
Title image fromXavier Amatriain (2023)
Despite their groundbreaking capabilities, people argue whether these language models are still missing fundamental parts that make up general intelligence. The question is whether these language models, when the parameters are scaled up, could match human-level intelligence. Or are these language models just understanding the statistics of language, so that they can pattern-match output well enough to mimic understanding?
In the recent paper: “Augmented Language Models: a Survey”from Meta AI, the authors argue that statistical language modeling is a fundamental defect of LLMs. Notably, the issue of having one single parametric model (rather than an ensemble of models working together), and a limited context of typically n previous or surrounding tokens, is a severe limitation. And although the scaling up for the models and their context will always improve things, there’s a need for research to solve these issues.
The survey paper goes on to explain that language models need to develop reasoning skills (rather than just statistical language modeling). With reasoning capabilities, these models can output a plan of how to solve a task with easier sub-tasks, which can be solved easily by other tools (e.g. APIs, programs, or task-specific models). Furthermore, these models typically become more interpretable as the causal means of how an LLM came up with an answer is captured.
How can a language model reason?
The authors define reasoning in the context of LLMs as the following:
Reasoning is decomposing a potentially complex task into simpler subtasks the LM can solve more easily by itself or using tools. There exist various ways to decompose into subtasks, such as recursion or iteration. In that sense, reasoning is akin to planning.
So for the LLM to be reasoning in this context, we expect it to output an instruction set of how to complete a task when given a prompt. Below we discuss several of the mentioned strategies in the ALM paper to augment LLMs to achieve reasoning including: Eliciting reasoning with prompting and Recursive prompting.
1. Eliciting reasoning with prompting
As opposed to “naive” prompting that requires an input to be directly followed by the output/answer, elicitive prompts encourage LMs to solve tasks by following intermediate steps before predicting the output/answer. Prompting typically takes one of two forms:
- Zero-shot, where the model is directly prompted. You can think of this as the case when you’re using ChatGPT’s playground tool and asking it questions it hasn’t seen before.
- Few-shot, where the model is first fine-tuned on task-specific examples before being prompted.
Zero-shot
Kojima et al. (2022) investigated reasoning in the zero-shot scenario by simply appending “Let’s think step by step” to the input question before querying the model. Although this doesn’t do as well as the few-shot counterpart (explained next), considering this does actually work, it’s an argument for “just scaling these models up” as enough to have a general intelligent model that can reason.

Few-shot
Wei et al. (2022) was the paper that initially introduced chain-of-thought (CoT), a few-shot prompting technique for LMs. They propose to train LMs on a prompt consisting of examples of a task, with inputs followed by intermediate reasoning steps leading to the final output, as depicted in the diagram below.

Wang et al. (2022c) further improve CoT with self-consistency: diverse reasoning paths are sampled from a given language model using CoT, and the most consistent answer is selected as the final answer
2. Recursive prompting
The idea behind recursive prompting is to explicitly decompose a problem into sub-problems in order to solve the problem in a divide-and-conquer manner. These sub-problems can either be solved independently, where the answers are aggregated to generate the final answer or solve sub-problems sequentially, where the solution to the next sub-problems depends on the answer to the previous ones.
For instance, in the context of math problems, Least-to-most prompting (Zhou et al., 2022), first employs few-shot prompting to decompose the complex problem into sub-problems, before sequentially solving the extracted sub-problems, using the solution to the previous sub-problems to answer the next one.
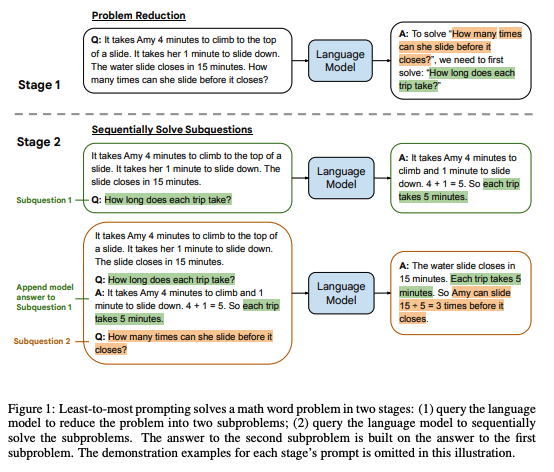 FromZhou et al. (2022)
FromZhou et al. (2022)
3. Explicitly teaching language models to reason
The prompt strategies above can be computationally expensive and require significant human effort to discover the right prompts for a given task. Several recent works suggest using a scratchpad to train LMs to perform multi-step tasks by seeing input tasks and associated intermediate steps during training, and then predicting the steps and answer at test time. Scratchpads differ from prompts in that they are fine-tuned on example tasks with associated computation steps.

Comparison and limitations of reasoning
Reasoning can be thought of as breaking down a problem either iteratively or recursively. However, there are potentially infinite ways to break down these problems and when the LLM models predict each one there’s no guarantee that the chosen reasoning is valid. In fact, by having to predict each intermediate step, there may be more of a chance of error because each step needs to be correct rather than just the final output. For example, mistakes in nontrivial mathematical operations in a reasoning step may lead to the wrong final output.
Finally, a reasoning LM seeks to improve its context by itself so that it has more chance to output the correct answer. To what extent LMs actually use the stated reasoning steps to support the final prediction remains poorly understood (Yu et al., 2022).
Conclusion
This post discusses the “Augmented Language Models: a Survey” paper and talks about several research directions to coerce, prompt and supervise LLM models to reason about the tasks they’re solving. The advantage of this reasoning is that the model breaks down the problem into smaller easily solvable sub-problems, and provides interpretability to the human using the LLM to evaluate how the model came to an answer.
One thing that we mentioned earlier — and that is the main motivation of the paper we’ve been discussing — is that these sub-problems can not only be solved by the LLM model that generated them, but also by an external model or computation engine. We encourage you to take a look at the paper and stay tuned for more posts about this from us soon!
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.