Among all the recent hype regarding OpenAI’s ChatGPT, a few prominent industry players in AI are getting ready to release their new fantastic generative models. If ChatGPT is well suited for tackling text, the team at Google AI decided to go further and create a model capable of generating sound, in the new paper titled AudioLM: a Language Modeling Approach to Audio Generation, presents a new framework for generating high-quality sound, ranging from different kinds of human speech to musical instruments from sound alone. Unlike previous approaches, the team found a way to not use text transcription or MIDI representations for the piano.
Generating realistic audio is a complex task that involves modeling information at different scales. Just as music combines individual notes to create complex melodies, speech uses phonemes and syllables to form words and sentences. Music is challenging as well, as not only the appropriate notes are required, but to generate new pieces, the model would need to keep the pace and style intact. Both of these tasks increase in complexity if we want to generate something natural and of high quality.
Sound in fact is sometimes considered a more challenging task compared to text and we will see why soon. This, however, didn’t stop the team at Google from achieving a new milestone with their AudioLM model. In this post, we will dive into key ideas that power AudioLM, explain why and how they are important, and divine the potential impact of this new innovation for the future of AI.
Why is creating sound hard?
Sound at its core is one of the essential ways for us to experience the world. From the myriad of languages, we use to communicate to music to figure out what is wrong with your old car’s engine. The physical properties of sound as a wave are a double-edged sword, on one hand, our knowledge of signal processing is what allows us to model it but the complexities of working with signals are also what makes it so challenging.
Audio signals are complex, multi-layered entities that can consist of speech, music, or environmental sounds. Analyzing audio signals requires an understanding of multiple scales of abstractions. For example, speech can be analyzed at a local level, such as acoustic or phonetic analysis, as well as at a higher level, including prosody, syntax, grammar, and semantics. Similarly, music has a long-term structure but is composed of non-stationary acoustic signals that can be challenging to synthesize.
In the field of audio synthesis, achieving high audio quality while maintaining high-level consistency remains a significant challenge, especially in the absence of strong supervision. Recent audio synthesis models have made remarkable progress by using techniques such as autoregressive waveform modeling, adversarial training, and diffusion, resulting in nearly veridical signal quality. However, these models often require strong conditioning, such as linguistic features or a MIDI sequence, to generate structured audio. Without such conditioning, even powerful models like WaveNet can generate incoherent and messy audio.
The secret recipe of AudioLM
AudioLM solves this by using audio-only information. To achieve this they used 2 following innovations:
- Smart Tokenization
- Mixed architecture
Smart Tokenization
All language models that utilize transformers rely on tokenization, which is a method of encoding text and speech into tokens are usually words or subwords that are separated by spaces or other punctuation marks. The purpose of tokenization is to transform the text into a format that can be easily processed by machine learning algorithms.
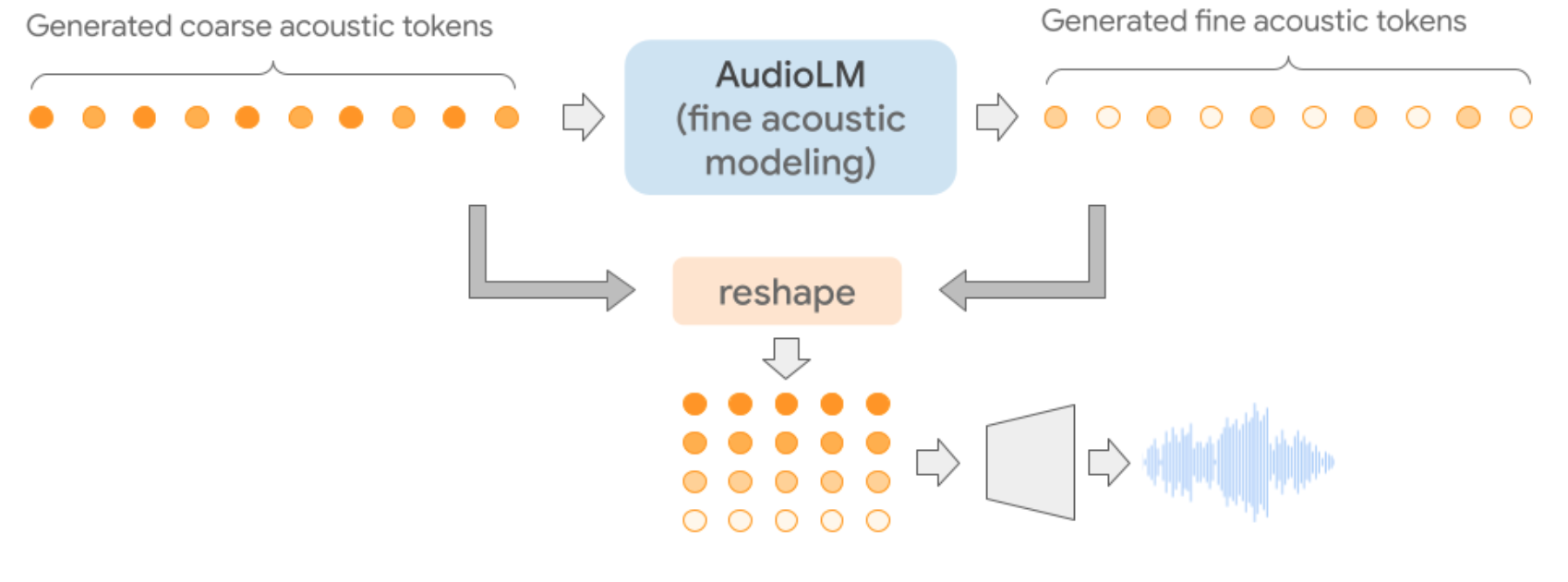
It is crucial to have quality tokenization as this allows the model to gain an accurate representation and understanding of complex audio waves. To reach the goal of learning from audio alone Google AI team sent the sample audio to two tokenizers. SoundStream (also developed by Google AI) performed acoustic tokenization, in Figure 1 to get the tokens, they extracted latent vectors from the compressed embedding space, these tokens carry the information about the acoustic properties of our chosen audio sample, like pitch, intonation, etc.
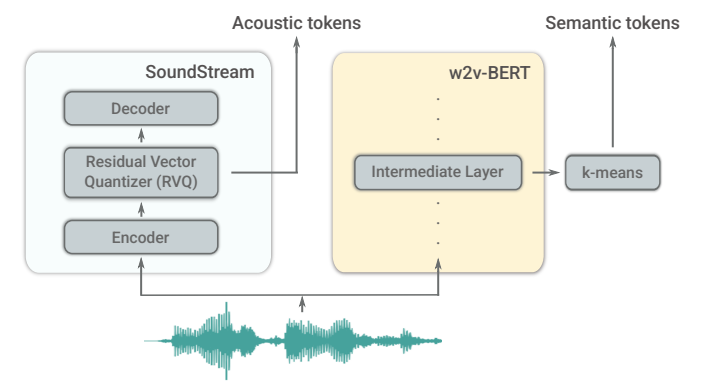 Figure 1: Overview of the tokenizers used in AudioLM. The acoustic tokens are produced bySoundStreamand enable high-quality audio synthesis. The semantic tokens are derived from representations produced by an intermediate layer of thew2v-BERTmodel and enable long-term structural coherence.
Figure 1: Overview of the tokenizers used in AudioLM. The acoustic tokens are produced bySoundStreamand enable high-quality audio synthesis. The semantic tokens are derived from representations produced by an intermediate layer of thew2v-BERTmodel and enable long-term structural coherence.
But as they discovered, straight acoustic information without any meaning behind it doesn’t work well for generating new audio. Here are a few examples of reconstructed sound using acoustic tokens only:
Reconstruction
So if the meaning of audio or semantic information is required how do we get it? To do this we need to utilize a model that can parse audio into words. For this task researchers used a pretrained w2v-BERT model, specifically they were interested in the encoding of the audio data that carry semantic information.
💡 Key Idea 1:
We need only a semantic representation of audio, not the deconstructed text. This means what we get from intermediate layers is more of a representation of relationships between different sounds, and their ordering, which sounds naturally sound appropriate together, rather than words.
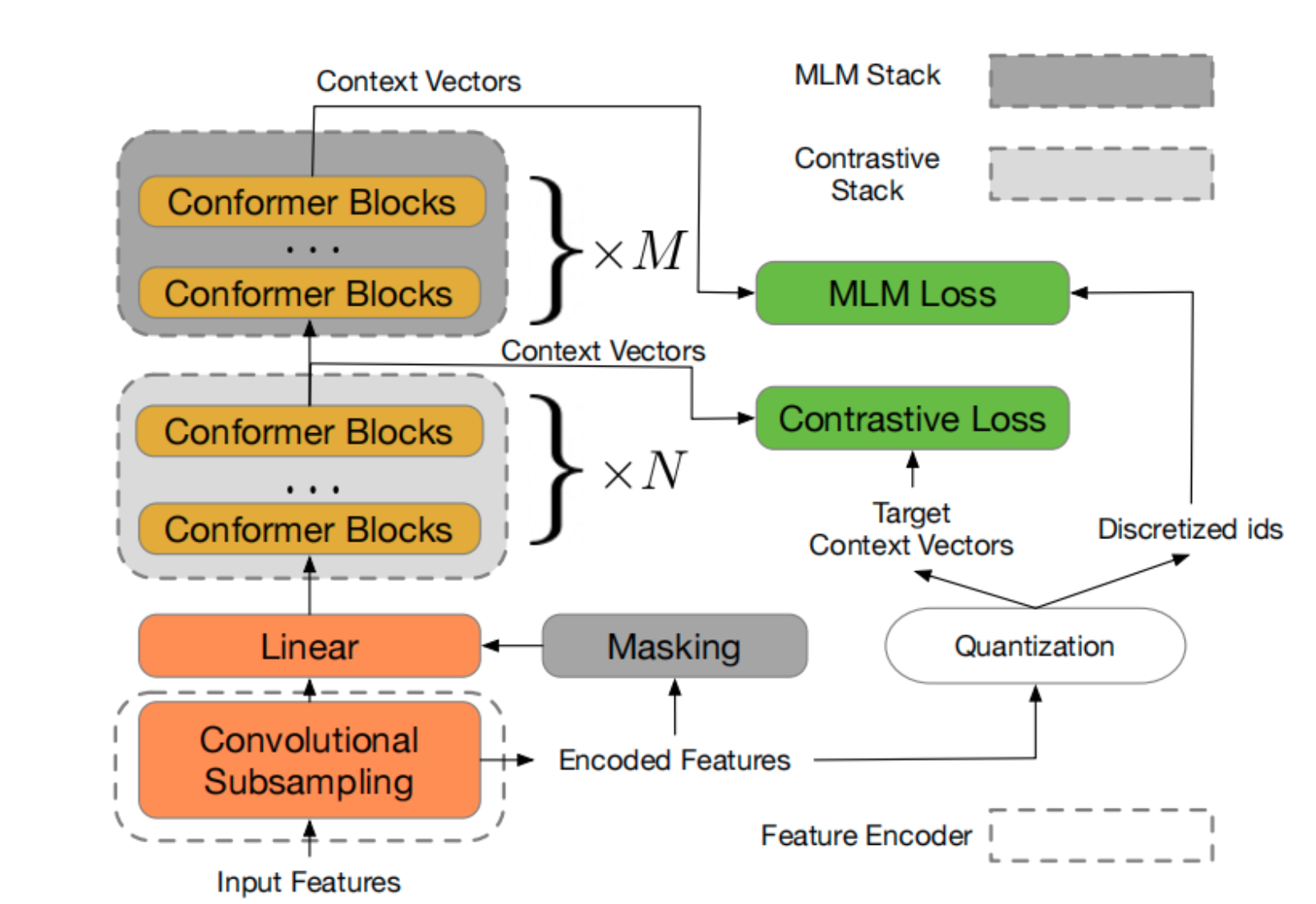 Figure 2: w2v-BERT architecture. Two important components are conformer blocks and an MLM block, from which intermediate representation is computed. K-Means is then used to cluster the embeddings and centroids are used as tokens.
Figure 2: w2v-BERT architecture. Two important components are conformer blocks and an MLM block, from which intermediate representation is computed. K-Means is then used to cluster the embeddings and centroids are used as tokens.
Your next question, however, might be: okay, speech is fine and well but how do you capture the semantic information of a piano piece? And the answer is: in the same way. Since we don’t need the actual text, we can use the power of w2v-BERT to add additional structural information about our sound sample.
Mixed architecture
AudioLM’s architecture is the following:
- A tokenizer model, which maps x into a sequence of discrete tokens from a finite vocabulary
- A decoder-only Transformer language model that operates on the discrete tokens, performs 3 different types of acoustic modeling (Figure 3)
- A detokenizer model, which maps the sequence of predicted tokens back to audio
The most interesting component is the Transformer model, which contains 3 stages that increase audio quality, researchers found that using a single tokenization scheme doesn’t achieve good results, therefore AudioLM does audio modeling using 3 stages illustrated in Figure 3.
💡 Key Idea 2:
SoundSream has a residual structure, the further the residual quantizer is the finer the acoustic representation. This concept is used to get coarse and fine acoustic tokens, the main difference is how far in the layers the representation is extracted (note Figure 3)
 Figure 3: 3 levels of tokenization. 1) Semantic tokens from w2v-BERT; 2) A combination of semantic tokens and coarse acoustic representation extracted early in the layers of SoundStream; 3) Addition of fine acoustic tokens
Figure 3: 3 levels of tokenization. 1) Semantic tokens from w2v-BERT; 2) A combination of semantic tokens and coarse acoustic representation extracted early in the layers of SoundStream; 3) Addition of fine acoustic tokens
AudioLM’s results
To make sure that the tokenization process produces good quality representations of an audio sample, the researchers used three metrics: ABX, sWUGGY, and sBLIMP.
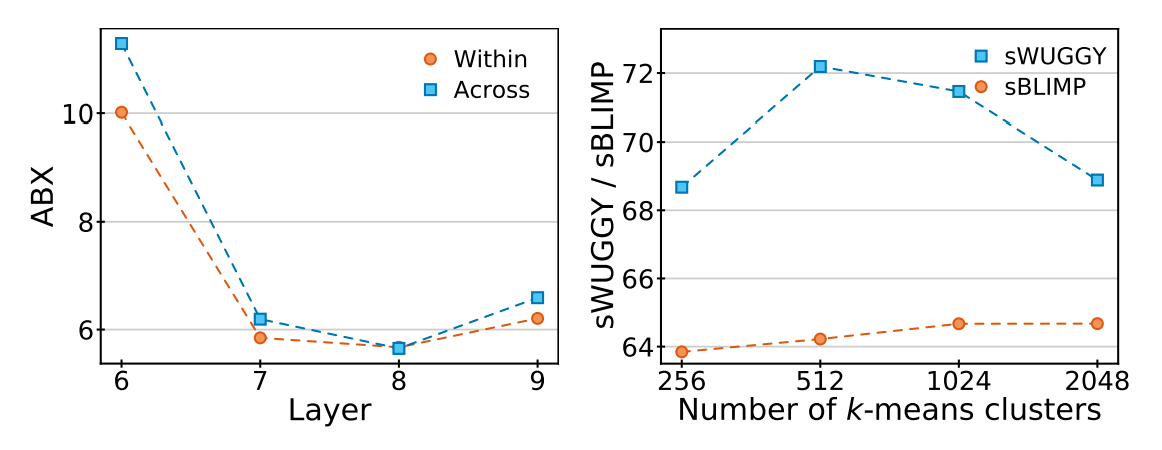 Left: ABX (↓) scores achieved by the (unquantized) embeddingsextracted from different layers of the MLM module of w2v-BERT. Right:Scores on the development sets of sWUGGY (↑) and sBLIMP (↑) obtainedwith different numbers of k-means cluster centers for layer 7
Left: ABX (↓) scores achieved by the (unquantized) embeddingsextracted from different layers of the MLM module of w2v-BERT. Right:Scores on the development sets of sWUGGY (↑) and sBLIMP (↑) obtainedwith different numbers of k-means cluster centers for layer 7
- ABX evaluation is used to evaluate the performance of different models in tasks such as speech recognition, text-to-speech synthesis, and machine translation.
- sWUGGY (short for “smoothed Word-Usage Goodness GOF”) measures the similarity between the word usage in the generated text and the word usage in a reference corpus. This metric is designed to penalize the use of uncommon or inappropriate words in the generated text.
- sBLIMP (short for “smoothed Bilingual Evaluation Understudy with Punctuation”) is a metric that compares the generated text to a reference text using a machine translation approach. It measures the quality of the generated text in terms of fluency, grammar, and meaning preservation, while also taking into account punctuation and word order.
This allowed researchers to select layer 7 as the most promising layer for extracting embeddings and k=1024 clusters for an amount of tokenization.
And now let’s hear some results!
Speech continuation
Original
Prompt
Continuation (AudioLM)
Continuation (AudioLM)
Piano continuation
Original
Prompt
Continuation (Acoustic-only model)
Continuation (AudioLM)
Looking into the future
AudioLM’s results are undoubtedly impressive, this milestone is a promising step in a direction of future potential research like multilingual speech generation, the generation of music using different instruments all at once, and producing quality informative audio content.
But the authors of the paper also acknowledge that this result doesn’t come without risks. AudiLM by the nature of its architecture also inherits all the problems of LLMs, there is no guarantee that the model will replicate dialects and accents well from the groups underrepresented in the training dataset. There can be societal biases coming from the generated audio content, and not to forget that short and coherent audio modulation gives rise to a risk of breaching the biometric identification, with that in mind researchers closed a paper with their tool to identify audio that was generated by AudiLM.
Reference
Borsos, Zalán, et al. “Audiolm: a language modeling approach to audio generation.” arXiv preprint arXiv:2209.03143 (2022) https://arxiv.org/pdf/2209.03143.pdf
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.