
Have you ever received a recommendation for a product or service that was completely new to you, but ended up being exactly what you needed? That feeling of discovering something unexpected and useful is what the novelty metric in recommendation systems aims to capture. In a world where we are inundated with choices and information, the ability to discover new and interesting items can be a valuable feature for users. In the previous post, we talked about serendipity as one of the ways to measure how a recommendation system can find unexpected but useful items, we looked into how similarity can help us, this time we will look into how to use dissimilarity instead.
As recommendation systems become more sophisticated, it’s important to evaluate not just their ability to suggest relevant items, but also their ability to suggest novel and diverse items. In this post, we’ll dive into the world of novelty metrics in recommendation systems, exploring what they are, why they matter, and how they can be used to evaluate the effectiveness of recommendation algorithms.
We’ll also take a closer look at some of the challenges involved in measuring novelty, and the different approaches that have been proposed to address them. By the end of this post, you’ll have a deeper understanding of why novelty is such an important factor in recommendation systems, and how you can use novelty metrics to improve the user experience of your recommendation system.
Novelty: full of surprises 🎁
As mentioned before the key difference between serendipity from Part 1 and novelty are:
💡 Novelty tends to focus more on the degree to which recommended items are dissimilar to items that the user has already interacted with, while serendipity may take into account factors like the user’s preferences or interests.
💡 Additionally, serendipity may involve a stronger emphasis on the unexpectedness of the recommendation, whereas novelty may be more concerned with the diversity of the recommendations overall.
To understand how we can mathematically extract concepts like diversity and dissimilarity we should start with the essence of both - a measure of how two items or sets can be similar.
Similarity metrics
An old-school way of determining a novelty of an item is through similarity or rather its inverse.
Recalling from Part 1 we learned about Cosine Similarity as one of the basic ways to define how two items in a recommendation system can be considered similar:
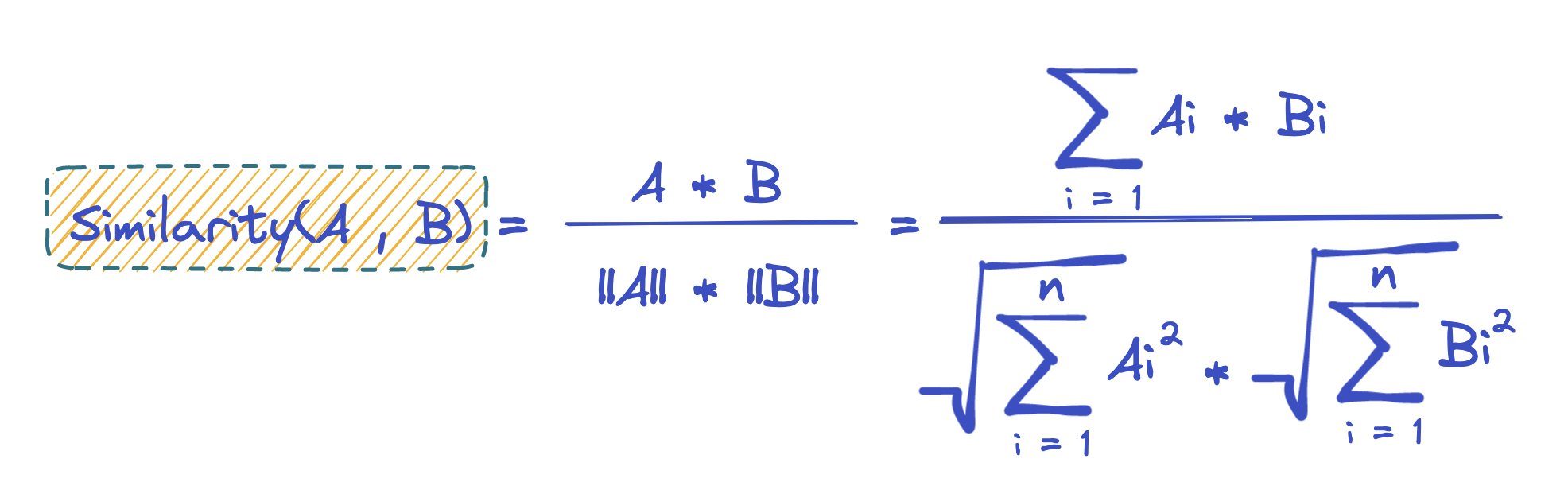
Where A and B, are two vectors that can represent two items in a recommendation system, say an anime edit you saved and a new action movie trailer. What we did not dive into last time is the importance of choosing the right similarity metric.
💡Topology of data matters! Try to think about your dataset and your users, if we are getting feedback in form of categorical ‘yes’ or ‘no’ variables that can’t be represented in a continuous manner (say in the range from 0-1). Our data can be binary and the dataset may become sparse. This makes density-focused metrics like cosine similarity ineffective and costly to compute.
As you can tell measuring something as clicked on the movie using a continuous range is not possible. TikTok’s recommendation engine for example relies on sparse features.
For cases like these, a different similarity metric may be used called Jaccard Similarity. Let’s see it in action, picture our features as geometric shapes:
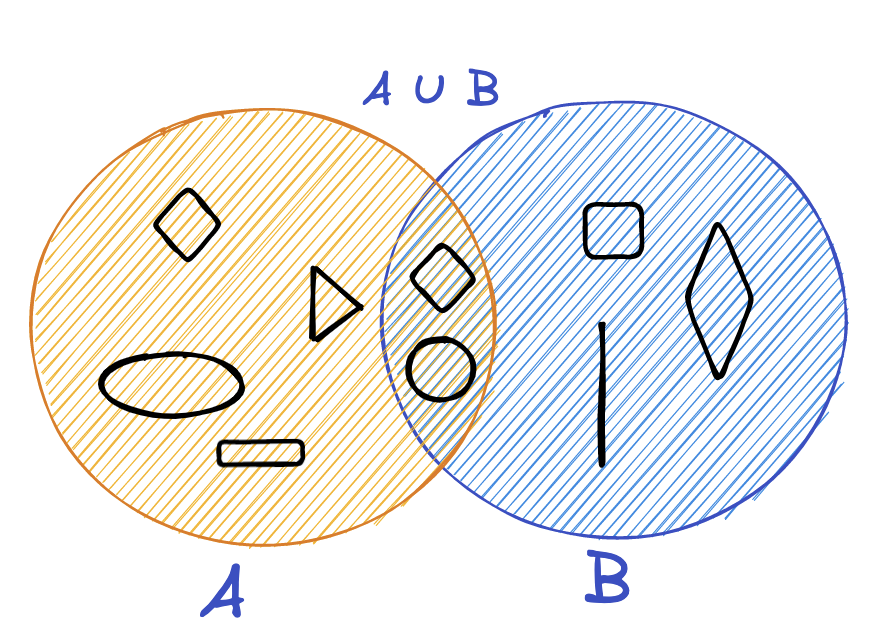
We can use union operation to find similarity between two items like so:
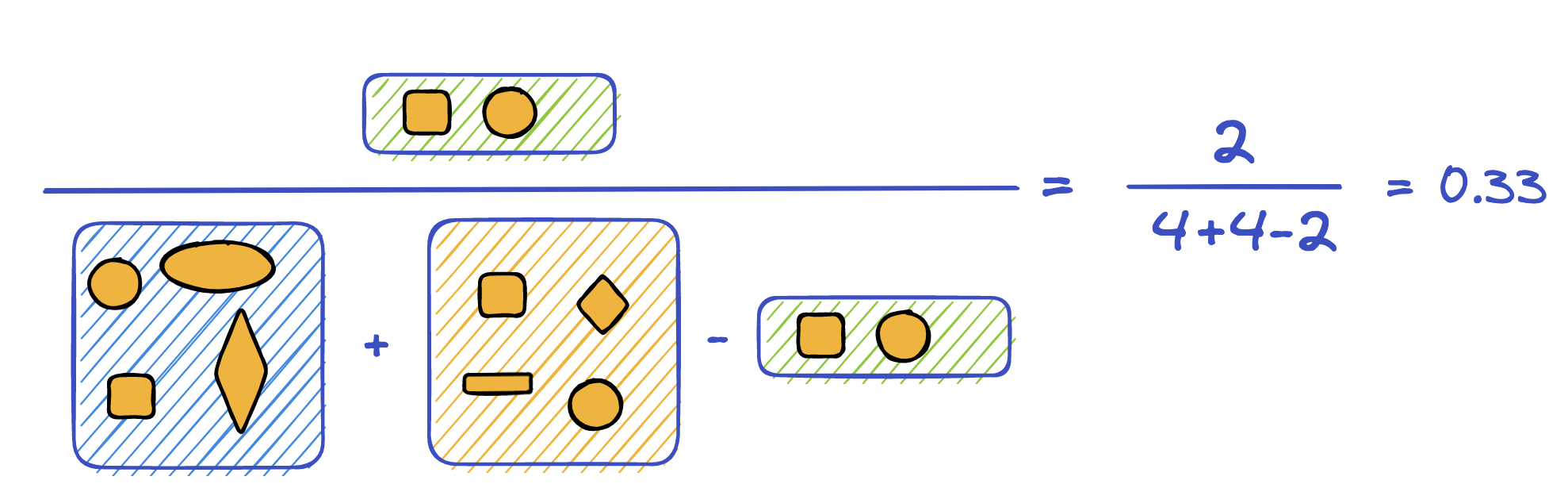
💡 The alchemy of features is real! In practice, different sets of components of your product may give you both continuous and categorical variables as user feedback. So in real-world applications, a combination of different scores is used to accurately determine similarities between items, items in combination are often weighted.
Handling tricky cases
The novelty of a recommended item may be calculated based on its similarity to previously recommended items, such that items that are dissimilar to past recommendations are considered more novel:
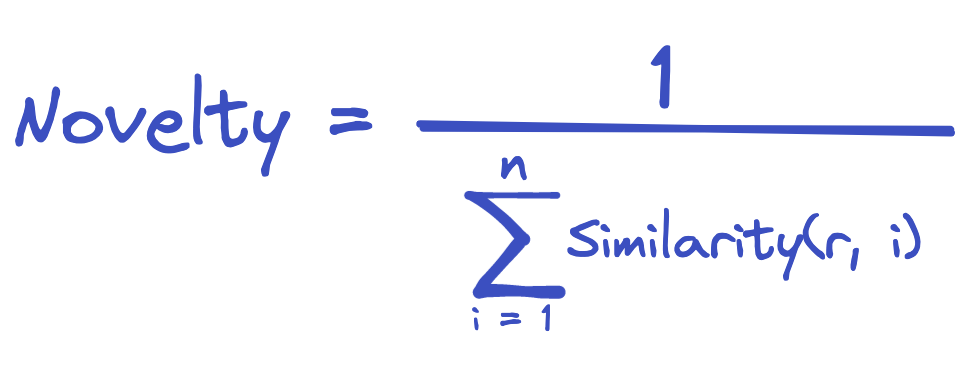
Where r is recommended item and i is each previously recommended item.
💡 This approach is not as common as using popularity-based methods to calculate novelty, as it relies on user-specific information and is much more complex to implement in practice.
Popularity-based methods are often preferred in recommendation systems because they are simple and easy to implement, and they do not require any information about individual users and their preferences, making them particularly useful for cold-start situations where little or no user data is available.
Moreover, popularity-based methods can often provide good recommendations for popular items that are likely to be of interest to many users, while also ensuring diversity in the recommended items, being particularly useful in scenarios where the goal is to provide recommendations that are likely to be widely accepted and generate high overall satisfaction among users.
Two common ways of defining it are:


But what if the item in question is already trending and was interacted with by all users, say most users on Netflix already got recommended Squid Game, can it still be considered novel? What if a year has passed? One better approach could be to consider user interaction instead, e.g. if the user clicked to watch for example:

Novelty is of the essence
So why even use novelty? There are 3 main reasons:
- Firstly, in a world where we are constantly inundated with information and options, the ability to discover new and interesting items can be a valuable feature for users. Recommending only items that are similar to ones the user has already interacted with may not provide the user with a diverse and interesting set of options to explore.
- Secondly, recommending only popular or well-known items may lead to a phenomenon known as “filter bubbles,” where users are only exposed to a narrow range of content and perspectives. This can limit their ability to discover new and diverse viewpoints and experiences. By incorporating novelty into recommendation systems, we can help users break out of their filter bubbles and explore a wider range of content.
- Finally, from a business perspective, incorporating novelty into recommendation systems can help to increase user engagement and satisfaction. Users who are constantly discovering new and interesting items are more likely to continue using the recommendation system and may even become loyal customers.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.