
For years, the workhorse of industrial-scale candidate retrieval has been the two-tower model. It’s efficient, scalable, and well-understood. However, the academic world has been buzzing with the promise of generative retrieval, where transformer-based models don’t just find the nearest embedding but generate representations of ideal candidates autoregressively. While these models show impressive performance on benchmarks , a significant gap has remained between academic promise and industrial reality. The challenges are formidable: high computational cost, slow sequential generation, and a lack of flexibility to align with diverse and evolving business metrics.
A new paper from Pinterest, “PinRec: Outcome-Conditioned, Multi-Token Generative Retrieval for Industry-Scale Recommendation Systems” (Badrinath, Agarwal, Bhasin et al., arXiv:2504.10507v2), marks a significant milestone in bridging this gap. It presents, to our knowledge, the first rigorous, public study of implementing a generative retrieval system at Pinterest’s massive scale. PinRec isn’t just a scaled-up academic model; it introduces two core innovations designed specifically to solve the practical challenges of production deployment: outcome-conditioned generation for controllability and windowed multi-token generation for efficiency and improved performance.
Generative Retrieval’s Industrial Hurdles
Traditional two-tower models compute query and item embeddings separately and retrieve based on similarity (e.g., dot product). They are fast because the item embeddings can be pre-computed and indexed. Generative retrieval, conversely, uses a sequence model (like a GPT variant) to process a user’s history and autoregressively generate a sequence of output representations for recommended items. This approach is powerful, it can capture complex user dynamics and generate novel candidates beyond simple similarity, but it comes with heavy baggage:
- High Latency & Cost: Autoregressive generation (one token at a time) is inherently slower and more computationally expensive than a single forward pass through a two-tower model.
- Lack of Controllability: A standard generative model optimizes for a single objective, typically next-item prediction. In a real-world system like Pinterest, business needs are multifaceted. One might want to optimize for high-effort “Saves” for core users but show more exploratory “Clicks” for new users. A standard generative model offers no simple lever for this.
- Inefficient Candidate Generation: Generating a diverse slate of hundreds of candidates one-by-one is impractical.
PinRec was designed to systematically address these three challenges.
Enter PinRec
PinRec is a transformer-based (specifically, GPT-2 architecture) generative retrieval system. Instead of simply scaling a base model, the Pinterest team introduced two clever mechanisms tailored for production RecSys.
1. Outcome-Conditioned Generation: Steering Recommendations
This is arguably the most impactful innovation for business alignment. The standard “next-token prediction” objective reinforces existing user behavior. If a user tends to perform low-effort clicks, the model learns to recommend more items that elicit clicks. PinRec introduces a mechanism to steer the model’s output towards desired outcomes.
- How it works: They introduce a set of learnable embeddings for each possible user action (e.g., repin, grid_click, outbound_click). The model’s output head is conditioned not just on the user’s history but also on one of these desired outcome embeddings.
- Training: During training, they can’t force a desired outcome on historical data. So, they condition the model on the actual outcome that occurred for the target item. For example, to predict item it+1, the output head is conditioned on the embedding for action(it+1).
- Inference (The Magic): During live serving, the game changes. The engineers can now specify the desired outcomes. They define a “budget” B that maps each action to a proportion (e.g.,
{repin: 0.6, grid_click: 0.4}). The model then generates B(repin) * N recommendations conditioned on the “repin” outcome and B(grid_click) * N recommendations conditioned on the “grid click” outcome. This gives them a direct, controllable lever to balance the types of engagement they want to drive, aligning the model’s output with high-level business strategy.
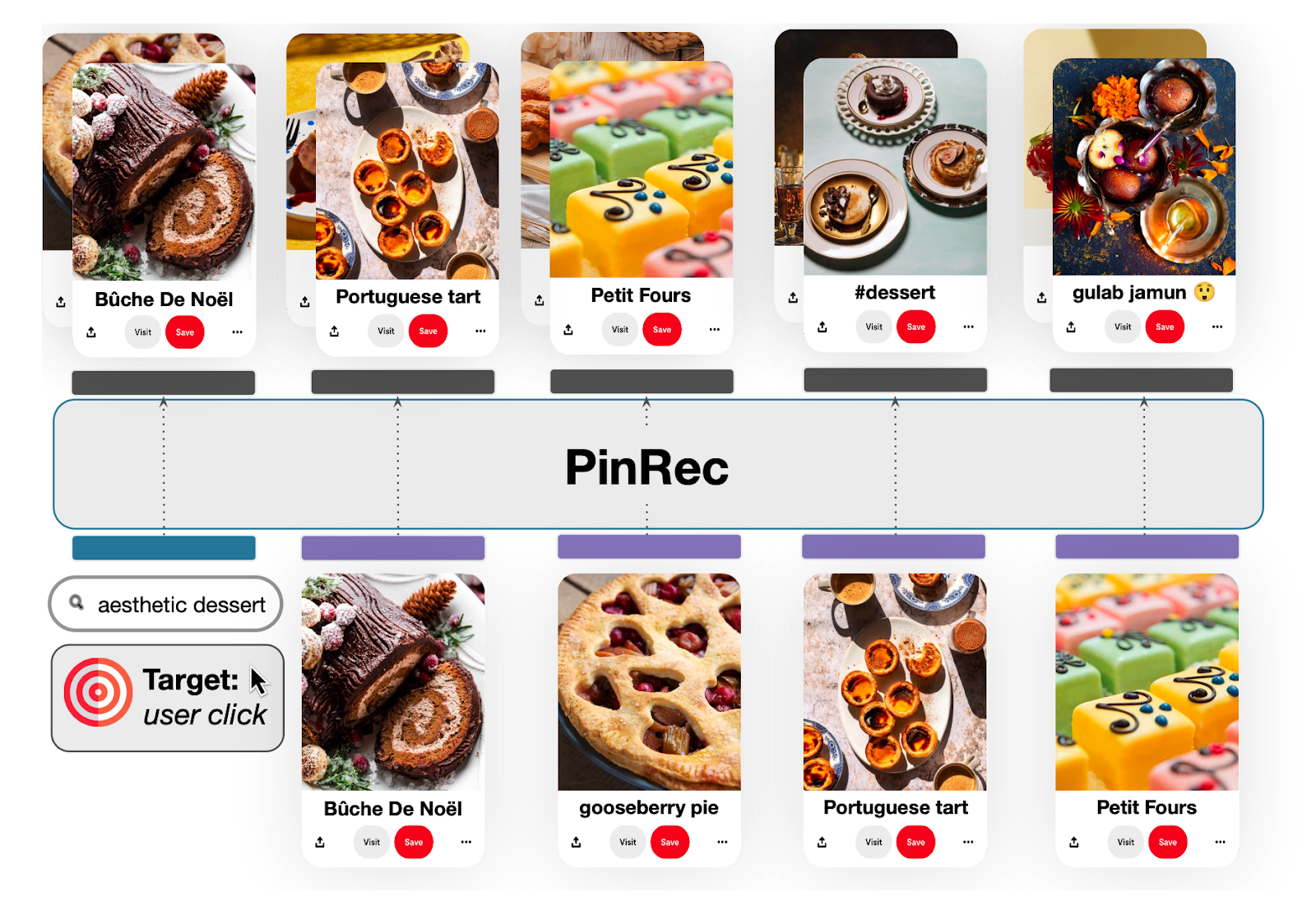 Figure 1: Illustration of PinRec, a generative item retrieval technique for heterogeneous user journeys on Pinterest.Sequences of user searches, engagements, and outcome-conditioning (bottom) are used to recommend Pins (top).
Figure 1: Illustration of PinRec, a generative item retrieval technique for heterogeneous user journeys on Pinterest.Sequences of user searches, engagements, and outcome-conditioning (bottom) are used to recommend Pins (top).
2. Windowed, Multi-Token Generation: For Efficiency and Relevance
The second key idea tackles the inefficiency of standard next-token prediction and its mismatch with how users interact with feeds.
- The Problem with Strict Next-Token: On platforms like Pinterest, user engagement isn’t always strictly sequential. A user might scroll past an item, engage with something else, and then scroll back up to engage with the first item. A rigid next-token objective penalizes the model for not predicting that item at the exact next step.
- Windowed Prediction: PinRec’s solution is to relax this assumption. Instead of predicting the item at t+1, the objective is to predict an item that the user will engage with within a future time window of size Δ (e.g., any item between t’ and t’ + Δ). This is captured by their L_mt objective (Equation 5), which seeks to find the minimum loss against any target in the future window. This is more aligned with real user behavior on feeds.
- Multi-Token Generation: To combat latency, PinRec generates multiple output embeddings in a single autoregressive step. Instead of one step per candidate, they can generate, for example, 16 candidates in one step. This dramatically reduces the number of sequential generation steps required to populate a full slate of recommendations, directly addressing the latency problem of generative retrieval.
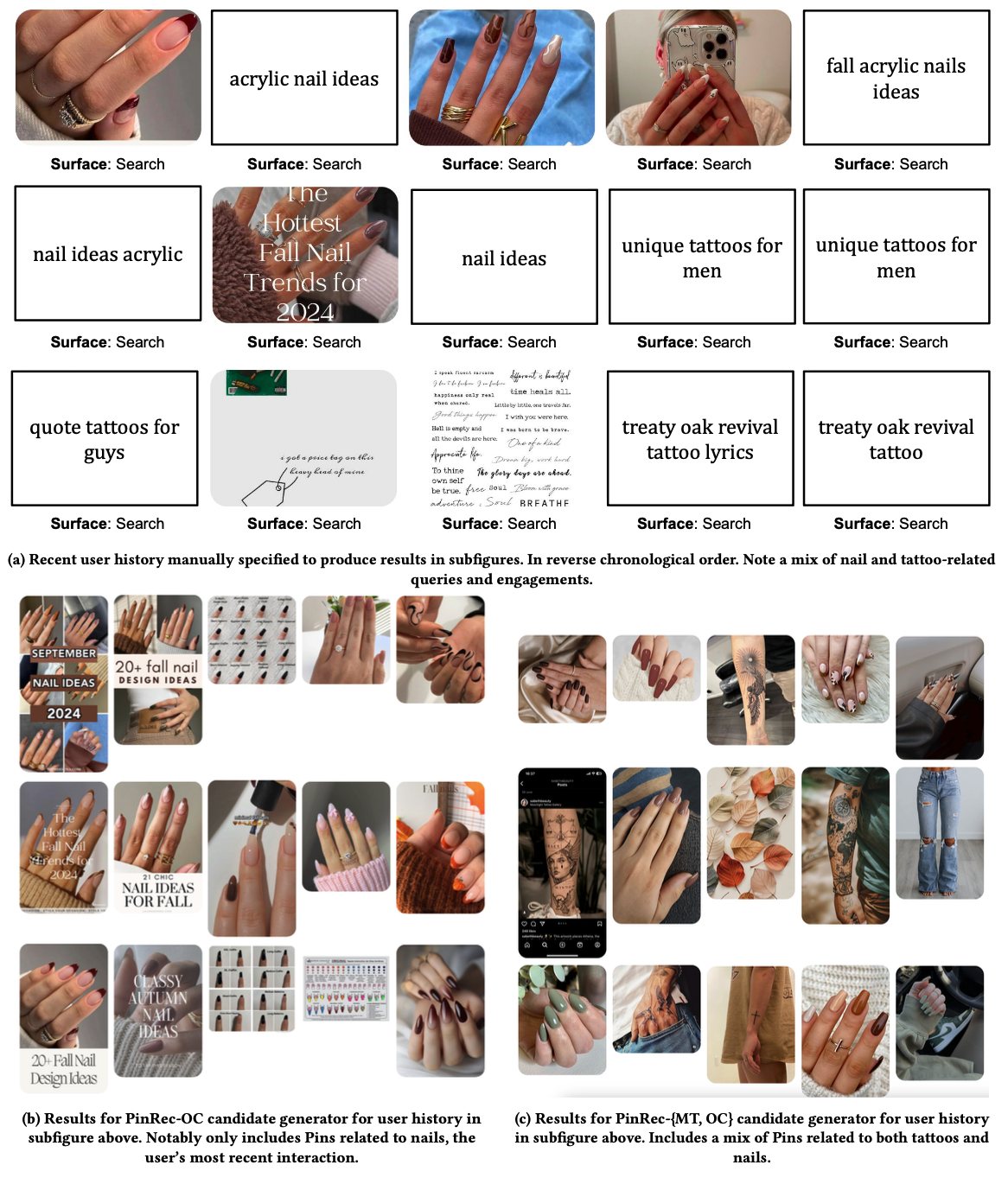 Figure 8: Comparison of results for a manually-specified user history.
Figure 8: Comparison of results for a manually-specified user history.
Production-Ready Engineering
A great model is useless if it can’t be served efficiently. The paper provides valuable details on their production infrastructure.
-
Model & Embeddings: They use an in-house, optimized implementation of GPT-2. Critically, they opt for real-valued vector representations for items, arguing that recent work has shown discrete semantic IDs can suffer from representational collapse.
-
Serving Pipeline: PinRec is served using NVIDIA Triton Inference Server. The system follows a Lambda architecture for signal processing:
- Signal Fetching: A daily Spark pipeline processes historical data, while a RocksDB key-value store provides low-latency access to real-time user engagements since the last batch run.
- Featurization: Pins are featurized using learned ID embeddings from massive, sharded tables (a separate service), while queries use representations from OmniSearchSage. Embeddings are quantized to INT8 for transport and de-quantized to FP16 for inference.
- Autoregressive Generation: The core PinRec model performs autoregressive inference, leveraging optimizations like KV Cache and compiling components with torch.compile via CUDA Graphs to minimize kernel launch overhead.
- Retrieval: The generated embeddings are used to query a Faiss IVF-HNSW index to retrieve the final set of candidate Pins. They also employ a clever “compression” step where very similar generated embeddings are merged before the Faiss lookup to reduce redundant retrievals.
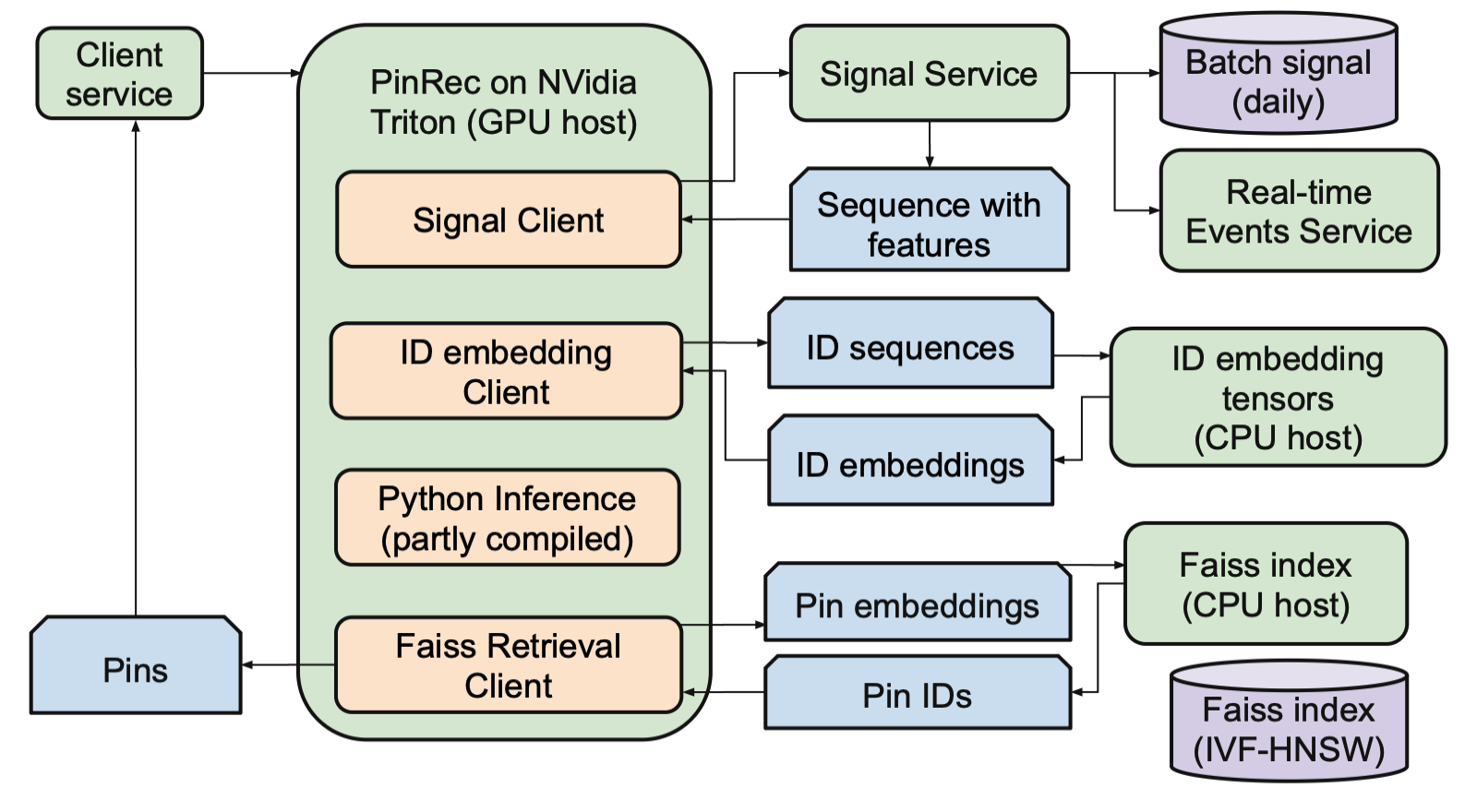 Figure 2: Serving flow for PinRec system (green boxes rep-resent services, blue rectangles represent transmitted data, purple cylinders represent indexed data, and beige boxes are steps within the PinRec Nvidia Triton ensemble).
Figure 2: Serving flow for PinRec system (green boxes rep-resent services, blue rectangles represent transmitted data, purple cylinders represent indexed data, and beige boxes are steps within the PinRec Nvidia Triton ensemble).
Does PinRec Deliver?
The paper presents a comprehensive suite of offline and online evaluations.
-
Offline Results:
-
Using an “unordered recall @ 10” metric (which better reflects feed dynamics than standard recall), the full PinRec-
{MT, OC}(Multi-Token, Outcome-Conditioned) model shows massive improvements over strong baselines. -
On Homefeed, it achieves a +10% lift over their own unconditioned generative model (PinRec-UC) and a +46% lift over PinnerFormer, their previous state-of-the-art sequence model.
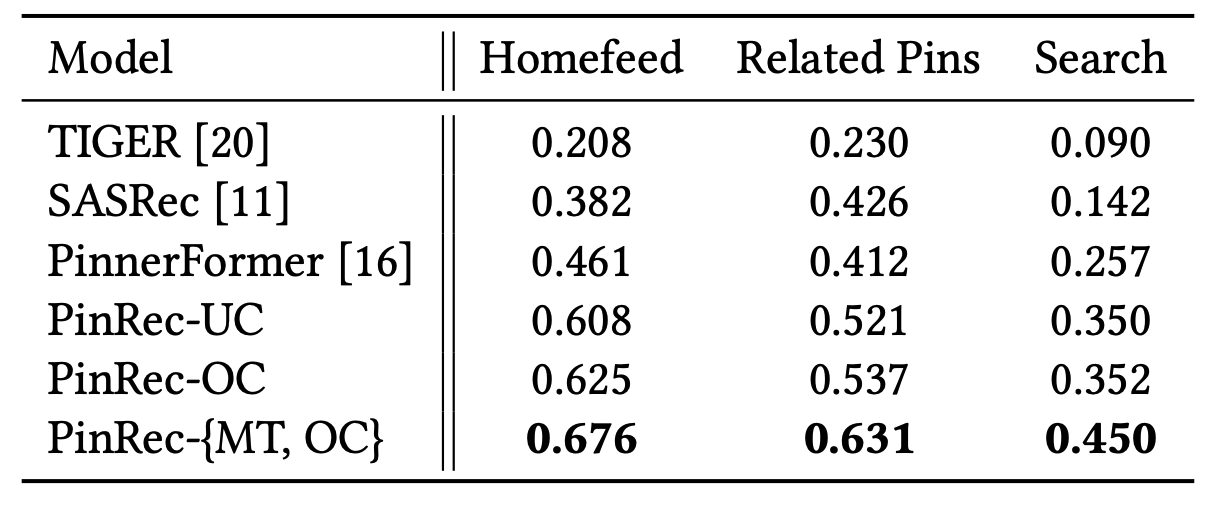 Table 1: Comparison of baselines and PinRec variants (un-ordered recall @ 10) across major surfaces at Pinterest.
Table 1: Comparison of baselines and PinRec variants (un-ordered recall @ 10) across major surfaces at Pinterest.
- Controllability: Figure 4 clearly demonstrates that conditioning on a specific action (e.g., “repin”) significantly boosts the recall for items that were actually repinned (+1.9%) while decreasing recall for other action types, proving the effectiveness of the outcome-conditioning lever.
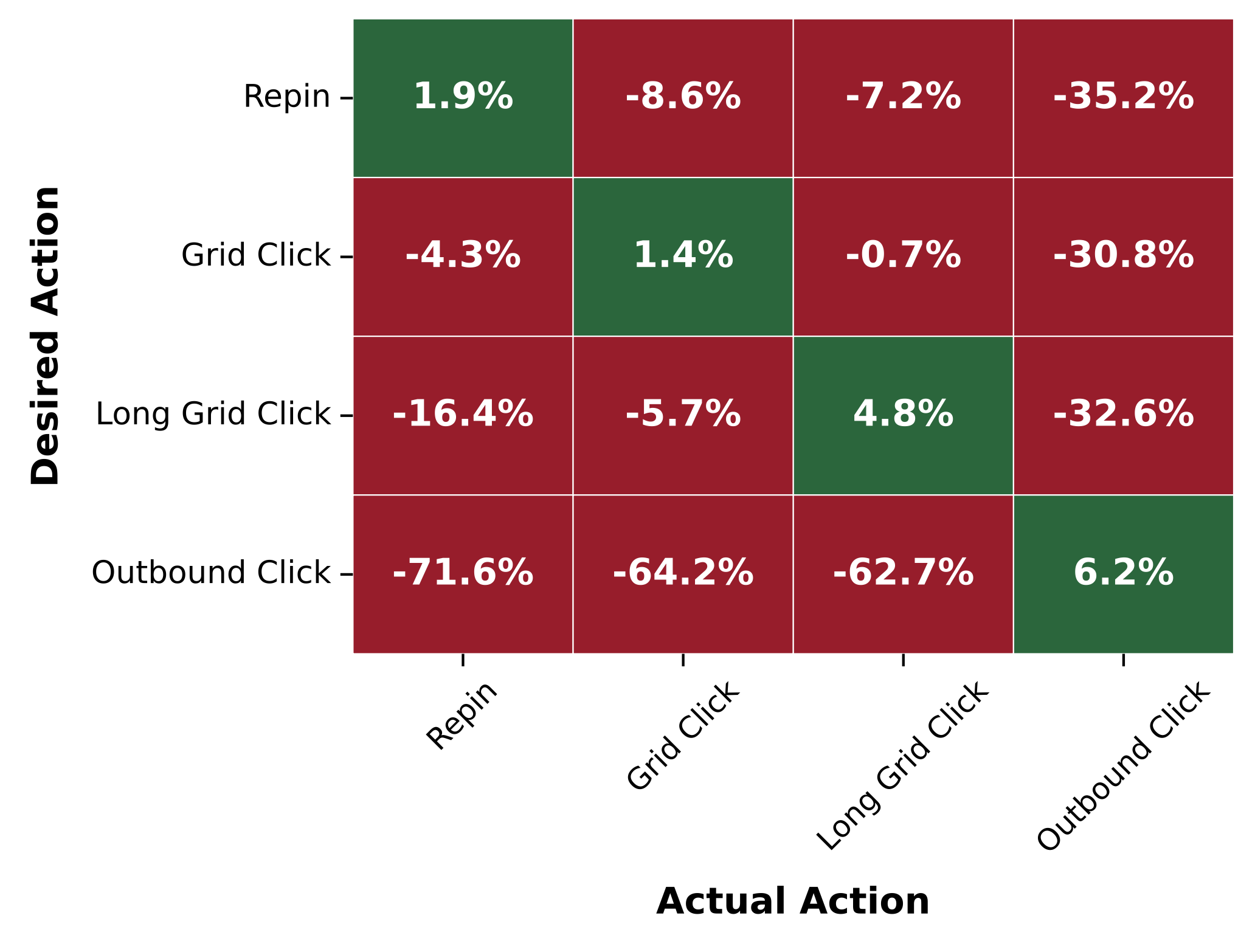 Figure 4: Percentage lift in unordered recall for PinRec-OCover PinRec-UC when conditioning on the desired action, stratified by the actual action taken by the user.
Figure 4: Percentage lift in unordered recall for PinRec-OCover PinRec-UC when conditioning on the desired action, stratified by the actual action taken by the user.
-
Online A/B Experiments: This is the ground truth. Pinterest ran extensive A/B tests on Homefeed and Search surfaces.
-
The full PinRec-
{MT, OC}model on Homefeed delivered statistically significant, CUPED-adjusted lifts:- +0.28% in Fulfilled Sessions
- +0.55% in Time Spent
- +4.01% in Homefeed Grid Clicks
-
Even the simpler unconditioned model (PinRec-UC) showed a +0.48% lift in Search Fulfillment Rate.
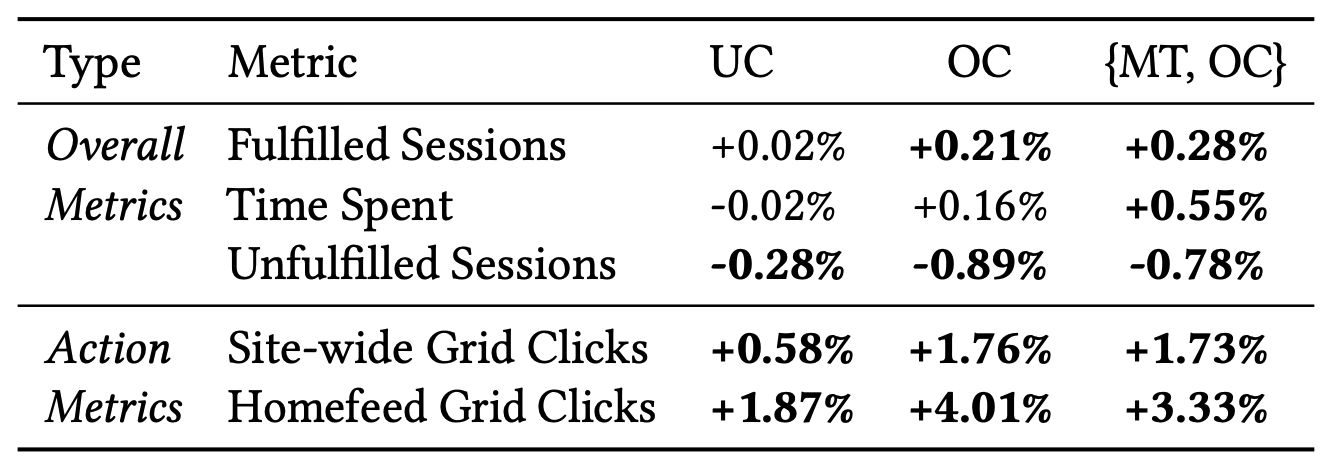 Table 2: CUPED-adjusted metrics improvements from onlineA/B experiments for PinRec variants as candidate generatorsi n Homefeed.
Table 2: CUPED-adjusted metrics improvements from onlineA/B experiments for PinRec variants as candidate generatorsi n Homefeed.
 Table 3: CUPED-adjusted metrics improvements from onlineA/B experiments for PinRec as candidate generator in Search retrieval.
Table 3: CUPED-adjusted metrics improvements from onlineA/B experiments for PinRec as candidate generator in Search retrieval.
- The Pareto front visualizations (Figures 6 & 7) further confirm online controllability, showing that as they adjust the budget for “repins” vs. “grid clicks,” the actual online event rates shift accordingly.
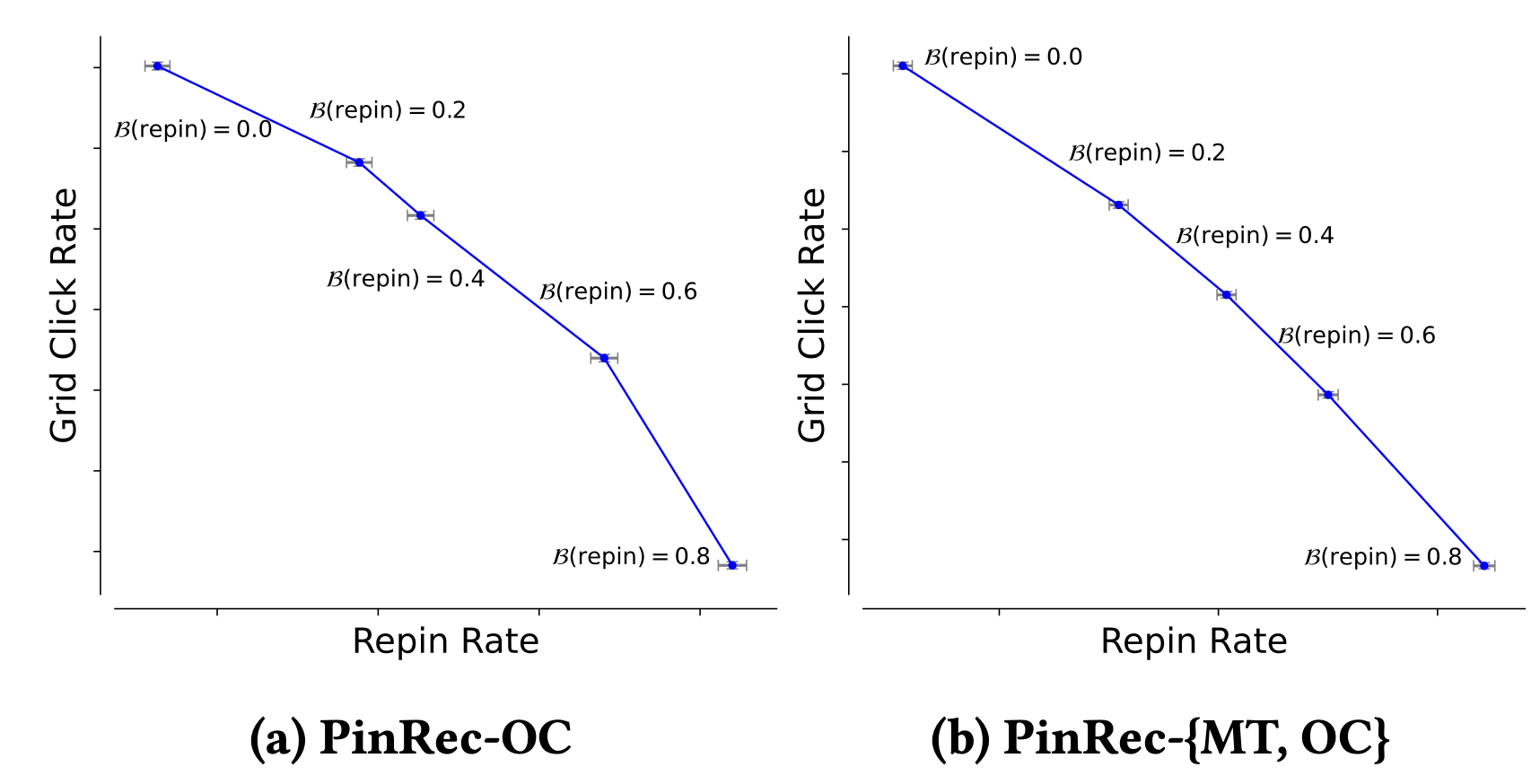 Figure 6: Visualization of Pareto fronts for online rate of gridclick versus repin for items recommended only by PinRec variants, with error bars denoted in grey.
Figure 6: Visualization of Pareto fronts for online rate of gridclick versus repin for items recommended only by PinRec variants, with error bars denoted in grey.
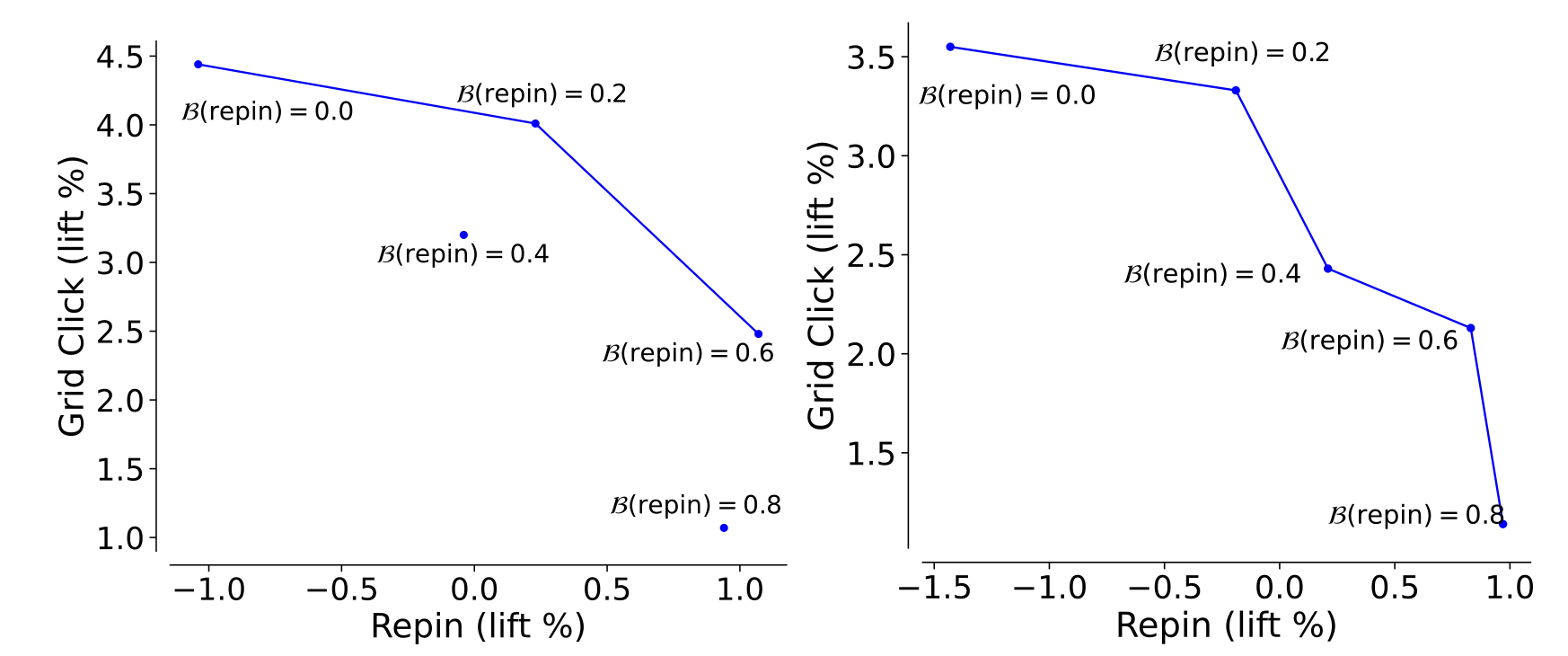 Figure 7: Visualization of Pareto fronts for online lift % in Homefeed grid clicks versus repin for PinRec variants.
Figure 7: Visualization of Pareto fronts for online lift % in Homefeed grid clicks versus repin for PinRec variants.
Takeaways
The PinRec paper is more than just an engineering report; it provides a blueprint for the next generation of industrial recommendation systems.
- Generative Retrieval is Production-Ready: Pinterest has shown that the key challenges of latency, cost, and control can be overcome with targeted innovations.
- Controllability is the New Frontier: Moving beyond single-objective optimization is critical. Outcome-conditioning provides a powerful and intuitive mechanism to align models directly with multifaceted business strategies.
- Model and System Co-design is Essential: The success of PinRec isn’t just the model; it’s the tight integration with an efficient serving stack (Triton, Faiss, RocksDB) and clever optimizations (KV Cache, embedding compression).
- A Path Away from Two-Towers: While two-tower models will remain relevant, PinRec demonstrates a viable, high-performing alternative that offers greater expressiveness and control, particularly for platforms with rich user sequences.
This work from Pinterest effectively lays out a new state-of-the-art for large-scale generative retrieval. It shows how to build a system that is not only powerful in its recommendations but also flexible and steerable, a crucial requirement for any modern, dynamic platform.
Is this the beginning of the end for the two-tower’s dominance in large-scale retrieval, or are the engineering overheads still too high for most?
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.