
**“Retrieval Augmented Generation for Large Language Model in Watercolor” via DALL-E 3**
The quality of AI driven recommendations has witnessed remarkable advancements in recent years, enabling hyper personalized experiences in e-commerce, social media, and discovery applications. Even more recently there’s been another breakthrough advancement in the AI community: large language models (LLMs). These models introduce a new paradigm of machine learning that involves coming up with prompts to instruct the agent to perform tasks without having to fine-tune them on your domain specific dataset.
Naturally one has to wonder what this new paradigm means for the recommendation system (RecSys) community. And to motivate this direction I want to give you a thought:
Imagine a system that doesn’t generate recommendations from looking at only your domain specific dataset but also possesses the wisdom to tap into a vast sea of existing knowledge before crafting its response. This knowledge isn’t contained in a linear sparse matrix but instead a high dimensional latent space that contains rich information about your users and recommendation documents.
This is the inspiration of what an LLM can do for recommendation system and the key to making it work is: retrieval-augmented generation (RAG). Today we’ll talk about why RAG is helpful, and back it up with experiments against more traditional recommendation system baselines. Let’s dive in!
Need for RAG?
When we think about using an LLM as a recommendation model, an obvious question arises: why not just directly prompt the model with what we want to achieve? E.g. why not just ask ChatGPT to “Recommend documents that are going to most engage users?”. In our previous blog post, we found that recommending in this zero-shot, zero-context setting does not result in good performance compared to traditional recommendation baselines. There are several inherent problems with that approach, notably:
1. Context memory and context length
LLMs have a limit on how many tokens one model can ingest, this is determined by the underlying architecture, here by context I mean all the prior information that the model ingests along with a prompt to craft an appropriate response. If the context is too long the model will start forgetting the input given prior
2. Hallucination
LLMs can and do hallucinate. Every other month you may spot a Twitter thread on a new prompt that broke even the best models available. And really if you try it out for yourself you will sometimes get the result you did not ask for.
3. Bias
LLMs are notorious for biased responses as the quality and content depend on the prior dataset the model was pretrained on. Since these datasets are so large, they get cleaned via automation but this could be better. In a race to achieve the best performance other important metrics get eclipsed, the result however is not always satisfactory.
4. Inference speed
As we discovered in our previousblogpostinference depends on decoding strategy and the amount of data required to decode, picking a greedy strategy results in messier final results but gives a great speed. On the other hand, using something like beam search allows for neat output, but will generally take longer. In a world of recsys, the response time has to be in milliseconds.
However, saying that LLMs are bad at ranking is unfair, as evidenced by many recent approaches trying to utilize the models in different roles. You can read more about the overview of the role of LLMs in recess and their benefits here. Enter “Retrieval-Augmented Generation” (RAG), a groundbreaking paradigm that seeks to harmonize the strengths of retrieval and generation models.
RAG internals and externals
RAG as a concept comes from the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks by Patrick Lewis et al. At the center of this approach is the following scheme:
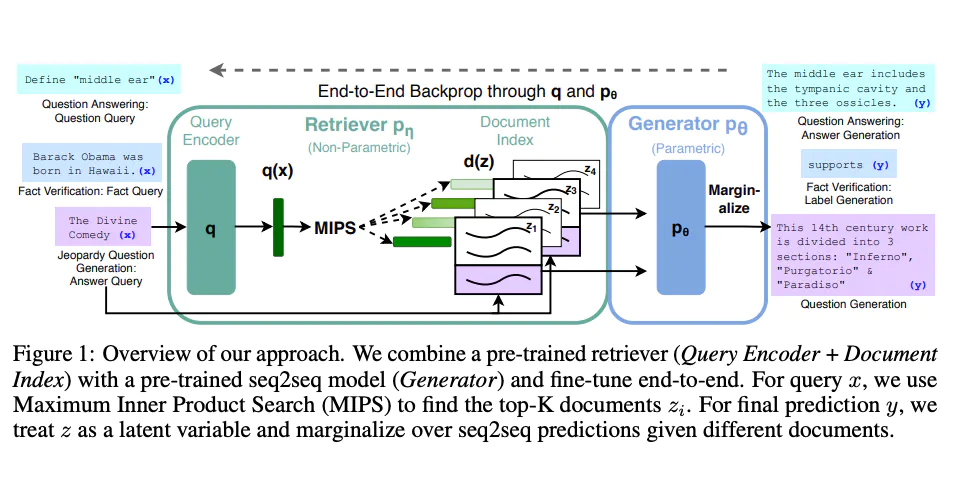 source:https://arxiv.org/pdf/2005.11401.pdf
source:https://arxiv.org/pdf/2005.11401.pdf
The part we mostly care about here is the **Retriever.**Regarding LLMs, frameworks like LangChain all utilize a form of RAG to create a ”long-term” memory for the LLM. More importantly, unlike accepted fine-tuning methods for some downstream tasks, this approach is less expensive to train and relatively straightforward to implement. Looking at the Retriever we can note the query encoder. This is a module that reduces our query to a vector of numbers encoded in relation to a certain latent space. The second component here is MIPS or Maximum Inner Product Search, but really in this case it can be any form of search over encoded documents. We then can retrieve the relevant context for the model out of the vast space of possibilities. This allows us to efficiently utilize the model’s context length and vastly improve the quality of our response. The Generator module in the scheme above can be viewed as our end LLM. As we can see to create the best kind we need to finetune them together. With that being said no rule says that the retriever model has to be the same, in practice, you can train and use a smaller LLM for retrieval and a larger one for the final generation.
See the representative diagram from AWS below:
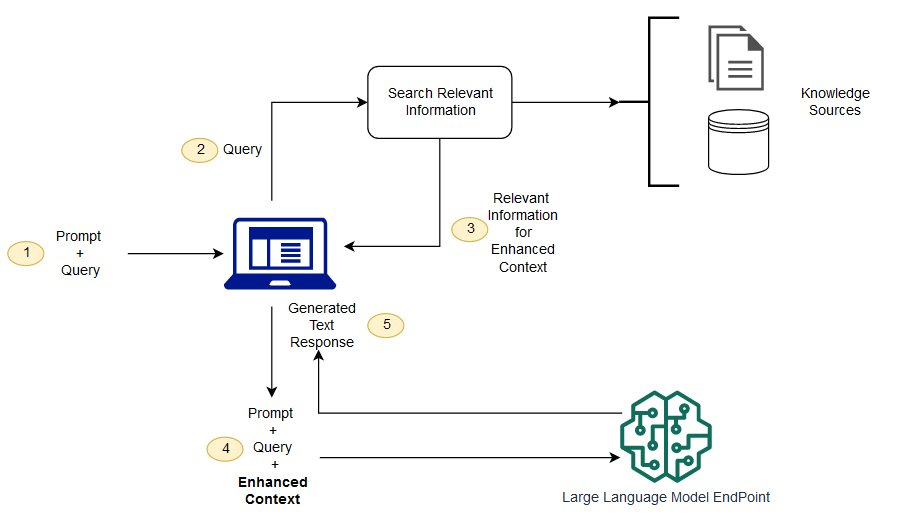 Source
Source
Building RAG
To build RAG, we need a way to store and retrieve candidate items/documents that will be used within the context of the LLM ranker.:
1. A way to ingest candidate items
2. A way to search over those ingested items and retrieve the most relevant ones
Vector search can help us do both at the same time. If you don’t know what vector search is I recommend taking a look at our previous post. In short, we encode information as meaningful, high-dimensional vectors in dense latent space and then search through them based on a similarity measure appropriate for vectors. Naturally, if the information between two vectors is semantically similar they will be closer e.g. encoded “apple” and “banana” vs. “apple” and “Gandalf”, because the first two are fruits, so they are semantically closer. To do so we will use two tools. For encoding I will use sentence BERT, however, I will utilize its implementation from the Hugginface library.
Currently, there are libraries like lancedb, that will allow you to extend your embedding powers beyond just text, giving you the potential to search and provide enriched context to your LLM. I will use the Movielens25M dataset to create this example, you can follow along with your data. However keep in mind that your data must be searchable, in my case I convert strings to semantic vectors and use similarity search. For many multimodal data formats, autoencoders, and other ML architectures that perform embeddings will work best to provide a suitable numeric representation. Remember that the key here is extracting a semantic vector from a user query.
In the case of a dataset of movies, the user may ask: “Recommend me a drama or romance movie to watch tonight?”. These keywords will affect the resulting query vector making it more similar to a vector of an entry that is a drama and romance movie (better yet if it has these keywords in the description).

Let’s first load the models. I suggest specifying a cache directory (model files will go here) as you will have greater control over where specific project files will live.
I already combined three different movielens CSV sheets into a pandas data frame. Each resulting entry has the name of the movie, genre, and tags that users described the movie with.
What we want to do is combine these into a single sentence and make sure that we have unique records, as many users like the same movie we want to encode the record once if there is no difference between entries for each user.
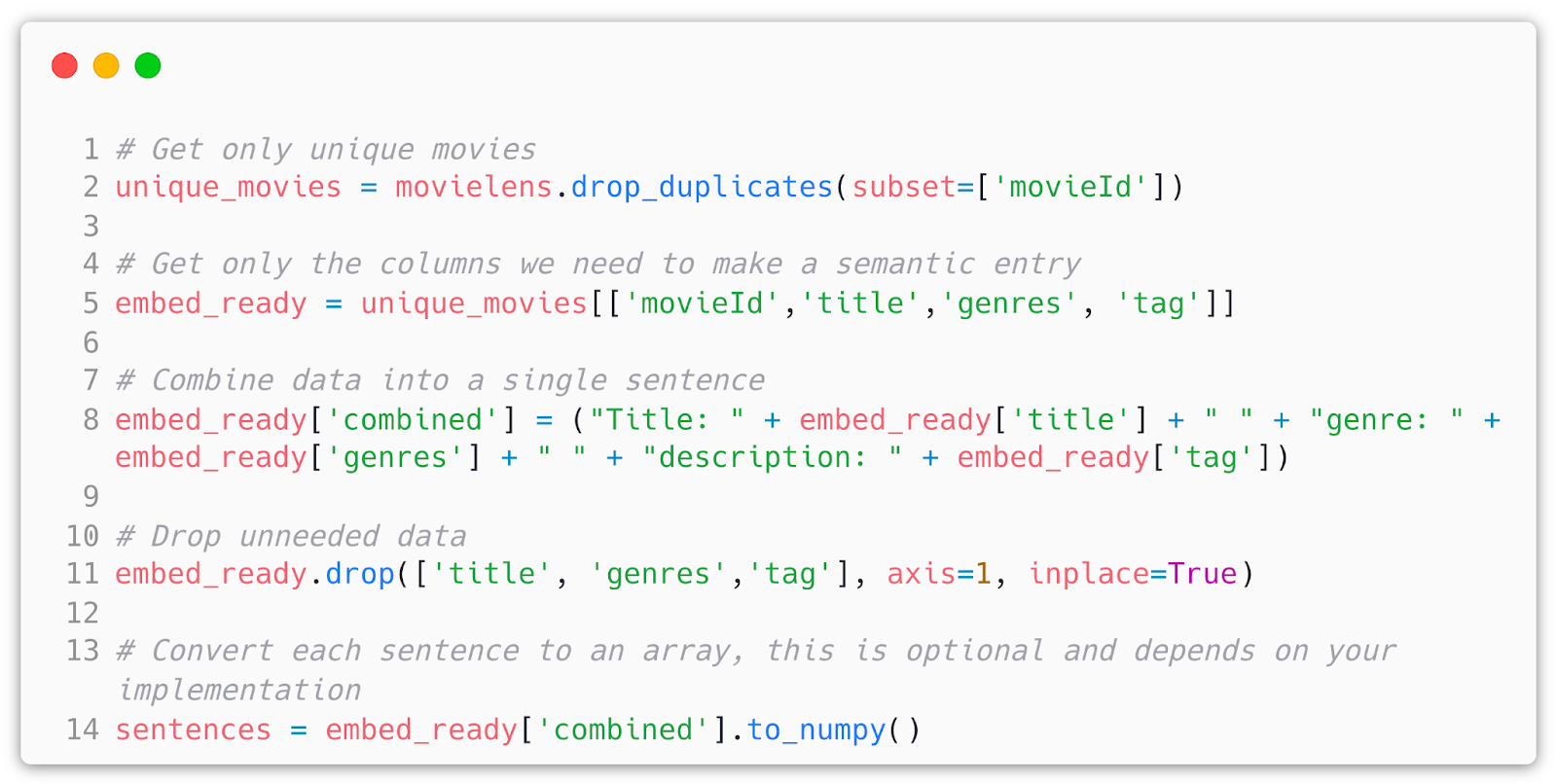
So what’s next? We need to make an embedding function, using the model and tokenizer loaded from Huggingface I do it like so:
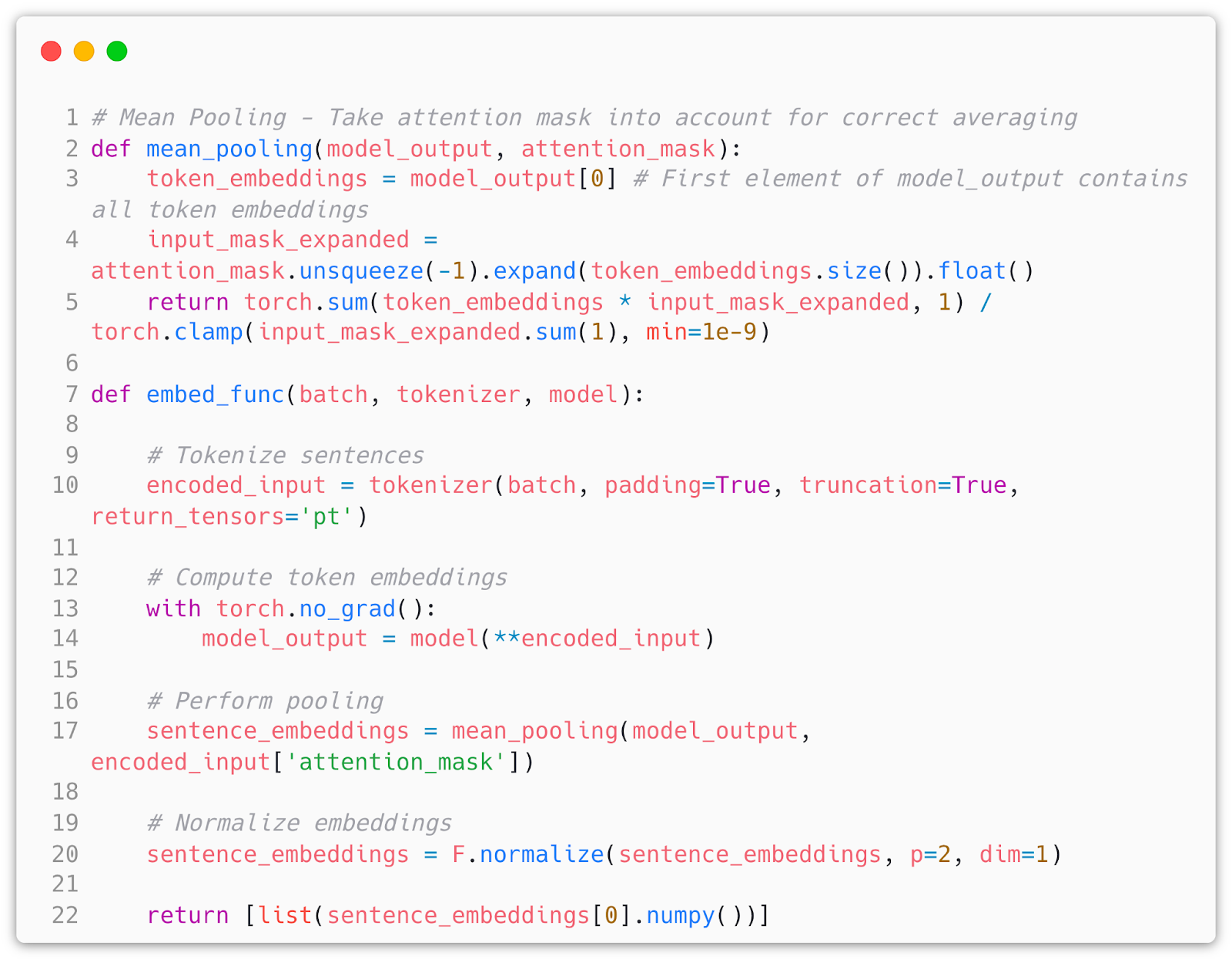
Due to the way sentence BERT works we need to create a mean poling operation to combine the attention mask and actual token embeddings we receive from the model to produce final sentence embeddings. We then can write a simple loop to embed all our data:
Then it is a matter of searching over the embeddings and corresponding records. To do so I use LanceDB and similarity search. We can create the table and perform a search like so:
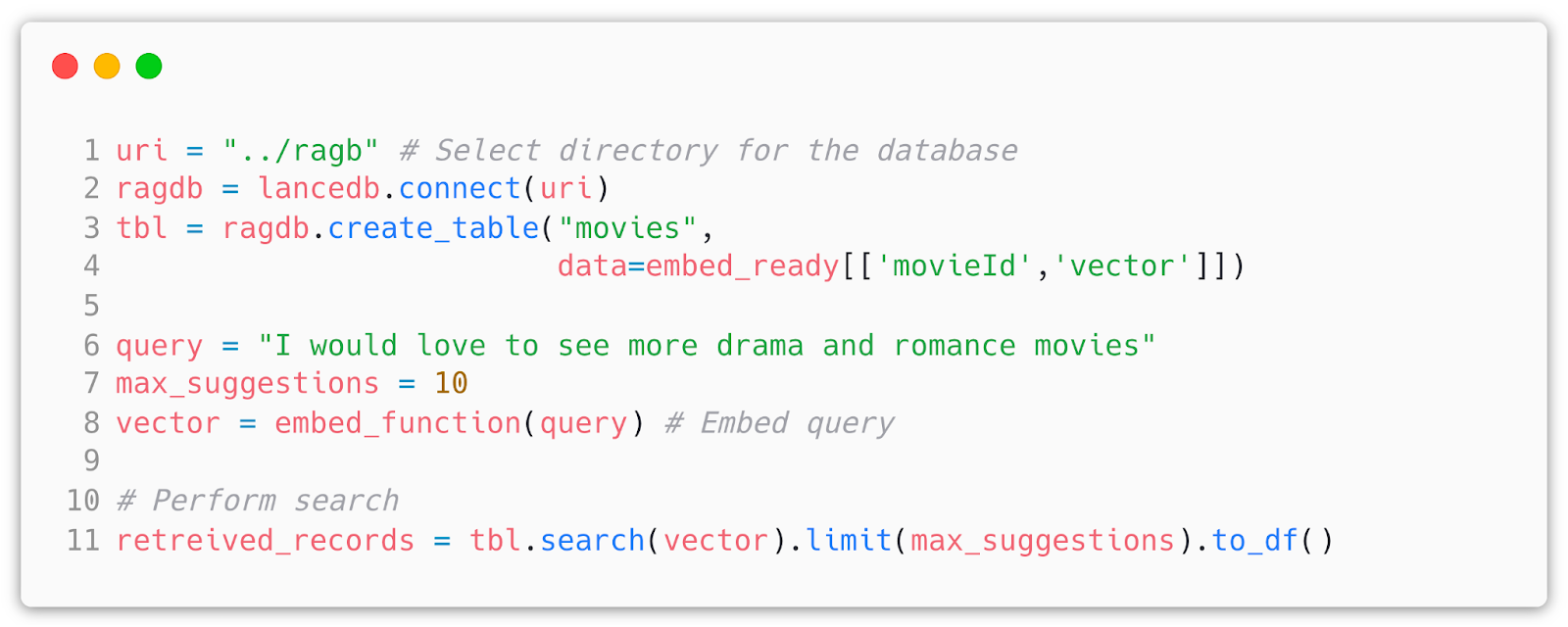
This way we can retrieve any number of records for our context and improve our LLM response.
Marks and Measures
Naturally, we have a set of questions: how do we measure the benefits of RAG? Is the benefit worth it against the engineering effort? Are there extra considerations and “underwater stones” we might need to be aware of? Let’s go through them one by one.
Measuring RAG
I decided to do some performance tracking using models you can find in every recsys toolbox. Essentially I will use a sample of the Movielens dataset on a few baselines. The dataset in question is 5-core (meaning removal of users with less than five or items that are interacted with less than 5 times) split in training and test using “global temporal split” which in essence amounts to splitting by timestamp in proportion 9:1 for train:test. We then also want to make sure that item sets between two splits are equalized, some models we will employ operate using sparse matrices so we want to make sure that the test set possesses the items in train. This isn’t an issue with deep learning models and if we are using encoded input, which is one of the other benefits of using RAG and DL models like LLMs for your recommendation pipeline.
Now back to the models.
We will compare ALS and LogMatrix models against popular list and random list. For random we would randomly recommend N items for a user from the test set, in this case, N=100; this is done to ensure that the model is learning something. Next is the popular list model, to construct this one I take all the items and sum their relevance scores across all users, this ends up giving me a measure of popularity for all users that I can sort. If you want to understand ALS and LogMatrix factorization better you can read about them at their respective links.
For RAG we want to retrieve the top 100 relevant items for ALS and LogMatrix, then we will ask those models to perform a rerank task and measure HR@10 and NDCG@10.
For GPT-3.5 which will serve as our reranker LLM, I do a bit of prompt engineering and construct the query in the following way:
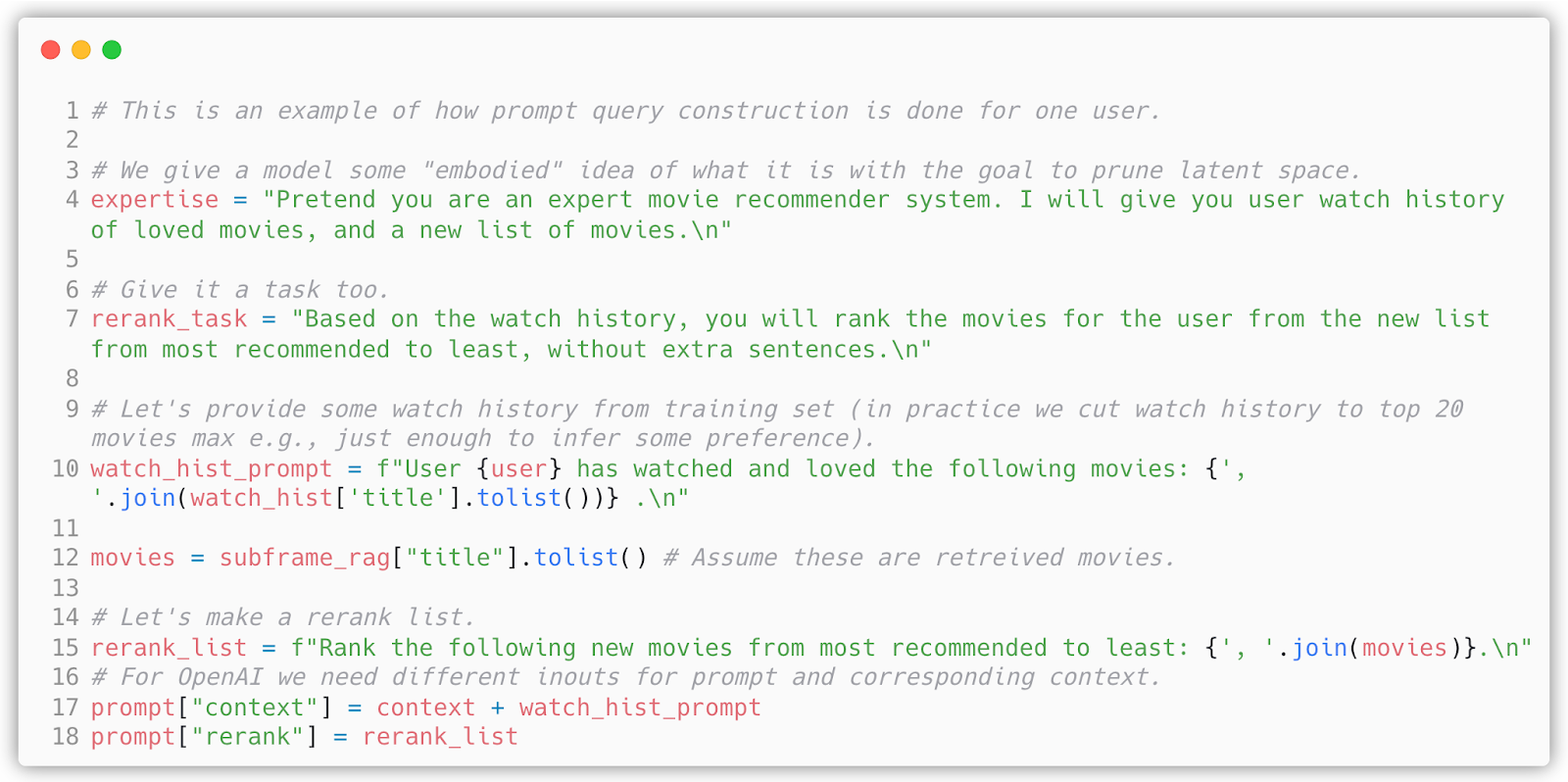
We want to pass watch history as common sense and existing literature evidence would suggest that there should be a way to describe a user, so naturally based on the most liked movies you want to get new ones that will match your preference. You can expand this concept to describe detailed user profiles from a multitude of characteristics. The next step is just querying the API and fitting/measuring all models.
Here are the results:
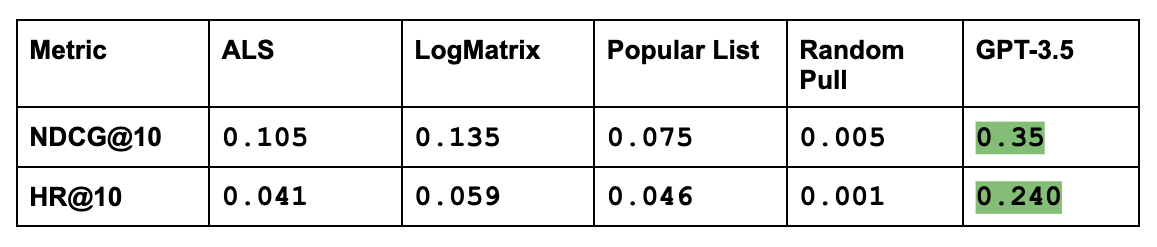
Results speak for themselves in that there is evidence of performance gain by combining RAG and LLM. Specifically, RAG allows for performance increase on all models. But for an LLM RAG is particularly suitable to cut down on the tokens required to produce reranking and as a stable pipeline for long-term data insertion.
Additionally, keep in mind that I have not pretrained GPT for this specific task, it is relying on movie titles alone to produce a recommendation. Adding pretraining, a better model, and better task definitions along with an expanded user profile potentially will superboost these performance numbers.
Worth the effort?
I would say so, RAG’s’ ability to ingest multimodal data as well as different data objects are given a suitable encoder represents the most flexible way anyone can address long-term data collection and relevance search. You hypothetically could construct an embedded model that will ingest video as well as its short description and produce a semantic multimodal embedding vector, the limit here will lie in the ability of trained architecture. We can create a live memory structure for an LLM that can recall the best items in advance, thus avoiding issues with context length and forgetting. We can also update the vector database on the go if the user discovers new items and rates them higher, essentially the best interactions are also dynamic in this case.
I must add though that for RAG to work well you need to do some careful training along with your model. For production, retraining the whole model often means high costs and it is not very clear how a good pretrained embedding model will compare to a small one that is getting constantly updated as new online data comes in. This is a question for future research but I’m willing to bet that in the case of a good embedder frequent retraining won’t be required. It is also worth mentioning that most of the RAG cost comes upfront from fitting it on a specific dataset and making it work with the LLM ranker in question, whereas down the line it is amortized as the updates are generally not done.
Extra Observations For Production:
- Long context models are what you will need if you want to fit in a lot of data to rerank, but this comes at a cost. A limitation of all transformer architectures is their autoregressive nature. For input, you can feed in a lot of data rapidly, for the output however you will be generating all of your data token by token, as the new prediction requires maximum likelihood measurement over other tokens( this is subject to the sampling strategy you are using aka beam search, top-p, etc.). Hence a lot of data=slow output, and slow output is what we can’t have for a recommendation system. Minimizing this tradeoff is a special engineering problem on its own.
- Hallucination is a constant problem. Yes, I said it. In fact, one thing I avoided mentioning in the results is that @10 metrics worked well because model with a 100 items to return is very likely to give me back at least 10. In practice, if you are not careful with your sampling parameters like temperature, and allow the model to get a bit more creative you will end up with fewer or more items than needed, or items that do not exist. I expect this can be generally resolved with some finetuning on the dataset. For my experiment, I kept the temperature at 0 and used fuzzy string matching that matched the movie title to the closest corresponding title in the dataset to translate this into an item ID.
- You can’t use streaming for everything. If you use ChatGPT you are used to it printing a line out, this is a clever trick called streaming, meaning tokens are outputted as soon as they become available, this makes it seem like the response is coming out just as you requested and there is no latency. Obviously, this does not suit the case where we need a complete model output, so for each set of items you will have to wait for the full output time to get the complete reranked list.
So what’s next?
RAG might not be a perfect solution to every case but it is still a formidable approach. Recent papers like PALR: Personalization Aware LLMs for Recommendation demonstrate the benefit of using RAG for LLMs oriented for recommendation. One shortcoming that RAG cannot address is the structure of your data. As we see the concept of similarity is very important here, hence to get the best match of the embeddings that hold the representation of your data it has to be the best as well and that is largely model-dependent. Hence the failure of RAG might be related to your embedding model not learning a good semantic meaning of your data.
Largely the research into the effectiveness of representation in RAG is missing. Additionally, we currently don’t have an idea of the usefulness of RAG and LLMs in multimodal datasets combining text and images or text and video.
Overall RAG shows great promise in enhancing future LLM-oriented applications. Stay tuned for our new posts where we explore LLMs as recommendation systems in greater depth!
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.