As the volume of content and products available online grows exponentially, users are increasingly finding it difficult to discover items tailored to their unique interests. This is where recommendation systems come in, offering a powerful solution to this discovery problem and enhancing key business metrics.
In this two-part blog series, we will guide you through the essentials of data for recommendation systems. We will cover the types of data used, the characteristics of high-quality data, and what you can do to improve the quality of the data you’re collecting. It might surprise you to learn that there is no minimum amount of data required for a great recommendation system. Instead, collecting high-quality interactions and contextual information about users and the items being ranked is significantly more important. We’ll delve deeper into these concepts later, but first, we’ll discuss what a recommendation system is and when they become crucial to implement.
What is a recommendation system?
Recommendation systems are a set of rules or machine-learning algorithms that provide personalized recommendations to users based on their interests, behaviors and preferences. These systems are widely used in social media, streaming platforms, marketplaces and e-commerce to help with discovery of products, content, or services. The ultimate goal of a recommendation system is to help a user discover what they’re looking for, and in turn, benefit a business via increased engagement and revenue.
A recommendation system becomes crucial when you have more content or products than can be displayed on a single page. This excess of content or products makes manual curation a challenging task and leads to a discovery problem where users struggle to find relevant items. Such discovery problems result in decreased engagement and conversion rates, as frustrated users abandon their search when they cannot locate what they want.
 Many marketplaces and media platforms have 100s or 1000s of content or products which makes discovery for users difficult
Many marketplaces and media platforms have 100s or 1000s of content or products which makes discovery for users difficult
For instance, consider a user browsing through products in a carousel in an app. It is essential that these products represent the most relevant and meaningful options from your entire catalog. If the ideal product is just outside the displayed range, say at position 7, and the user doesn’t swipe further, you miss out on a valuable conversion opportunity.
 Items in a carousel should always be personalized from most to least likely to be meaningful to each user.
Items in a carousel should always be personalized from most to least likely to be meaningful to each user.
Types of data used in recommendation systems
One way we can categorize data for recommendation systems is using these three categories: users, items and interactions.
 Types of data used in recommendation systems
Types of data used in recommendation systems
Users is what you’re personalizing for, items are the content or product that are being ranked, and interactions convey intent for a user’s affinity or preference towards specific items i.e. it allows the recommendation system to understand the relationship between users and items. Interactions include things like views, clicks, ratings, purchases, likes, dislikes, loves and any other positive or negative event that you track. As mentioned earlier the volume of data is less important than the quality.
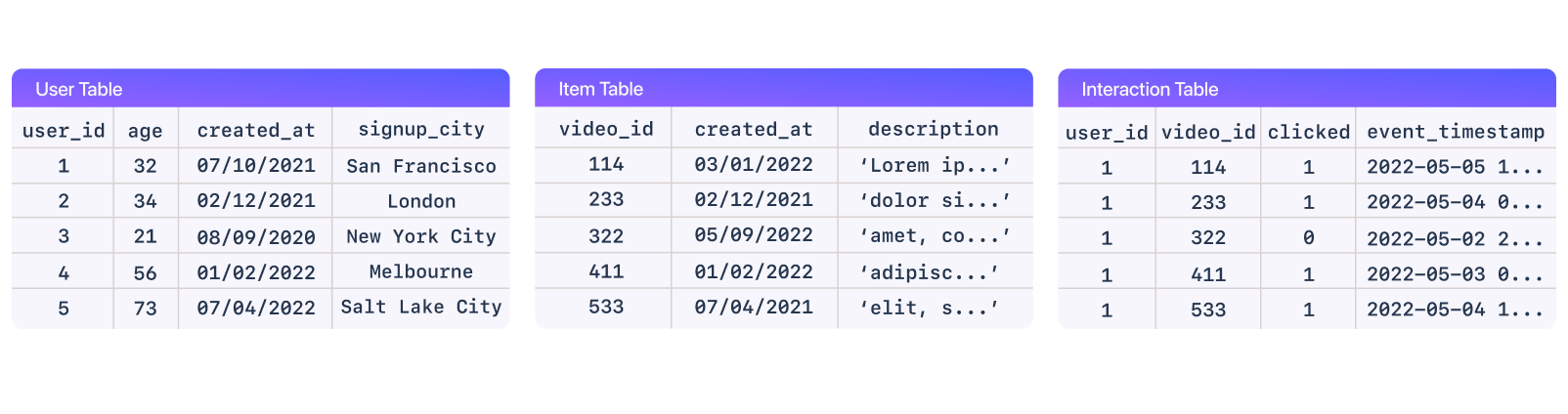 Examples of the data tables of user, item, and interactions. Note: your data does not need to be in this or any particular format to use a recommendation system. Shaped connects directly to all of your data stores and does the transforms for you!
Examples of the data tables of user, item, and interactions. Note: your data does not need to be in this or any particular format to use a recommendation system. Shaped connects directly to all of your data stores and does the transforms for you!
What makes interaction signals high-quality?
High-quality interaction signals refer to the authenticity, clarity, and unambiguity of feedback about a user’s preferences for an item. High-quality signals enable recommendation systems to learn more effectively from the user’s behavior and provide more accurate and relevant recommendations. Factors that contribute to high-quality interaction signals include the nature of interactions (explicit or implicit), the presence of biases, and the distribution patterns of the interactions. Examples of high-quality signals are clear and direct actions such as explicit ratings, reviews, and likes, which unambiguously convey a user’s preference.
Explicit interactions
Explicit interactions are direct, intentional actions taken by users to express their preferences, such as ratings, reviews, or likes. They provide strong, unambiguous feedback about user preferences, making it easier for recommendation systems to learn from them. However, explicit interactions may be fewer in number and subject to biases, such as inconsistencies in rating interpretation, known as user rating scale bias.
Netflix addressed user rating scale bias by replacing the one-to-five star rating system with a thumbs up/down paradigm and later adding a two-thumbs up option, allowing users to express a stronger positive signal. This change led to higher confidence and quality interaction signals for their recommendation system.
 Netflix introduced thetwo-thumbs upto signify a stronger positive signal, overcoming biases associated with single thumbs-up ratings and star ratings.
Netflix introduced thetwo-thumbs upto signify a stronger positive signal, overcoming biases associated with single thumbs-up ratings and star ratings.
Implicit Interactions
Implicit interactions are indirect actions taken by users, such as browsing history, clicks, time spent on an item, or purchase history. These interactions are often more abundant than explicit interactions but can be noisy and harder to interpret since they don’t always indicate a clear preference.
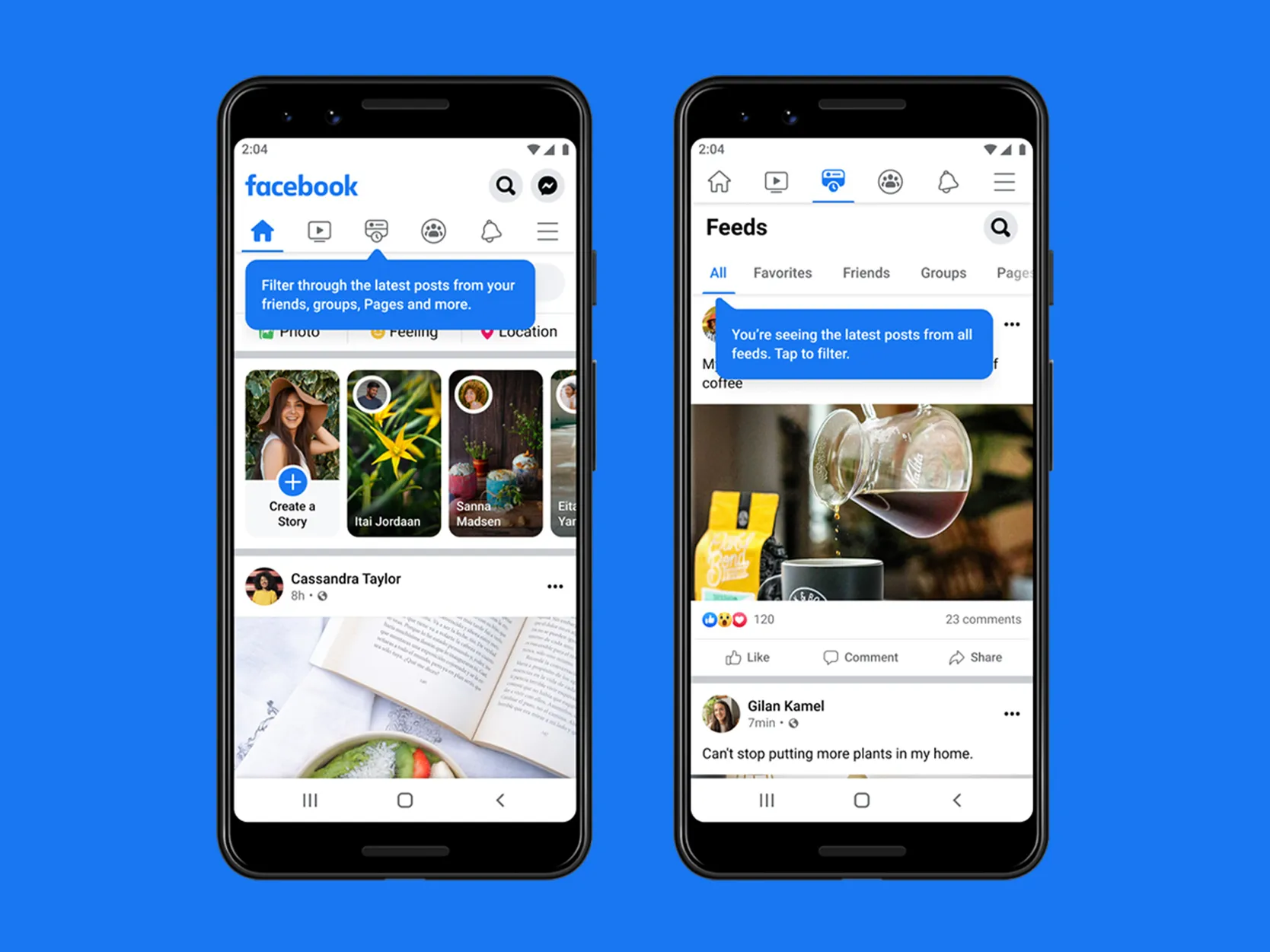 The Facebook interface displays multiple posts and UI elements on a single page
The Facebook interface displays multiple posts and UI elements on a single page
On platforms like Facebook, unintentional implicit signals can affect the system’s understanding of user preferences and lead to less relevant recommendations. TikTok’s user interface, on the other hand, collects higher quality implicit signals by only showing a single video on their For You Page, enabling the platform to better understand user preferences.
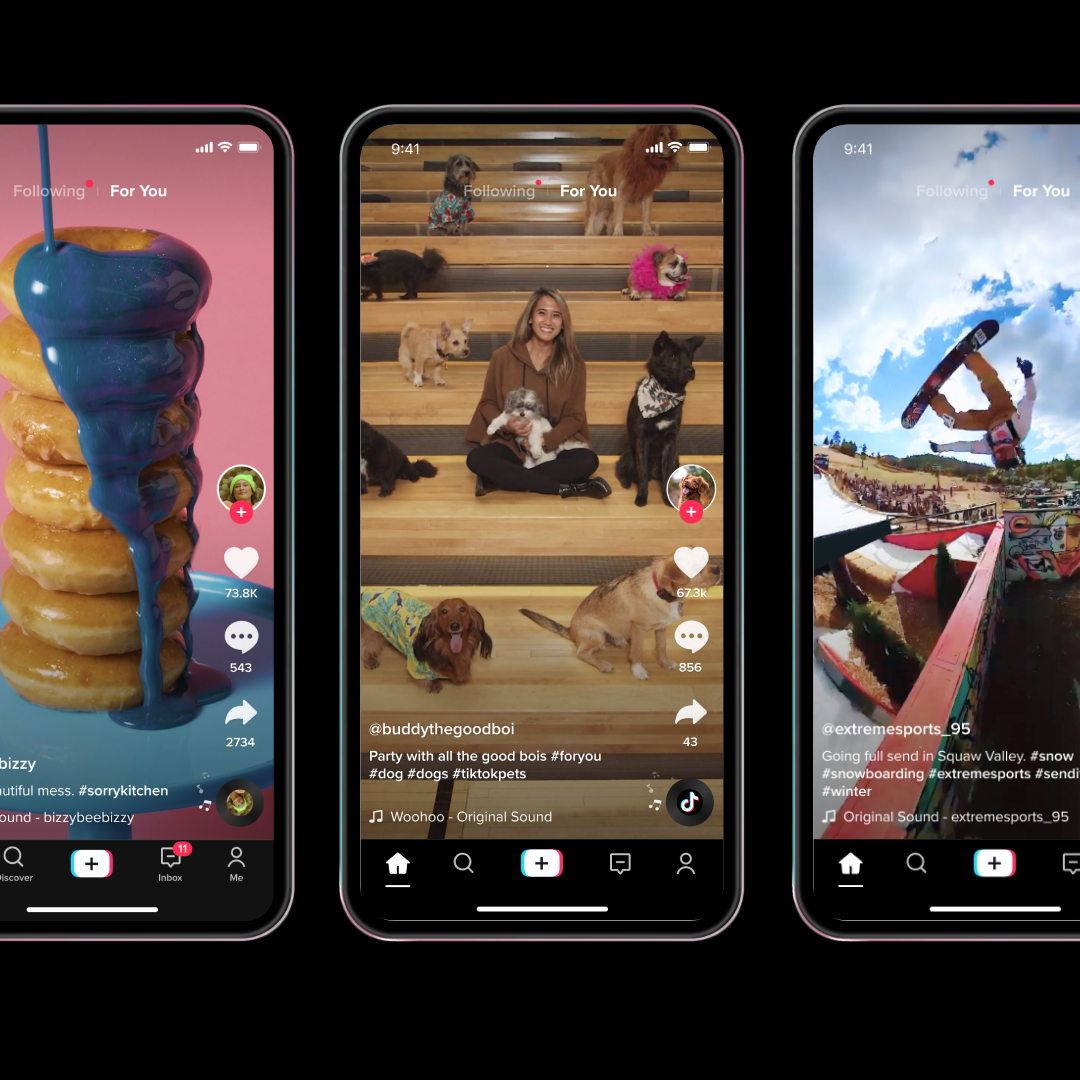 TikTok improves the quality and accuracy of their user interaction signals by only showing a single video at once
TikTok improves the quality and accuracy of their user interaction signals by only showing a single video at once
Biases in interactions
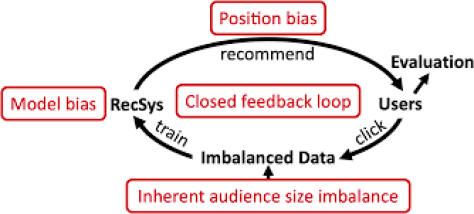 A loop of detecting and mitigating bias|Source
A loop of detecting and mitigating bias|Source
Biases in interaction signals can negatively impact the performance of recommendation systems. Examples of biases include position bias, selection bias, and temporal bias. These biases are present in almost all real-world datasets and require exploratory data analysis and several treatment strategies to manage. We’ll cover detailed examples of how to manage these later in the blog post.
- Position Bias: The order or placement of items can impact the likelihood of user interaction. For example, items listed at the top or on the first page are more likely to be clicked on than items buried deeper in the list. Randomization and counterbalancing of items are typically used strategies to negate the effects of position bias.
- Selection Bias: Users typically interact with a limited subset of items, often influenced by the platform’s presentation or the user’s inherent biases. This can lead to an incomplete view of user preferences, affecting the recommendation system’s ability to provide diverse and relevant recommendations. For example presenting items based on their recency or what’s most popular (also know as a top list) creates selection bias.
- Temporal Bias: User preferences may change over time, and older interactions might no longer reflect current interests. Additionally, items’ popularity may change, affecting their relevance in recommendations.
Sampling and distribution of interactions
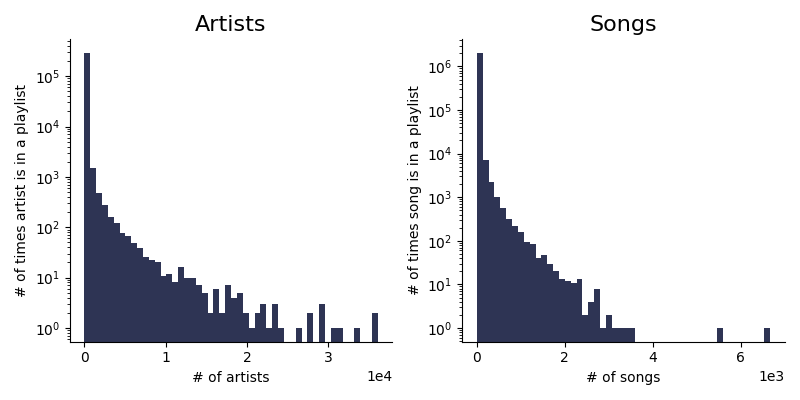 What interaction data usually looks like
What interaction data usually looks like
Recommendation systems also make several assumptions about the sampling and distribution of interactions. These assumptions include the uniform distribution assumption, the random sampling assumption and having a balance of positive and negative interactions. Violations of any of these assumptions leads to sub-optimal recommendation results.
- **Uniform Distribution Assumption:**Recommendation systems assume that interactions are uniformly distributed across users and items. This means that each user has interacted with a similar number of items, and each item has received a similar number of interactions from users. However, in reality, interactions follow the power law, are often distributed unevenly, leading to a long-tail distribution where some items receive significantly more interactions than others. Additionally if a company previously manually curated items or showed a top list such as most recent or most popular this will have introduced significant biases where some items will have huge amount of clicks due to nothing more than positioning.
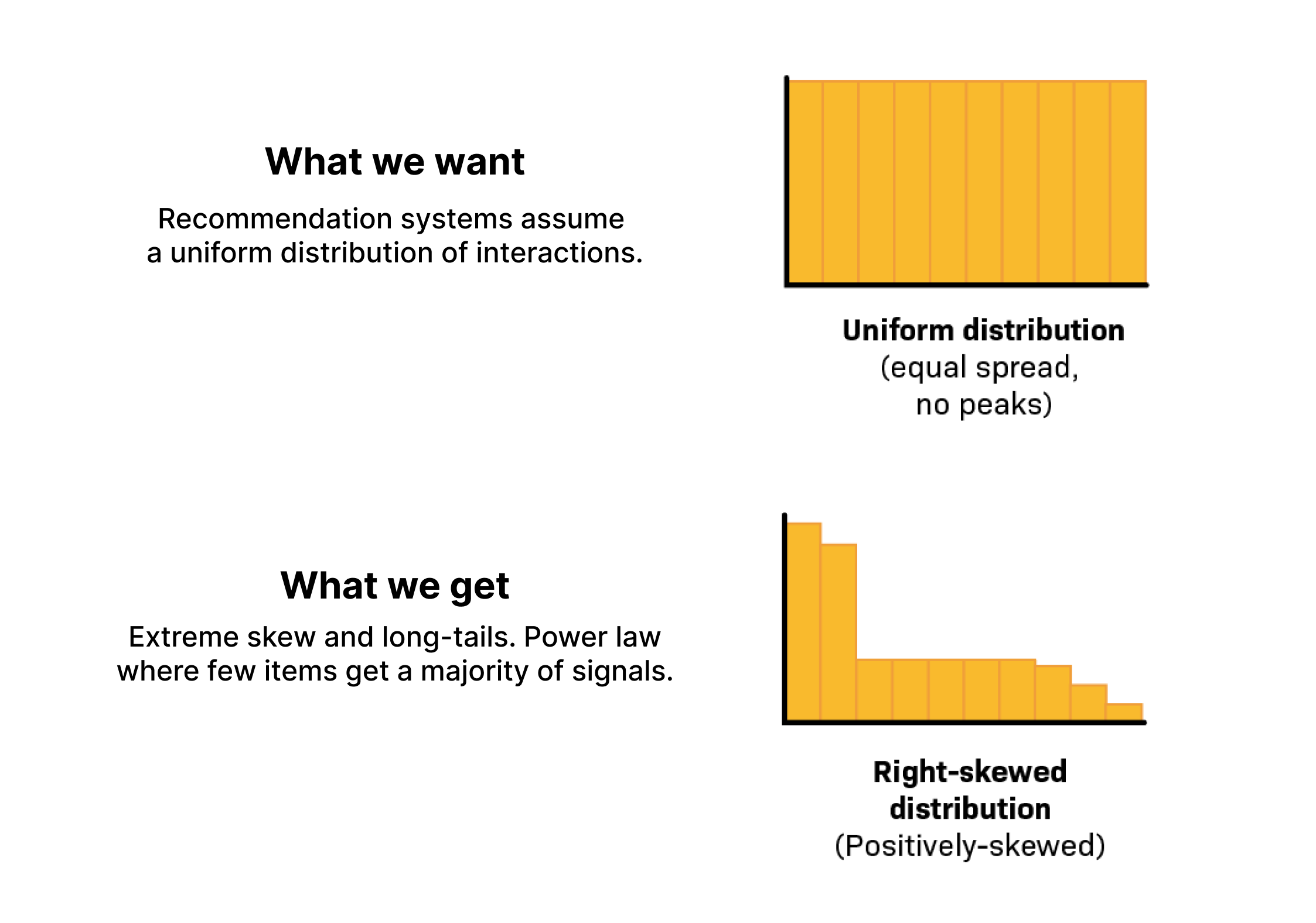 Adapted from thispaper
Adapted from thispaper
- Random Sampling Assumption: In order to reduce computational complexity and noise in the data, recommendation systems often use sampling techniques to select a subset of interactions. The assumption here is that the sampled data is representative of the overall user-item interaction space. However, if the sampling process introduces biases or fails to capture the diversity of user preferences, it can negatively impact the recommendation system’s performance.
 Sampling from data. Ref Pic:link
Sampling from data. Ref Pic:link
- **Balance of positive and negative interactions:**Having a balance of positive and negative feedback in a recommendation system and machine learning is crucial for accurately modeling user preferences and generating meaningful recommendations. A balanced dataset allows the system to better understand what users like and dislike, leading to more precise predictions. Moreover, it helps the learning algorithm to distinguish between various patterns and relationships in the data, preventing it from becoming biased towards either positive or negative outcomes. Most real-world datasets however contain an exponential amount of negative interactions compared to postive interactions.
 A balance of positive and negative interactions is crucial for understanding user preferences
A balance of positive and negative interactions is crucial for understanding user preferences
How to improve the quality of your interactional signals
In order to collect high-quality interaction signals, it is essential to address limitations and minimize biases in sampling and interactions.
Here are 7 techniques and strategies you can employ:
- Re-ordering or shuffling items: Periodically re-ordering or shuffling the items in a list can introduce randomness, exposing users to a wider variety of content. This approach helps reduce the position bias, as items that were previously lower in the list have an increased chance of being seen and interacted with by users.
- **Exploration vs. Exploitation trade-off:**Recommendation systems can balance the trade-off between exploration and exploitation. Exploitation refers to recommending items based on the user’s known preferences, while exploration involves suggesting items that the user might not have seen before, even if they don’t perfectly match their known preferences. By increasing exploration, the system can expose users to a more diverse range of items and collect additional interaction data, reducing selection bias.
- Diversification of recommendations: Ensuring that recommendations include a mix of popular and less popular items can help in addressing sampling biases. By recommending lesser-known items alongside popular ones, the system can gather more information about user preferences, improving its overall accuracy and relevance.
- **Time-based randomization:**Introducing time-based randomization can help mitigate temporal bias. By periodically updating the recommendations or the order of items, users are exposed to content that might not have been popular when they last interacted with the platform, allowing the system to gather more diverse interaction data.
- **Stratified sampling:**Stratified sampling can be used to ensure that all categories or segments of items are proportionally represented in the recommendations. By dividing items into different groups based on their popularity or other attributes, the recommendation system can then sample items from each group, ensuring a more balanced representation of the overall item space.
- **Collecting more positive or negative interaction signals (whichever you have less of):**This can be done by introducing new UI elements such as dislikes, similar to what Netflix did or computing variables as negative e.g. impression but not a click. Balancing positive and negative interactions is crucial for accurately modeling user preferences and generating meaningful recommendations. A balanced dataset allows the system to better understand users’ likes and dislikes, leading to more precise predictions and recommendations.
- Deploying a recommendation system with all the above strategies implemented to production: This will help address violations of assumptions and biases by actively adapting to real-time user interactions and preferences. As users engage with the new recommendation system, it will continuously learn from their behavior, providing a more accurate and up-to-date representation of their interests. This ongoing process allows the system to adjust for any biases that may have been present in the initial dataset, making recommendations more relevant and personalized for each user.
In summary, high-quality interaction signals in recommendation systems involve a balanced combination of explicit and implicit interactions, awareness and mitigation of biases, and thoughtful consideration of sampling and distribution techniques. By addressing these factors, recommendation systems can offer more accurate, relevant, and personalized suggestions to users.
Stay tuned for part-two!
In addition to collecting high-quality interactions, another two critical factors for recommendation system are sparsity and contextual information. Sparsity refers to the proportion of interactions relative to the number of users and items. In part two of this blog post, we will examine sparsity in more depth and explain why collecting contextual information is crucial for performance. We will also look at the latest innovations in machine-learning that are reducing data requirements and revolutionizing recommendation systems for companies of all sizes.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.