
Denoising Self-Attentive Sequential Recommendation
Authors: Huiyuan Chen, Yusan Lin, Menghai Pan, Lan Wang, Chin-Chia Michael Yeh, Xiaoting Li, Yan Zheng, Fei Wang, Hao Yang
Lab: Visa Research
Link: https://dl.acm.org/doi/pdf/10.1145/3523227.3546788
First off, we have one of the best paper awards for the conference. This paper proposes the Rec-Denoiser model, a method that aims to mitigate problems with noisy historical interactions affecting recommendations (specifically for Transformer-based sequential models). For example, if you accidentally like a post that you’re not interested in, the recommendation model aims to adaptively ignore that noisy interaction.
Rec-Denoiser works by, simply, attaching a trainable binary mask that prunes noisy attentions from each of the Transformer’s self-attention layers, resulting in sparse and clean attention distributions. The novelty of the paper comes from how they adaptively learn the binary mask, given that it’s non-differentiable (i.e. the loss is discontinuous) and has large variance (i.e too many possible binary mask states). To overcome this they propose an efficient estimator that uses a variant of the augment-REINFORCE-merge (APM) [1] method to relax the optimization. Furthermore they add Jacobian regularization to enforce a local Lipschitz constraint to further improve robustness.
The experimental results demonstrate significant improvements that Rec-Denoiser brings to self-attentive recommenders (5.05% ∼ 19.55% performance gains), as well as its robustness against input perturbations.
[1] Mingzhang Yin and Mingyuan Zhou. 2019. ARM: Augment-REINFORCE-mergegradient for stochastic binary networks. In ICLR.
A Systematic Review and Replicability Study of BERT4Rec for Sequential Recommendation
Authors: Aleksandr Petrov, Craig Macdonald
Lab: University of Glasgow
Code: github.com/asash/bert4rec_repo
Link: https://arxiv.org/pdf/2207.07483.pdf
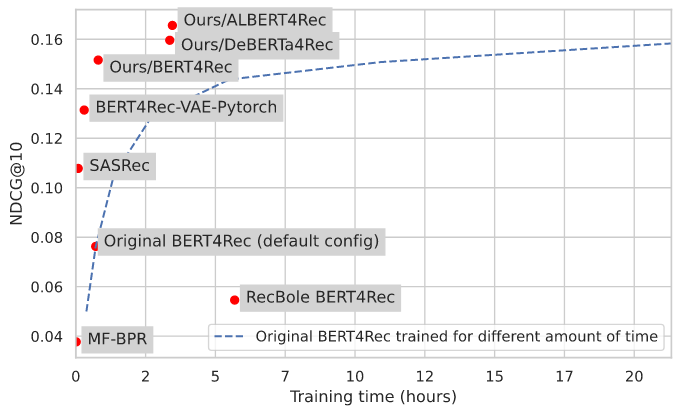
The authors noticed discrepancies in BERT4rec results when doing a literature review on Transformer sequential models. To get to the bottom of it, they systematically reviewed BERT4Rec and SASRec results across 370 papers that cite the original BERT4Rec paper. Their analysis found that there were 3 common BERT implementations, 2 of these had performance issues, and the original implementation’s default config was severely underfitting. The authors also wrote their own implementation of BERT4Rec using the HuggingFace Transformer library, and showed superior performance to the original implementation. They present their own results along with what they achieved by using the most popular BERT4rec repositories on GitHub.
Not stopping there, they then tried several more recent BERT style models (ALBERT, DeBERTa) from HuggingFace and further improved results. See the results below:
Learning Users’ Preferred Visual Styles in an Image Marketplace (Shutterstock)
Authors: Raul Gomez Bruballa, Lauren Burnham-King, Alessandra Sala
Lab: Shutterstock
Link: https://dl.acm.org/doi/pdf/10.1145/3523227.3547382
Providing meaningful recommendations in a content marketplace is challenging due to the fact that users are not the final content consumers. Instead, most users are creatives whose interests, linked to the projects they work on, change rapidly and abruptly.
To address the challenging task of recommending images to content creators,author’s proposed a RecSys model that learns visual styles preferences transversalto the semantics of the project’s users work on. They analyze the challenges of the task compared to content-based recommendations driven by semantics, propose an evaluation setup, and explain its applications in a global image marketplace.
They present the ShutterStock search pipeline:
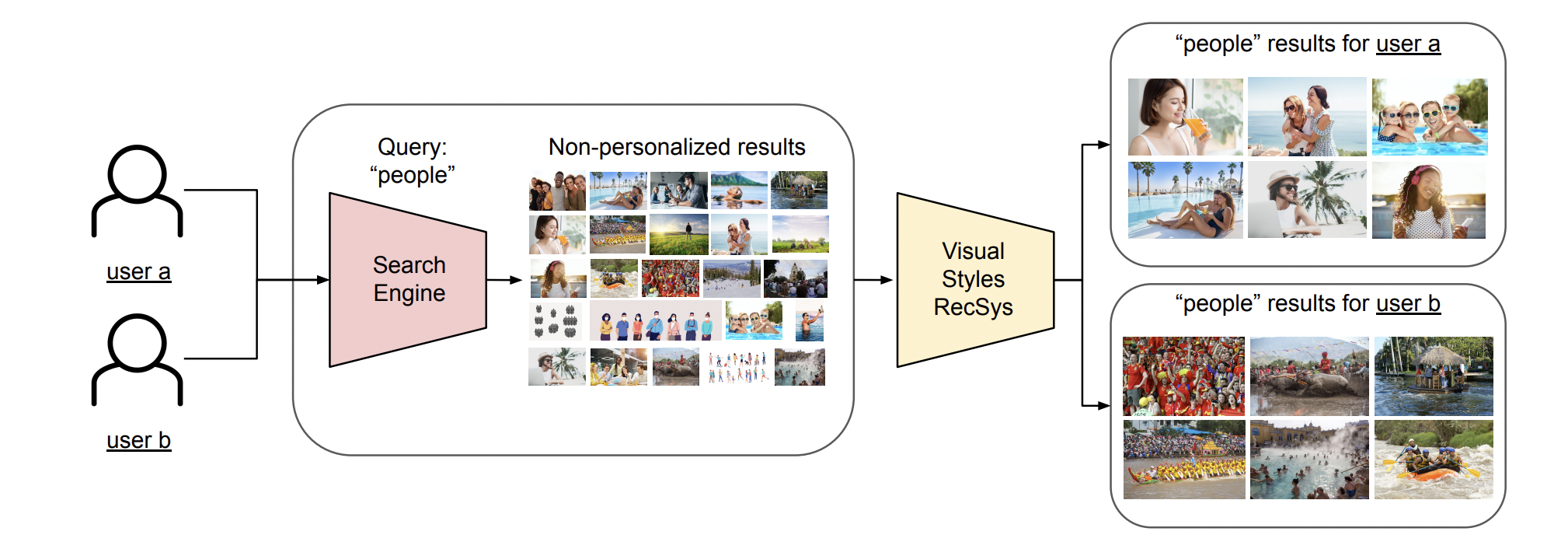
Where a user queries the search engine, which returns non-personalized results matching thequery semantics (in the example, “people”). Then, Visual Styles RecSys re-ranks those results, and the ones inline with the user preferred visual styles are shown first, similar to a traditional retrieval-scoring setup.
Their model Visual Styles RecSys:
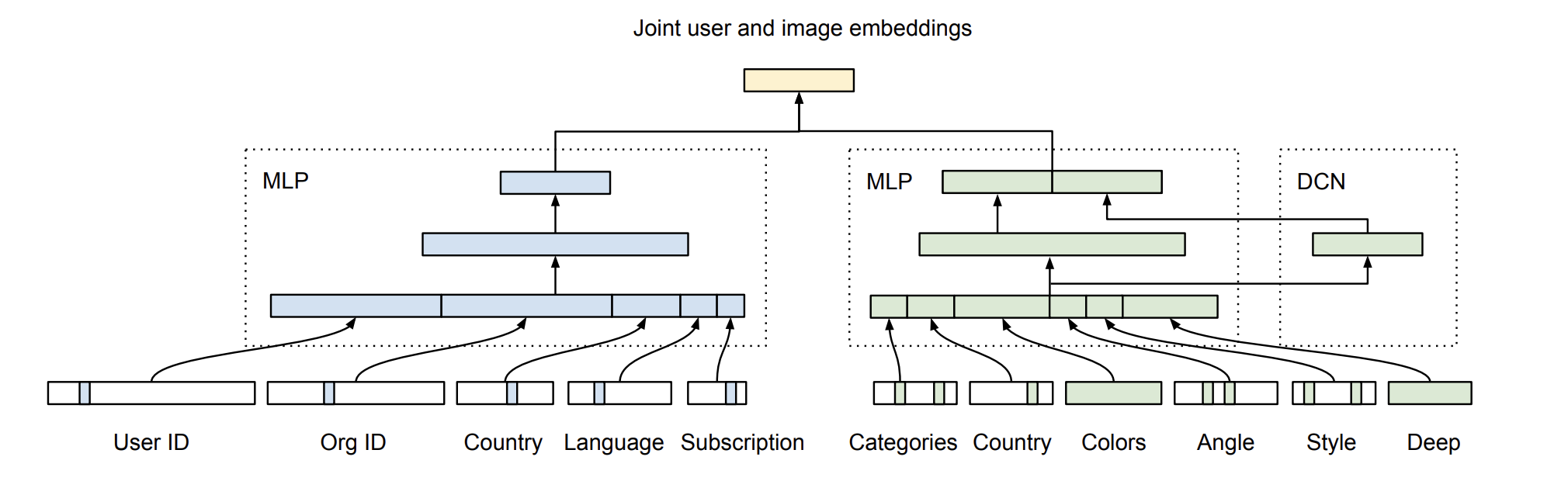
In blue are layers of the user encoder, and in green are layers of the image encoder. MLP(Multi Layer Perception) layers are linear layers with ReLU activations, and DCN (Deep Cross Network) layers are Cross layers. Reminds us of the original NCF model.
They only presented results against a Popularity baseline. Improving classification metrics and coverage but worse Visual Diversity. Visual diversity is a metric based on the distance within deep representations and of recommended items, is expected to decrease as the model now is learning features in contrary to the popularity model where features play a less impactful role.
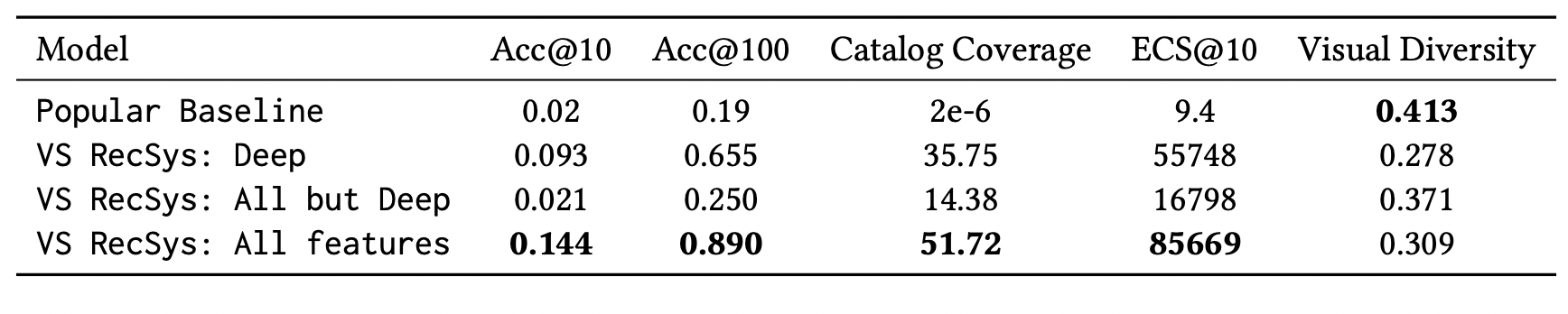
Author’s use negative sampling (not mentioned in paper but we talked with them in the venue). They select negative samples for each user as items interacted by other users within the batch. This method will be biased towards popularity as the negative sampling will now follow the item popularity distribution. We would love to see future work where other methods used in RecSys are evaluated.
Personalizing Benefits Allocation Without Spending Money (booking.com)
Authors: Dmitri Goldenberg, Javier Albert
Lab: Booking
Link: https://dl.acm.org/doi/pdf/10.1145/3523227.3547381
Ad campaigns are often run powered by recommender systems and have a limited budget. Optimizing who to target becomes part of the loss function along with what items to recommend.
In this talk, the authors focus on what customers are more best to provide an offer and how to find them. This customers would often not not create bookings unless discounts are given to them. By targeting this customers first booking increased customer conversation rate while using lower ad campaigns. This allowed them to generate more revenue from the initial customers and increase the total budget, to finally target a bigger customer base than they would have if they didn’t initially target customers.
Aspect Re-distribution for Learning Better Item Embeddings in Sequential Recommendation
Authors: Wei Cai, Weike Pan, Zhechao Yu, Congfu Xu, Jingwen Mao
Lab: Zhejiang University & Shenzen University
Link: https://dl.acm.org/doi/pdf/10.1145/3523227.3546764
In this paper, the authors aim to reduce bias present in item embeddings learn on sequence models. They do this by representing an item using several aspect embeddings with the same initial importance. The importance of each aspect is then recalculated according to other items in the sequence. The aspect-aware embedding can be provided as input to a successor sequential model. The full proposed architecture is called aspect re-distribution (ARD) and uses SASRec as the successor sequential model.
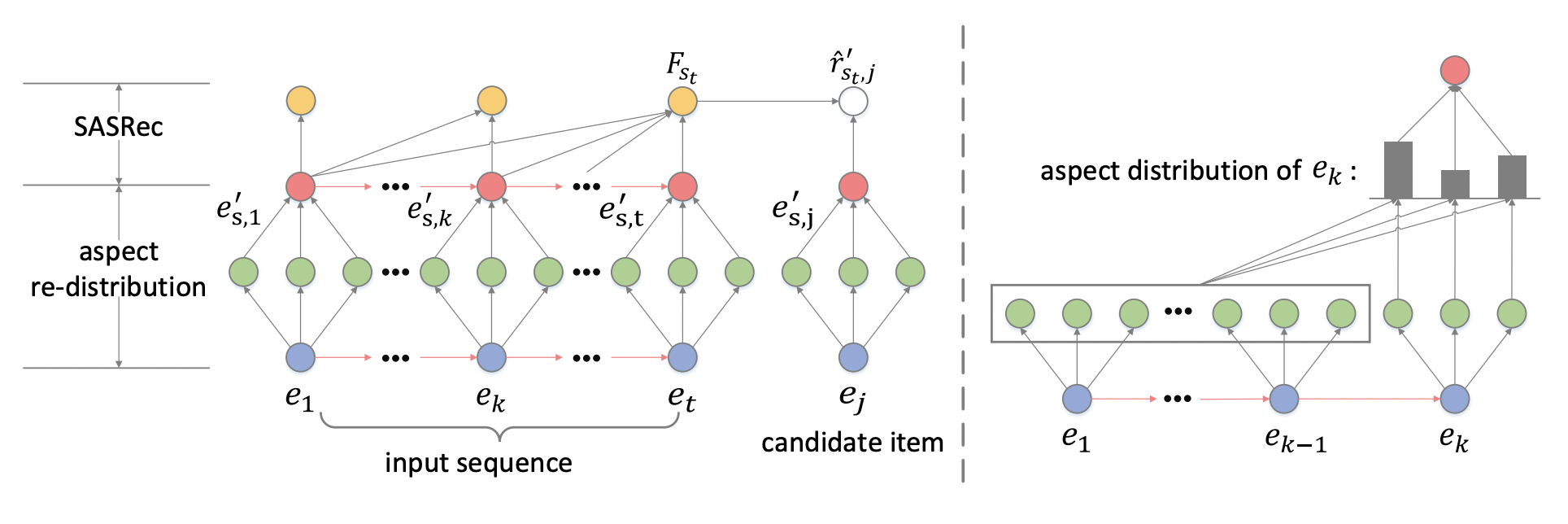
The left part: First, the embeddings (blue node) of each item is decomposed under some constraints into the aspect embeddings. Next, the aspect embeddings are aggregated into an aspect-aware item embedding. Finally, the sequence embedding (yellow node) is calculated from the aspect-aware item embeddings using SASRec[1], with which the relevance of the candidate item being the next item can be calculated.
The right part: Take the generation of aspect-aware item embedding of item k as an example, all aspect embeddings of the previous items (i.e., items 1, 2, … , k − 1) are accumulated (gray box). Then, the aspect distribution (grey rectangles) of item k is calculated. Finally, the aspect embeddings of item k are aggregated into an aspect-aware item embedding accordingto the aspect distribution.
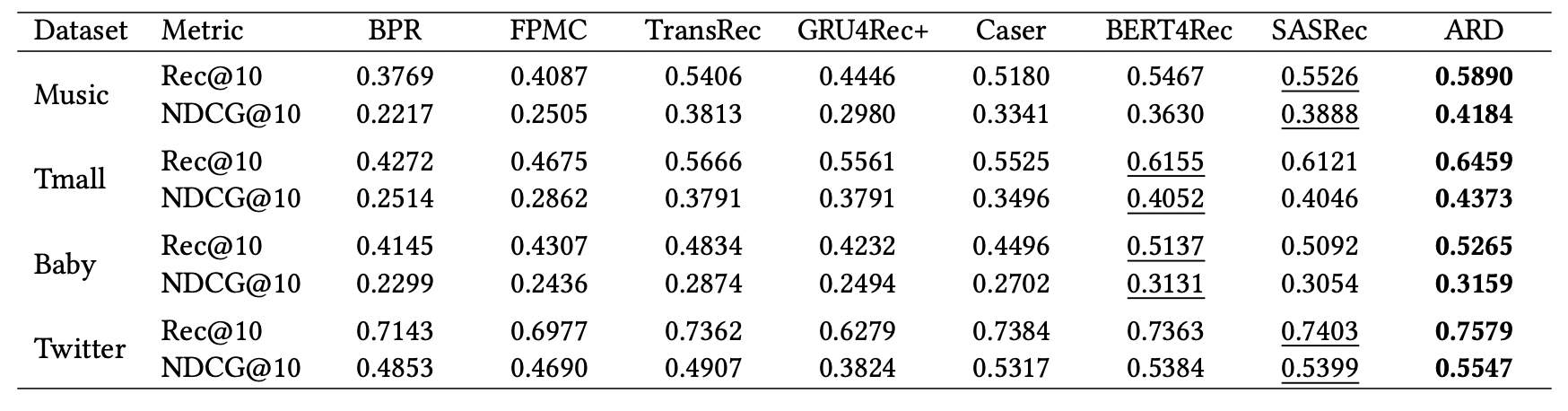
Their results show an uplift across different datasets against their baseline (SASRec) and other series of sequential models.
[1] Wang-Cheng Kang and Julian McAuley. 2018. Self-attentive sequential recommendation. In ICDM’18. 197–206.
Thanks for reading. If you found the summary helpful please like and retweet 🙏 Stay tuned for our Day 2 update tomorrow 🙌
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.