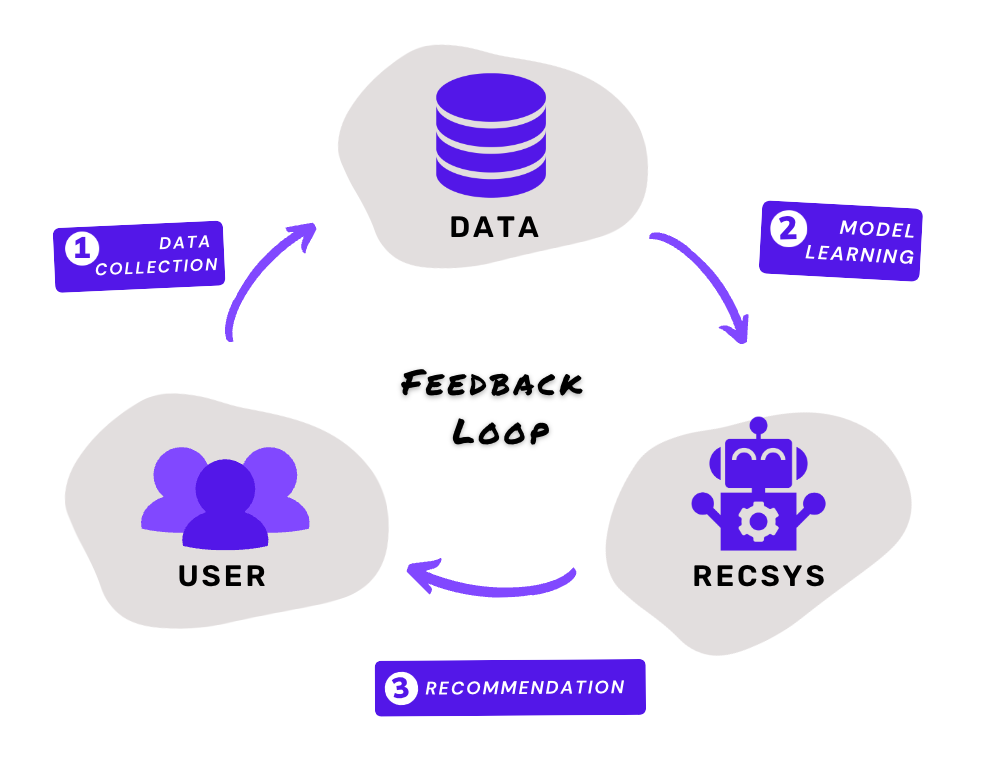 The feedback loop of recommendations, where different biases occur in three stages, i.e., the “data collection” stage, the “model learning” stage, and the actual “recommendation” stage.
The feedback loop of recommendations, where different biases occur in three stages, i.e., the “data collection” stage, the “model learning” stage, and the actual “recommendation” stage.
Feedback Loop Amplifies Biases
However, there is a growing concern regarding the effect of feedback loops. Google’s @DeepMind warned people back in their 2019’s tweet that feedback loops can amplify biases along the loop, leading to filter bubblesand echo chambers that can shift users’ views.
What are filter bubbles and echo chambers? And why are they so undesirable?
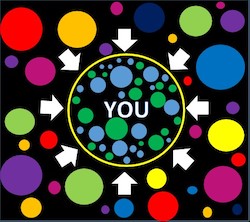 An illustration of filter bubble, where users are isolated from new and different content outside the bubble
An illustration of filter bubble, where users are isolated from new and different content outside the bubble
The concept of the Filter Bubble was initially proposed and discussed in 2011 by @Eli Pariser in his book “The Filter Bubble: What The Internet Is Hiding From You”, where he raised concerns regarding the increasingly personalized internet. He claimed that the recommendation algorithms of search engines and social networks, such as Google and Facebook, have created a distorted “bubble” world for users by filtering their search results based on relevance. For example, back then, Google utilized as many as 57 “signals” such as search history or geological location to better deliver the most “relevant” and customize content for users.
By restricting access to information outside, filter bubbles can further enhance the similar viewpoints to be shared and reinforced among homogenous groups with similar opinions. For example, in the 2016 US presidential election, Twitter information flows, such as liking and sharing posts, are shown to be more frequent among individuals with similar political backgrounds. This phenomenon is often termed Echo Chambers, which is a good analogy for describing the information echoing effect within the closed bubbles.
Both filter bubbles and echo chambers can be extremely harmful. From the perspective of users, overexposure to homogeneous content or viewpoints can make them feel bored as it doesn’t always align with what they want. Users may also want to be challenged from time to time with some opposing views for learning purposes. Hence limiting users within the bubbles and chambers can decrease the long-term user satisfaction and loyalty to the associated platforms. Moreover, filter bubbles can also harm the benefits of content creators who deliver new content for these users. For new creators who just enter the platform such as TikTok, the “lack of relevance” caused by filter bubbles makes their work less recommended and less likely to go viral. Consequently, many talented content creators who could have contributed good content for the platforms may be driven away, further damaging user satisfaction and deteriorating the platform’s “ecosystem” in the long run.
Eli Pariser’s TED talk on Filter Bubbles back in 2011
Moreover, echo chambers and filter bubbles can create more damage beyond individuals (users and content creators) and worsen society-level issues such as the spreading of misinformation. In a recent article published by Misinformation Review of Harvard Kennedy School, researchers analyzed news articles shared by more than 15K Twitter accounts. By visualizing user retweets and quotes as a network, the echo chamber effect is apparent - in the red “chamber”, conservatives tend to retweet and quote other conservatives more, and the same phenomenon appears in the blue liberal “chamber” as well. Moreover, the spreading frequency of misinformation, measured by the node size, is generally higher within each chamber, indicating a positive correlation between echo chambers and the spreading of misinformation (also validated statistically). Without promptly addressing echo chambers and filter bubbles, such social issues can eventually make users and society feel frustrated, damaging the user loyalty and reputation of Twitter as a platform.
 Visualizing the network structure of Twitter followers behavior: the node color indicates the follower’s partisanship while the node size represents the spreading frequency of misinformation, i.e., sharings from low-quality sources (source)
Visualizing the network structure of Twitter followers behavior: the node color indicates the follower’s partisanship while the node size represents the spreading frequency of misinformation, i.e., sharings from low-quality sources (source)
Mitigation: Exploration vs Exploitation
Given the problems of filter bubbles and echo chambers, what can we do about them to alleviate the negative consequences?
To find an answer, researchers from DeepMind conducted detailed simulations of various recommendation system algorithms, which differ in their priority of accurately predicting users’ interests or randomly promoting new content. The simulation result reveals that algorithms valuing more random exploration tend to have less system degeneracy, i.e., less severe effects of filter bubbles and echo chambers. Therefore, they conclude that the best remedy for both phenomena is to design recommendation systems with more random exploration, e.g., offering users more diverse and unexpected recommendations. Meanwhile, boosting the candidate item pool where recommendations are drawn can also help.
This remedy essentially brings us back to the well-known concept of trade-off between exploration vs exploitation in the recommendation system. Here exploitation refers to making recommendations that are seemingly optimal based on known user behavior data collected in the past. Exploitation is always safer due to its relevance, but it can also limit the model from discovering better options if they exist. By contrast, exploration overcomes this limit by recommending more random items, enabling the model to obtain more optimal recommendations from the larger pool of usage data. However, exploration may suffer from poor decisions made, resulting in wasted resources spent on exploring.
As we can see here, there indeed exists a fundamental dilemma between exploration and exploitation. To most effectively alleviate both filter bubbles and echo chambers, the goal is to find a strategy with a good trade-off between exploration and exploitation. Different exploration strategies are available, with the most popular ones beingEpsilon-Greedy Method, Optimistic Initialization Method, Upper Confidence Bounds (UCB) Method, and Thompson Sampling Method. We won’t go into too much detail here but if you are interested, highly recommend this medium article by @Joseph Rocca. It’s pretty well-written!
Here at Shaped, we address the trade-off between exploration and exploitation through Thompson Sampling in the ordering stage of our ranking engine. Specifically, some indeterminism is added into the final ranking (e.g. placing random candidate items towards the top of the rankings) to mitigate filter bubbles and echo chambers that bias the ranking algorithm. Does it sound relevant to you? Feel free to reach out to hello@shaped.ai for more information!
Not sure if Shaped is the right fit?
Talk to an engineer about your use case — no sales pitch, just answers.