
Uses of AI
It’s common to do your daily tasks and not stop to realize how technology is part of society. There are many situations in which AI is involved: when you are going somewhere but using Google Maps, if you don’t know what film to watch, Netflix helps you, or even in health-related fields.
Most of these AI applications are not determinants. For instance, I will not suffer if Spotify recommends a song I don’t like. However, there are professional usages where it is decisive, such as diagnosis or trials. Should we know why AI has decided on a particular result? Is the process for a result always necessary?
Types of “boxes”
All those examples are involved in the new technological field which tries to extract information from data, and it has lots of phases: data management, which acquires, stores, and cleans the data; creation of models to accomplish an aim, such as prediction or analysis; and sometimes visualization to explain which is the obtained information or the results from the data and model.
The problem given in the introduction is done in model creation.
What happens in that phase?
When a Machine Learning (ML) engineer or a Data Scientist has to decide which model fits better with the proposed goal, there are many models, and each has its features.
ML models are divided into three types: Unsupervised, Supervised, and Reinforced. However, that’s not the only way to classify the models. They can be distinguished between Black boxes and White Boxes.
Which are the differences between these two systems?
First, white boxes are named to those models which receive input, and after its training, you can know all the decisions taken to an output given. Let’s imagine there is a model that predicts when it’s going to rain. It receives data related to humidity, temperature, speed, wind… And it says which is the probability of precipitation. In this model, the user could see if the decision was made because the temperature was low, the humidity was high, or perhaps it was due to many conditions.
On the other hand, a black box is a system where the only visible part is the input and output. As its name says, the decision-making process is hidden from the user. Continuing with the previous example, the model receives the same information about the weather in this case. Still, you cannot see the exact mechanism of what features are more decisive or which ones are not influential.
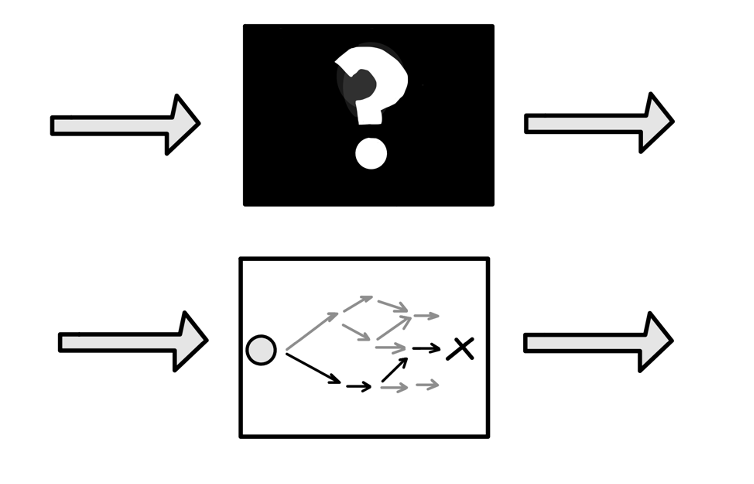 Black boxes vs White boxes (ML models)
Black boxes vs White boxes (ML models)
Problems arising
Once the two sorts of “boxes” are explained, it’s time to return to the post’s beginning. As it is said, many uses of AI are just for making life easier or enjoyable. Nevertheless, other areas where AI is starting are delicate due to different factors. These factors are the reason why explainable models are needed:
Fairness
Let’s suppose a trial for a crime. We have acquired data from the last years, including information about the type of previous crimes, the subject, and details about what happened, to decide whether the subject is innocent or the punishment.
What would the result be if that court tends to punish black people rather than other races due to the proportion in the population? In this situation, the model is biased and will be more likely to predict black people as criminals.
Then, having a black box as a model, the prediction can’t be supervised, and justice will be in jeopardy.
Causality & Bugs
Fairness is not the only aspect compromised. When you are training models for a particular purpose, there are variables you don’t feel can affect a model.
Now, you are trying to distinguish between land animals and birds. It seems to be easy. However, ML models learn patterns, and one of them for this classification is the background. When you think about birds, they are flying or in a tree, and that’s what the model can learn. But it isn’t always true because a bird can go on shore.
This case can be detected using interpretable methods, but you can make the model more robust by modifying the images. That’s called data augmentation for image classification.
Regulations
Nowadays, many countries are regulating AI usage. One of the cases is in Europe, where individuals can ask about algorithmic decisions based on Art. 12 GDPR (data protection law).
How can black boxes be interpreted?
First, we need to know which methods aren’t explained by themselves. To make figure it out quickly, here is a figure:
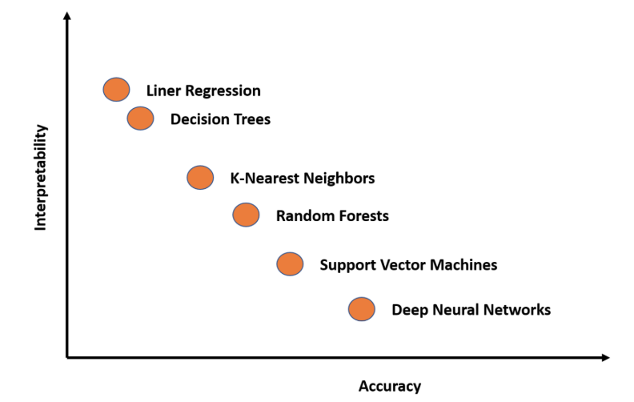 The complexity of the ML methods
The complexity of the ML methods
Ways of interpreting black boxes:
Feature Importance
The basic technique to understand an ML model is ranking the different features. This is common in interpretable methods, but it is essential to understand.
When simpler models are used, like linear regression or decision trees, the variable importance can be known by the coefficients (linear regression), or thanks to visualizing decision trees, it is possible to see how the decisions are taken.
However, it is tough to comprehend what’s happening when many features are involved. That’s why there are different measures:
Once common in decision trees are Gini gain:
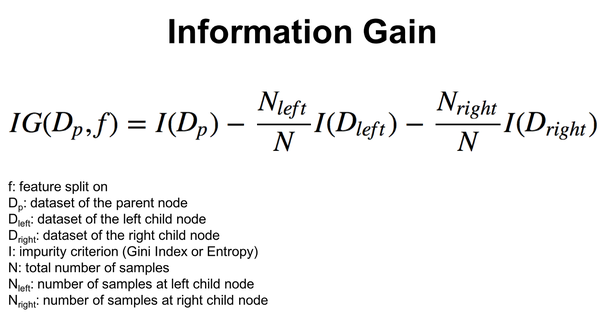 Information Gain formula
Information Gain formula
Global Surrogate Models
This method is useful when we need to explain an opaque model. When you have your model trained and prepared to work, you may wonder what’s the next step to discover its decision-making. The idea here is to create a secondary ML model.
How does it work? Once your next move is creating that secondary model, you should choose an interpretable model and train it with the same data as you did with the primary model. Still, the target variable is the predictions of this prior model.
So, this surrogate model is interpretable and tries to behave as the black box model does. The more accurate this surrogate model is, the better you should explain the black box model.
In summary, you choose an interpretable model, get predictions from the black box model, and use them for training the interpretable model selected. Once done, you will measure the accuracy of this surrogate model and interpret it to understand the black box behavior.
LIME (Local Interpretable Model agnostic Explanations)
Those prior methods to interpret models are global, and you can learn how a model works in general, such as features’ importance. However, occasionally you are wondering about a specific subject and why the model has taken a particular decision over a user.
What should we do if we want to figure it out? That’s the time for LIME. It is a technique focused on local interpretable agnostic model explanations.
This method works as follows, LIME produces lots of samples following the normal distribution and modifies the input data. It calculates the distance between the original and created observations and tries to predict the new points. After that, it selects the best features that describe the permuted data and fits a linear model on that data.
This fitted linear model is now how we can explain the decision for that specific subject.
Conclusion
We have explained how AI is making decisions in our daily lives. Moreover, we named how the models are classified and explained the differences between interpreted and not interpreted, white and black boxes, respectively.
Answering the beginning questions is not always compulsory to reach a model functioning. However, each day it is more legislated and vital in business aims. The users are more aware of how ML models can affect their lives and ask how decisions are made. That’s why we should prevent and learn specific techniques to achieve a transparent model.
In this post, we have explained many techniques for this transparency and interpretability: Feature importance, Global surrogate models, and LIME.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.