
In this post, we summarize the takeaways of each talk and provide some of our thoughts from Shaped.
Recs at Reasonable Scale
Jacopo Tagliabue, Director of AI at Coveo -Twitter
Here Jacopo provided a tutorialon how to build an end-to-end offline recommender system. Following his tutorial you could build a recommendation system with the following components from data ingestion to serving the predictions:
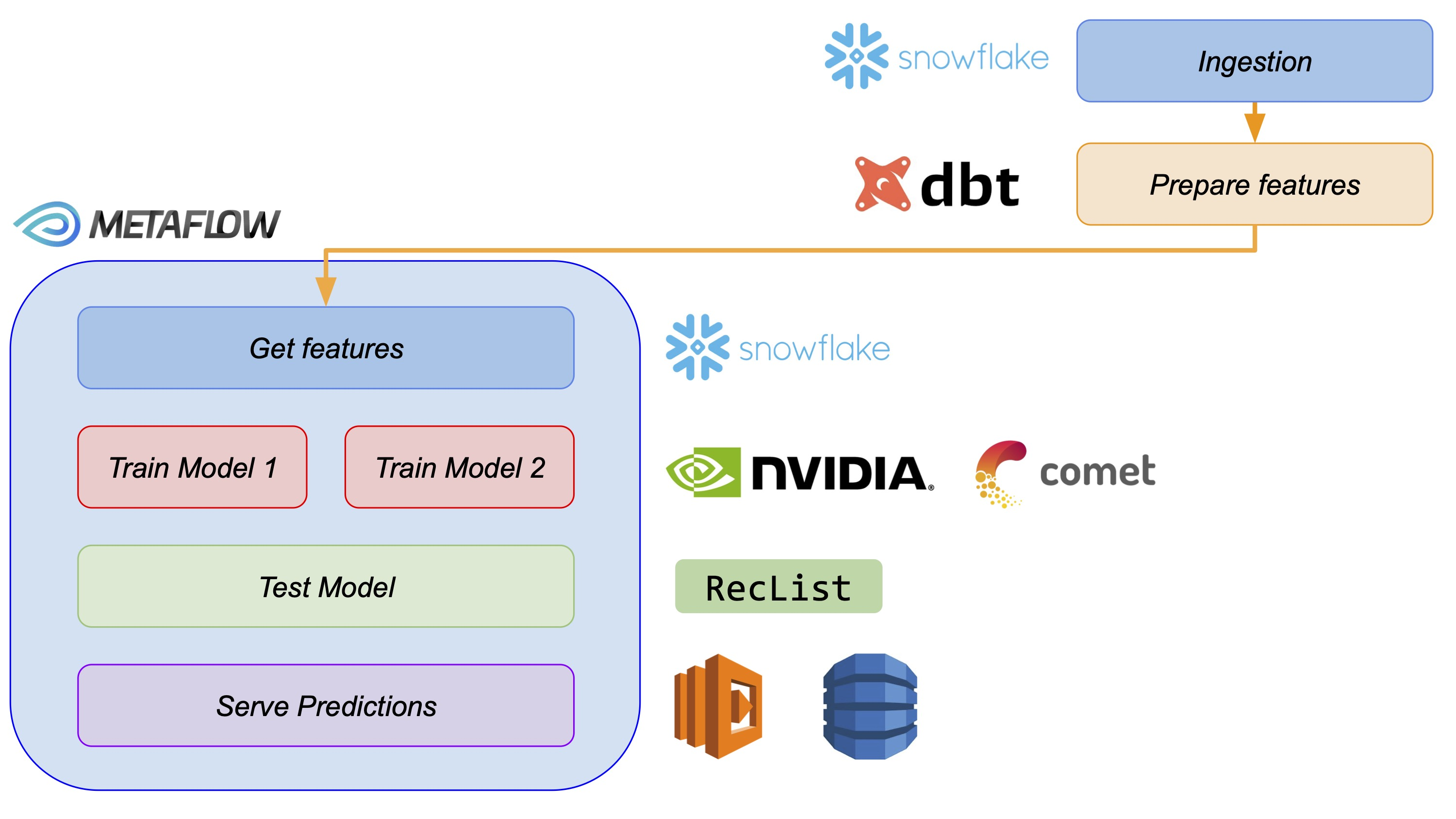
The content of the tutorial covered key components of a recommender system and was easy-to-follow. It gives an example of what the first iteration of a recommender system looks like at many companies (or even their final one). It covered everything from data ingestion to serving the model predictions with a cache. As an added bonus, the tutorial used the H&M fashion dataset, which was recently released at Kaggle.
Our infrastructure shares some core designs with the one seen in this tutorial. We support data ingestion from different data warehouses and create the necessary pipelines to give life to a recommender system.
While online serving is often ideal for recommender systems (often the fresher features are the more relevant recommendations are) the extra engineering complexity doesn’t always make it worth it. Serving recommendations from a cache is the right starting point.
Platform for Real-time Recsys
Chip Huyen, Co-Founder and CEO, Claypot AI -Twitter
In this talk Chip Huyen gave a superb introduction to the online serving side of recommender systems. If you read some of her content this presentation would be familiar to you with an added spin for recommendation use-cases.
It started with the first step on how to move a traditional offline system to online: computing features in time for the model. Session-based recommenders were also mentioned but not much on the differences in how their backend varies from a traditional ranking system.
Chip then moved to engineering challenges of serving recommendations online:
- Stateless vs stateful processing of features.
- Inconsistencies between train and predict data.
- Monitoring model performance, batch vs real-time.
- Monitoring data drifts: How does the training data change, what types of data shifts exist, or even when should a newer model be released to production.
- Monitoring features and model predictions to better help understand model performance and data drifts.
The presentation focused on the MLOps and engineering challenges of recommender systems, which are typically the bottleneck to bringing machine learning to production —particularly as models are becoming more general and self-serve. Perfect balance between complexity and key concepts at recommender systems.
Improving Long-term User Engagement with Push Notifications Using Model-based Reinforcement Learning
Jonathan J. Hunt, Staff Research Scientist - Twitter
Switching gears from the previous engineering and MLOps based talks, Jonathan talked about the specifics of a reinforcement learning based notification model they use at Twitter. His team created a model to better estimate when to filter Twitter notifications in their mobile app. The model comes in at the last stage of recommender systems, the predictions of what a user may like in their notifications are already computed, and it’s not time to decide whether to display them or not.
During his talk, he introduced the method behind his published work and explained how they leverage already existing data to prove the need for their model. They manage to create an uplift in user notification openings without having to collect the ideal data for their model.
We don’t see much work for reinforcement learning in production for recommender systems other than multi-arm bandits but Jonathan team’s work looks promising. This work shows how long-term engagement is becoming a huge priority now (especially in social media companies like Twitter) as short-term objectives can damage the lifetime value of users.
An Embarrassment of Riches; Trying to Find Harmony Among Several Different Models
Bryan Bischof, Head of Data Science, Weights & Biases -Twitter,Slides
Bryan gave a pragmatic talk on working with recommender systems on his learnings working at Stitch Fix, an online fashion company that provides tailored outfits for their customers.
He raised many points on working with recommenders and how they affected his work:
- The difference between recommending physical objects and digital objects. How they had to leverage stock and warehouses. This is something that large e-commerce companies like H&M, Zara and Zalando experience but rarely mention in their recsys content.
- The existence of different recommender cases (loss functions) in their business and how they leverage them. The dilemma between many specific models vs a big model to cover them all.
- Political or organizational biases influence their models. While most of the time is business knowledge that gives the edge performance to the recommender systems is easy to overstep and cause more damage.
- How to best evaluate new roll-outs and AB testing. He went through some of the mistakes they did and how they affected them.
He then explained on his current company Weights & Biases could help with the monitoring of some of those points. It was a very approachable talk and in contrast to other speakers that talked about “things to do” Bryan talked about “things not to do”.
RecSysOps: Best Practices for Operating a Large-Scale Recommender System
Ehsan Saberian, Senior Research Scientist, Netflix -Twitter
Netflix gave a very production-focus view on best practices recommender systems. Ehsan went through multiple experiences from his work and summarized a few best practices for the audience:
- Measure the usage of their service across other systems/teams. Reducing the gap between producer and consumer allowed his team to early detection of multiple bugs.
- Embrace communication with teams using their recommendations and create as many tools as they need to monitor the performance. If a team has a metric to track related to the recommendation system then add it to your monitoring services.
- Be reactive to your monitoring services, use it as a way to prioritize work as is a very tangible measurement of your system performance.
- Log everything! Not necessarily all the data but at least portions of every data source; something like 5% of the served predictions. This helped them debug issues while keeping logs size manageable.
The main point from Ehsan was monitoring, tracking what is important for the teams that consume recommendations, and having the necessary data to debug whatever issue appears. This is something that resonates with us at Shaped as we try to do the same in our systems.
Building an Open-Source Framework for Recommender Systems
Even Oldridge, Senior Engineering Manager for Recommender Systems, NVIDIA -Twitter
Even gave a summary of their journey building Merlin. He talked about how they first started with model experimentation, moving now towards model deployments, and how they plan to tackle monitoring and production maintenance.
One of the highlights they mentioned was the recent release of Merlin-system, which goes beyond the models and feature engineering tools they’ve released, and builds out a structure for deploying multi-stage recommendation systems in production.Even mentioned that most companies still take 6-months+ to deploy a recommendation system in production and ultimately their goal is to reduce that time.
At Shaped, we’ve been following the Merlin library development closely and are excited to start using several of their tools, particularly as we move more towards a GPU-first infrastructure.
Closing thoughts
Wonderful summit, good selection of speakers that brought real industry experience and presented diverse topics in the recommendation systems.
Recommender systems are becoming more popular in recent years with the vast amounts of data companies process nowadays. These systems provide personalized experiences to users and help businesses grow. Seeing how the field is growing and how different companies tackle these problems only reinforces our mission at Shaped to democratize recommender systems, providing top-class architectures and infrastructure to every developer/company.
Special thanks to Nvidia for organizing this summit and excited to see what they will bring to recsys2022.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.