
In recommendation systems and online advertising, simply retrieving a relevant set of candidates isn’t enough. The final step – ranking these candidates precisely to maximize user engagement (like clicks, conversions, or watch time) – is where the rubber meets the road. This often boils down to predicting a score for each individual user-item pair, a task known as pointwise ranking. Predicting Click-Through Rate (CTR) is a canonical example.
While retrieval models like Two-Tower excel at efficiently narrowing down vast catalogs, they often simplify the interaction between user and item features to enable speed. Pointwise ranking models, however, are designed to dive deep into these feature interactions. They aim to understand complex relationships like “this user likes this specific brand but only in this category, and usually clicks on items with free shipping.”
A powerful class of deep learning models has emerged to tackle this challenge, often falling under the umbrella of Deep Learning Recommendation Models (DLRMs). Prominent examples include:
- Wide & Deep Learning(Google)
- DeepFM(Deep Factorization Machine) (Huawei/HIT)
- DCN (Deep & Cross Network)(Google)
- MaskNet(Sina.com)
These models share a common goal: effectively combine the power of deep neural networks for learning complex patterns with specialized mechanisms to explicitly model interactions between sparse, high-dimensional features typical in recommendation and advertising datasets.
This post explores these DLRM-style ranking models:
- The critical importance of feature interactions.
- The evolution from manual feature crossing to learned interactions.
- Key architectures like Wide & Deep and DeepFM explained.
- Common components and how they work.
- Challenges in building and deploying these models.
- How platforms like Shaped facilitate their use.
The Challenge: Why Feature Interactions Matter (and are Hard)
Recommendation and ad datasets are often characterized by:
- Sparsity: Users interact with only a tiny fraction of items.
- High Cardinality Categorical Features: User IDs, item IDs, ad IDs, categories, etc., can have millions or billions of unique values.
- Mix of Features: Combining categorical data with dense features (e.g., user age, item price, historical CTR).
Simple models struggle here. A basic linear model might capture the effect of “user likes category X” or “item Y is popular,” but fails to capture combinations like “user A specifically likes item Y.” A standard Deep Neural Network (DNN) fed with concatenated raw features might implicitly learn some interactions, but doing so efficiently and effectively with extremely sparse, high-cardinality inputs is difficult.
Feature interactions are combinations of features that provide more predictive power together than individually. For example:
- AND(user_location=‘USA’, item_category=‘Winter Coats’) -> Higher probability of click in winter.
- AND(user_interest=‘Gardening’, item_brand=‘Acme Seeds’) -> Higher probability of click.
Manually crafting these (“feature crossing”) is possible but becomes combinatorially explosive and requires domain expertise. We need automated ways to learn important interactions.
Evolution: From Manual Crossings to Learned Interactions
- Manual Feature Crossing: Engineers explicitly create new features by combining existing ones (e.g., creating a feature representing every unique user-category pair). Effective but brittle and doesn’t scale.
- Factorization Machines (FMs): A breakthrough model that efficiently learns pairwise (2nd order) feature interactions. It represents each feature with a latent vector and models the interaction between feature i and feature j as the dot product of their vectors (v_i ⋅ v_j). FMs provide a principled way to handle sparse data and learn interactions automatically.
- DLRM-Style Deep Models: These models aim to capture both low-order (like FM) and high-order (complex, non-linear) feature interactions using deep learning. They typically combine learned embeddings with explicit interaction components.
Key Architectures: Wide & Deep, DeepFM, DCN, MaskNet
These models offer different strategies for combining learned representations (“deep”) with feature interaction modeling (“wide” or “cross” or “FM”):
1. Wide & Deep Learning
- Concept: Explicitly combines a Wide linear model with a Deep neural network, training them jointly.
- Wide Part: A generalized linear model fed with raw input features and manually engineered cross-product features. This part excels at memorizing specific, sparse feature combinations that correlate strongly with the target (e.g., “user X always clicks on brand Y”).
- Deep Part: A standard feed-forward neural network (MLP) fed with dense embeddings learned for the categorical features, plus normalized dense features. This part excels at generalizing to unseen feature combinations by finding non-linear patterns in the lower-dimensional embedding space.
- Combination: The outputs of the wide and deep parts are summed (usually before the final activation function, like sigmoid for CTR) to produce the final prediction.
- Strength: Explicitly balances memorization and generalization.
- Weakness: Still relies on manual feature crossing for the wide part, which can be laborious.
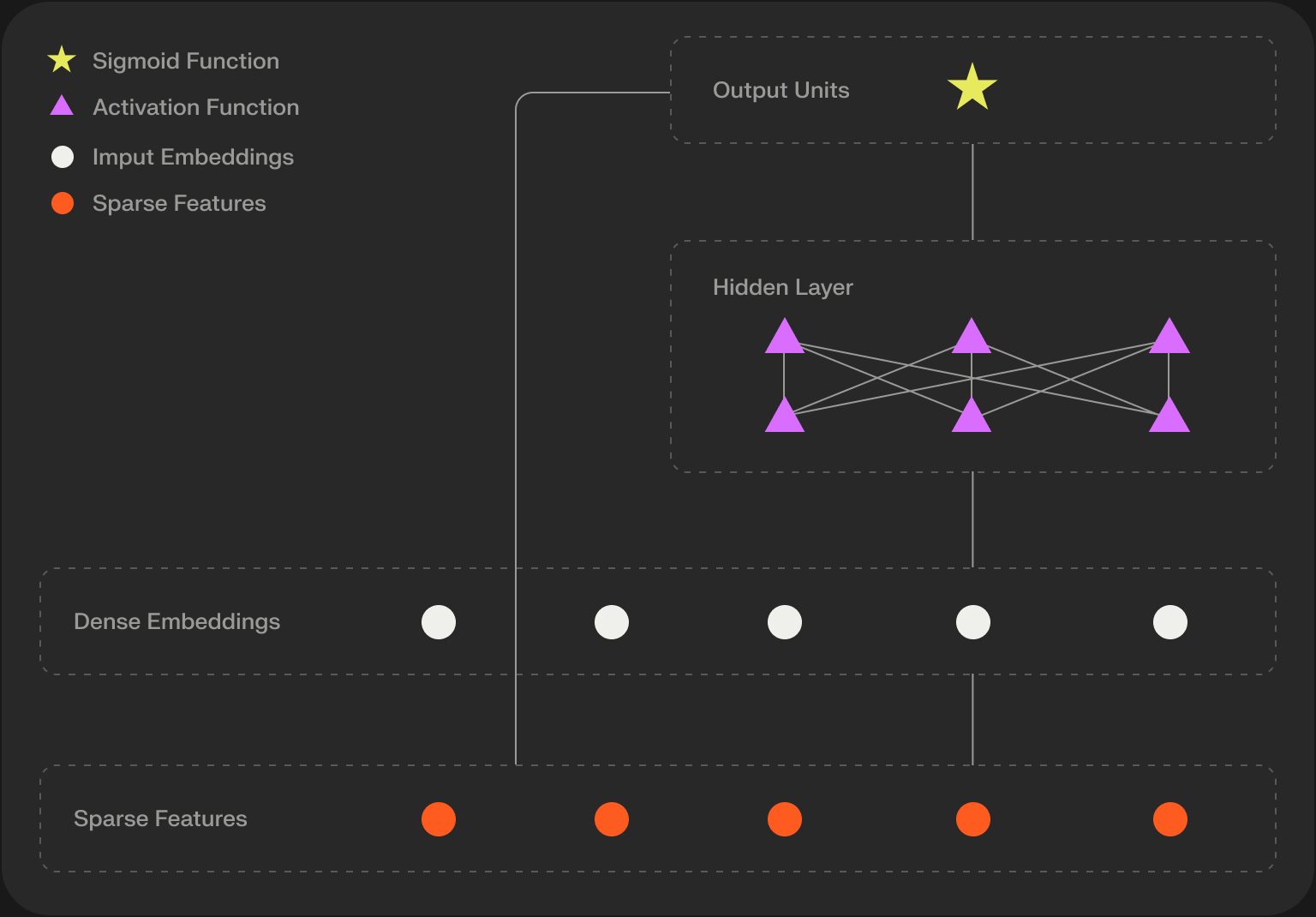
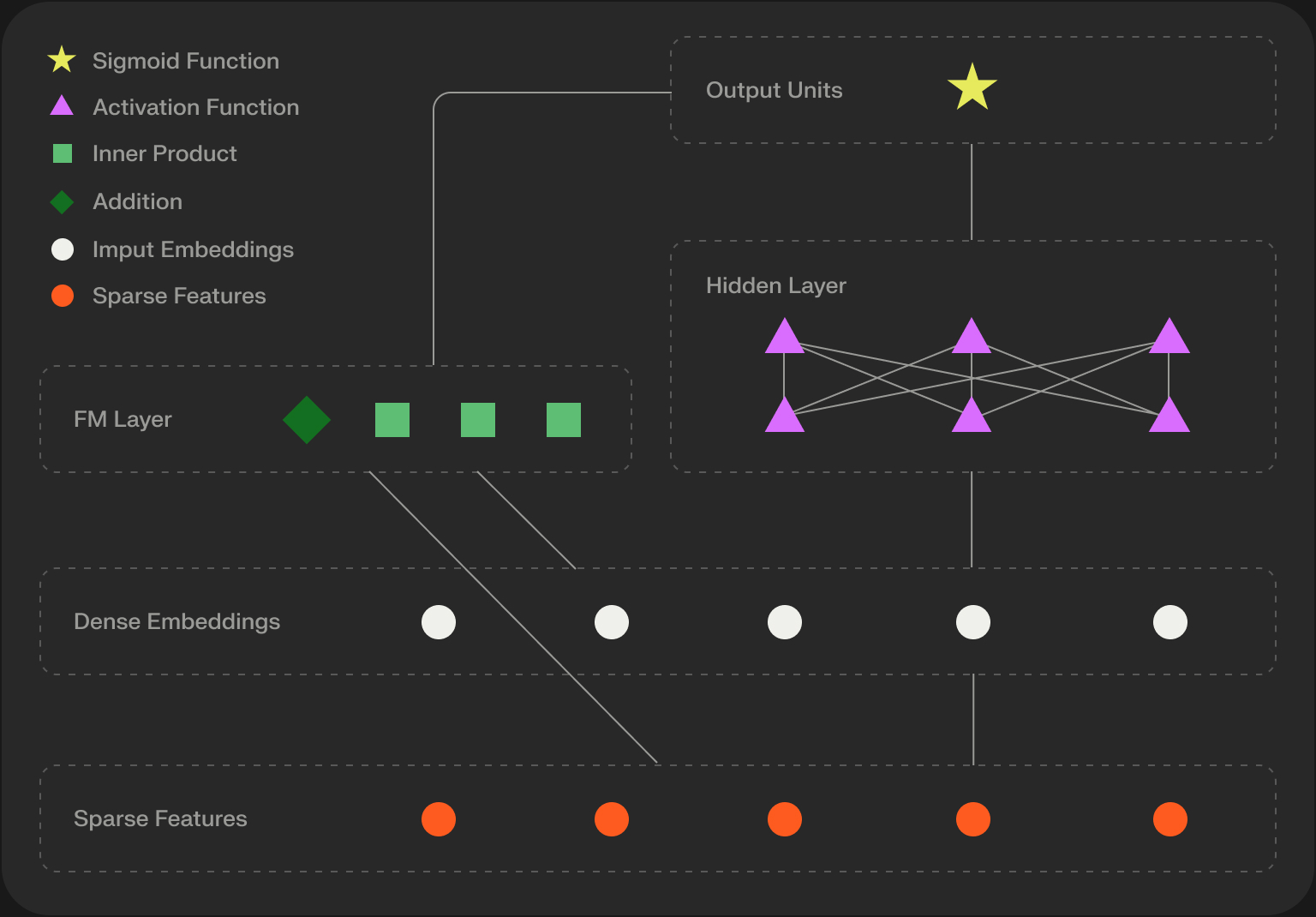
2. DeepFM (Deep Factorization Machine)
- Concept: Combines the strengths of Factorization Machines (FMs) and DNNs in an end-to-end model, eliminating the need for manual feature crossing.
- FM Component: Operates on the learned feature embeddings. It efficiently computes pairwise interactions (v_i ⋅ v_j) for all features, capturing 2nd order interactions just like a standard FM.
- Deep Component: A standard MLP fed with the same feature embeddings used by the FM component. This part learns high-order, non-linear interactions implicitly.
- Combination: The outputs of the FM component (capturing 1st and 2nd order interactions) and the Deep component (capturing high-order interactions) are summed before the final prediction layer.
- Strength: Fully end-to-end learning of low- and high-order interactions without manual feature engineering for interactions. Often more efficient than Wide & Deep.
- Weakness: The deep part might implicitly relearn some pairwise interactions already captured by the FM part.
3. DCN (Deep & Cross Network)
- Concept: Replaces the Wide part (or FM part) with a novel Cross Network.
- Cross Network: Explicitly applies feature crossing in an efficient, layer-by-layer manner. Each layer computes higher-order interactions based on the previous layer’s output and the original input features, controlled by learned weights. The degree of interaction increases with layer depth.
- Deep Network: A standard parallel MLP tower, similar to Wide & Deep or DeepFM.
- Combination: Outputs from the Cross Network and Deep Network are combined (often concatenated) before the final prediction layer.
- Strength: Explicitly and efficiently learns bounded-degree feature interactions automatically.
- Weakness: The structure of the cross network is quite specific.
4. MaskNet
- Concept: Uses learned masks (element-wise multiplication) between feature embedding layers to selectively model feature interactions, mimicking the logic of decision trees within a neural network framework.
- Mechanism: Instead of simple concatenation or dot products, it uses instance-guided masks (derived from other features) applied to feature embeddings. This allows certain features to dynamically gate or enhance the influence of other features. Can be applied serially (like deep trees) or in parallel (like ensembles).
- Strength: Offers a potentially more nuanced way to model feature interactions, potentially capturing context-dependent relationships more effectively than simpler additions or concatenations.
- Weakness: Can be architecturally more complex.
How DLRMs Work: Common Components
Most DLRM-style rankers share a similar overall structure:
- Input Layer: Handles diverse input features:
- Dense Features: Numerical values (e.g., price, age), typically normalized.
- Sparse Categorical Features: High-cardinality IDs (user, item, ad), categories, etc.
- Embedding Layer: Converts each sparse categorical feature into a low-dimensional dense vector (embedding). This is where the bulk of the model parameters often reside. Techniques like feature hashing might be used for extremely high-cardinality features.
- Feature Interaction Layer(s): This is the core innovation. It explicitly models interactions between features (embeddings and dense features). Examples:
- Wide & Deep: Cross-product transformation + Linear layer.
- DeepFM: FM layer (pairwise dot products).
- DCN: Cross Network layers.
- MaskNet: Masking layers (element-wise product).
- Deep Layers (MLP): A stack of fully connected layers (often with ReLU activation) processes the embeddings (and potentially outputs from the interaction layer) to capture complex, high-order, non-linear patterns.
- Output Layer: Combines the signals from the interaction layers and deep layers (e.g., via summation or concatenation followed by a final linear layer) and applies a final activation function (e.g., Sigmoid for CTR prediction between 0 and 1).
Building From Scratch: The Challenges
Deploying these models effectively requires addressing several hurdles:
- Feature Engineering: While interaction learning is automated, deciding which raw features to include and how to preprocess dense features still matters.
- Handling Sparsity & Cardinality: Managing massive embedding tables efficiently during training and serving is critical (memory, computation). Techniques like adaptive embeddings or feature hashing are often needed.
- Hyperparameter Tuning: Finding the right embedding dimensions, network architecture (depth, width), learning rates, regularization strengths, etc., requires careful experimentation.
- Computational Cost: Training these models, especially with large datasets and embedding tables, can be computationally intensive.
- Serving Latency: Rankers need to score candidates quickly. Complex models can increase inference latency, requiring optimization (model compression, efficient serving infrastructure).
DLRMs in Practice: Configuration with Shaped
Platforms like Shaped abstract the underlying complexity, allowing you to configure these powerful ranking models declaratively. Shaped supports several DLRM-style models directly as scoring_policy types:
- Wide & Deep:
# wide_deep_model.yaml
model:
name: my-wide-deep-ranker
policy_configs:
scoring_policy:
policy_type: wide-deep
wide_features: [user_x_category, item_brand, user_location]
deep_hidden_units: [256, 128, 64]
activation_fn: relu
embedding_policy:
policy_type: two-tower- DeepFM:
# deepfm_model.yaml
model:
name: my-deepfm-ranker
policy_configs:
scoring_policy:
policy_type: deepfm
embedding_dim: 16
deep_hidden_units: [128, 64, 32]
activation_fn: relu
dropout: 0.2
embedding_policy:
policy_type: two-towerBy specifying the policy_type and relevant hyperparameters, you can leverage these advanced architectures for your ranking tasks within the Shaped ecosystem, letting the platform handle the underlying training, feature management, and deployment complexities. Note that tree-based rankers like lightgbm or xgboost (often configured for lambdarank) are also potent competitors in this scoring/ranking stage and easily configurable in Shaped.
Advantages and Disadvantages
Advantages:
- ✅ State-of-the-Art Accuracy: Often achieve top performance on ranking tasks (especially CTR) due to effective feature interaction modeling.
- ✅ Automated Interaction Learning: Models like DeepFM, DCN, MaskNet reduce or eliminate the need for manual feature crossing.
- ✅ End-to-End Learning: Can learn feature embeddings and interactions jointly.
Disadvantages:
- ❌ Complexity: Architectures can be complex to understand and tune compared to simpler models.
- ❌ Computational Cost: Can be demanding to train, especially with large embedding tables.
- ❌ Latency: Inference can be slower than simpler models, requiring optimization for real-time serving.
- ❌ Feature Engineering Still Matters: Choice and preprocessing of input features remain important.
Conclusion: Powering Precise Personalization
DLRM-style ranking models like Wide & Deep, DeepFM, DCN, and MaskNet represent a significant advancement in recommendation systems and computational advertising. Their ability to automatically learn both low-order and high-order interactions between sparse, high-cardinality features is key to achieving high accuracy in pointwise ranking tasks like CTR prediction.
While they come with increased complexity compared to retrieval models or simpler rankers, their proven effectiveness makes them indispensable tools for fine-tuning personalization. Platforms like Shaped provide managed implementations, making these powerful techniques accessible for building sophisticated, high-performing ranking systems. Understanding their principles is crucial for anyone involved in optimizing modern recommendation and search experiences.
Further Reading / References
- Cheng, H. T., et al. (2016). Wide & deep learning for recommender systems. RecSys. (Wide & Deep paper)
- Guo, H., et al. (2017). DeepFM: A factorization-machine based neural network for CTR prediction. IJCAI. (DeepFM paper)
- Wang, R., et al. (2017). Deep & cross network for ad click predictions. KDD. (DCN paper)
- Wang, R., et al. (2021). DLRM: An advanced open source deep learning recommendation model. arXiv. (Overview paper)
- Yu, W., et al. (2021). MaskNet: Introducing feature-wise multiplicative interactions to deep learning models for CTR prediction. arXiv. (MaskNet paper)
Ready to implement cutting-edge ranking models like Wide & Deep or DeepFM?
Request a demo of Shaped today to see how our platform simplifies building and deploying high-performance rankers. Or, start exploring immediately with our free trial sandbox.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.