
Today’s recommendation systems are often incredibly complex, akin to a large machine with many moving parts carefully engineered to provide your users with the best suggestions possible. It is hard to design right and even harder to tune, and so not surprising that recommendation systems are their own field of research. After all we all unknowingly or not heavily rely on recommendations and this existing paradigm. However, this preexisting status quo might be about to change. If you were awake for the past 6 months you saw how AI came forth from research labs and universities straight into the mainstream for everyone. At this point it is very likely your mom has tried ChatGPT. At the forefront of widespread adoption are large language models or LLMs. Specifically: a large parameter count of foundational models that were pre-trained by research communities, large private and non-profit labs and companies. With their ability to ingest background knowledge from large datasets scraped from the internet it is no wonder that researchers have thought about emerging capabilities of AI trained on such vast amounts of information. And it is precisely this theory that inspires this post.
Real power of LLMs
Okay, so what? Language Model Machines (LLMs) have been making waves in the tech industry for their ability to generate natural language and respond to user input, but can they be more? LLMs have the potential to be powerful recommendation systems and change the way we consume information and products.

The secret to LLMs’ success lies in their ability to understand the context and meaning behind words. Unlike traditional recommendation systems which are statistical linear models that rely on keywords and metadata, LLMs can analyze the entire text of an article or video to understand its topic, tone, and sentiment. This allows them to make recommendations that are not only relevant but also aligned with the user’s interests and preferences. And unlike current approaches LLMs due to their central idea of being a general tool, are capable of very good generalization and customization, this partially comes from emergent properties of language models of scale. Here is some extra spice: LLMs are also capable of learning from user feedback. If you interact with an LLM’s recommendations by clicking on a link, for example, the system will take note and use that information to improve its future recommendations. This feedback loop allows LLMs to continuously refine their recommendations and provide an even better user experience over time.
A research team behind the paper Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agent, discovered that two key pieces that make LLMs a good candidate for RecSys. First is the way to meaningfully encode information: the sheer vastness of LLM’s latent space allows it to produce a better representation of the ingested information (this also allows it to effectively address cold-start cases), whereas other approaches often cannot recommend anything unless you provide some starting data. Second is a constant ability to update the latent space using user feedback. This happens through repeated interaction with the LLM, as user provides more information the latent space adjusts to give appropriate tokens better probability of being selected. Let’s briefly look at those two closer:
Power of Embeddings
Embeddings are frequently employed in the context of search systems to transform textual content into numerical representations or vectors. These numerical representations effectively compare and analyze the text while capturing its semantic content. Semantic embeddings enable a deeper understanding of user preferences by capturing the subtle nuances in expressed or implied intent. Unlike traditional approaches that rely on simple keyword matching or basic metadata, semantic embeddings allow recommendation systems to comprehend the underlying meaning of queries or user profiles. This understanding goes beyond the surface level, taking into account the context, synonyms, related concepts, and even the sentiment behind the user’s interactions. By leveraging semantic encodings, recommendation systems can provide more accurate and contextually relevant suggestions, enhancing the user experience and increasing the likelihood of engagement.

To simplify the better the model is better in producing these semantic vectors the better understanding of the items it possesses and therefore likely the better recommendation we can get. If we know that LLMs are trained on large datasets with various types of content then we can assume they possess a good amount of knowledge on various topics and things that we might want to recommend. If you were to picture every item for your user as a vector then all items exist in latent space with mathematical relationships between them.
If we measure the distance between those we can predict how similar they are, this being said this is just one of the ways to do rankings. In theory LLMs can utilize the concept of similarity of fit given that they understand spatial relationships in the latent space they learned.
The Setup
To test our theory we will be using LLMs to recommend us movies. Why not? Spotify, TikTok, Netflix we all use them to recommend us content so let’s see if we can do better. For this article motivated by previous experiments in the community and recent emergence of open source AI I want to focus specifically on open source models. On the menu today for you I have LLAMA (7B,13B,30B,65B), GPT-J.
- Since these models generally work in a prompt continuation (which is different from QA model of ChatGPT), we need to construct a prompt that would fit our requirements of returning the recommended movies, preferably in some form of a parsable sequence
- Two key parameters like temperature and sequence length need to be adjusted to reduce model hallucination. Temperature - refers to how “creative” the model should be, the higher the value the more freedom the model would have to generate something different from your prompt. Max sequence length- is the length of the output sequence of tokens you will receive upon inference. We can also adjust sampling parameter top-p, which determines the amount of less likely words to exclude from the sampling pool, but since probability distribution of words changes with change in temperature values this has a similar effect as changing top-p.
- We also need a way to determine if a model performs better or worse, hence we also need a way to parse the results from the output and compare them to the dataset.
For LLAMA you can find code provided by Meta here, which will help you run this experiment. For GPT-J we wrote custom code but it is very straightforward and simple nonetheless.
To start off we want to test zero shot performance of the model for example:

Ideally we want the model to give us a specified amount of results (n) similar to items in item_list, and to queue results via a special symbol for this purpose I chose =>. For starters lets try to run the prompt above on all the models as a zero shot example and see how they do:
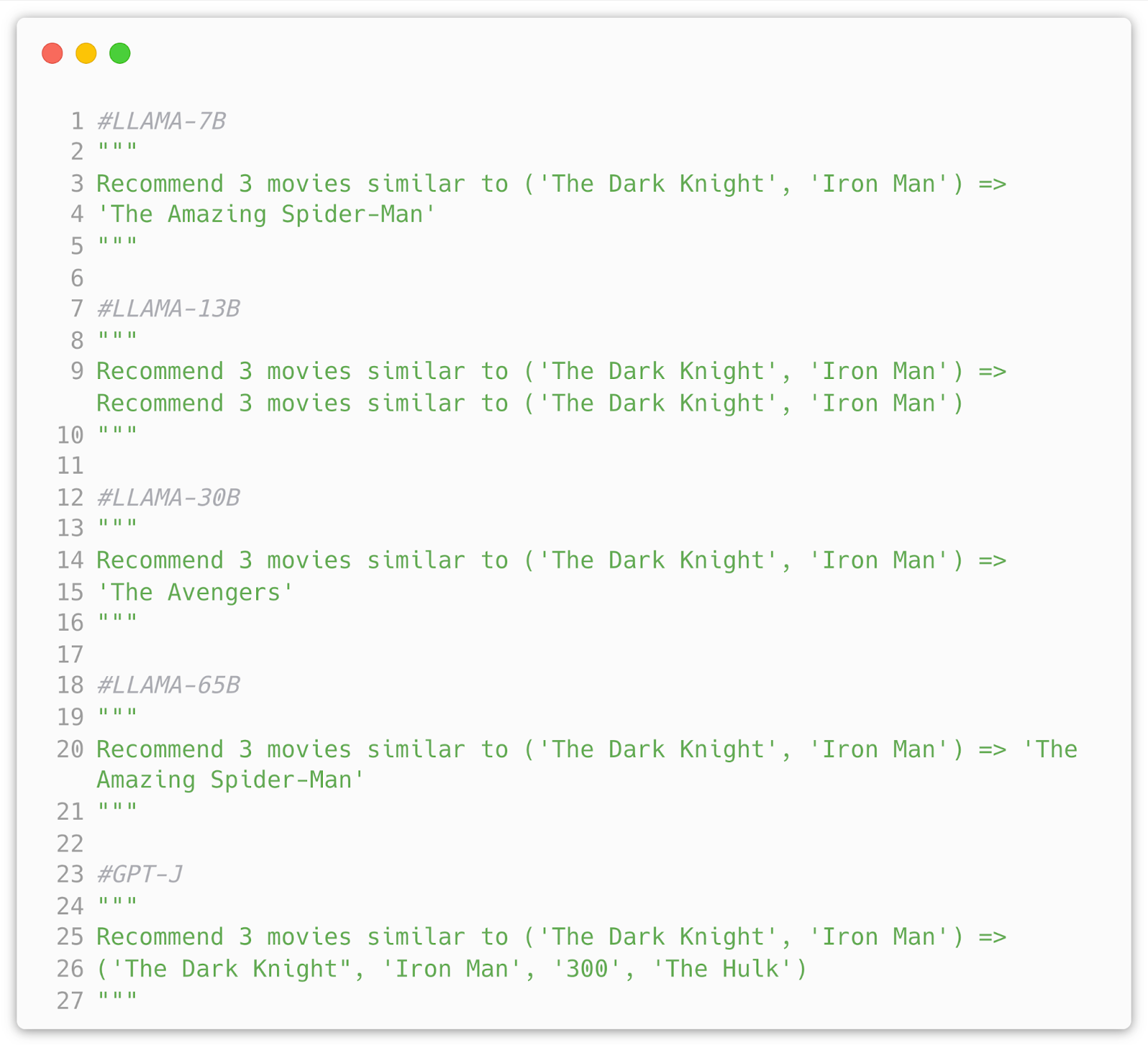
So some mixed success here and there. Not too suitable for us. However, I tried a few other prompts and zero shot was viable. From my observation it has very much to do with the movies in the prompt. Let’s see if few shot prompt can fix this:

Now this is much better, we get proper output with existing movie titles and in proper format (we get exactly 3 movies). But we can still nitpick, for example I chose a specific movie collection to prompt because they are all Studio Ghibli films, that all are anime and in fantasy genre, most importantly they made a few movies so their titles will be easy to recognize. From the plot above:
- LLAMA 7B model suggested kids movies, which is a decent response as Ghibli movies were largely marketed for children and generally are family friendly.
- 13B model nailed the task with all 3 films bering Ghibli films
- 30B model did give 3 anime films but their are from different studios and directors and not entirely fit the genre
- 65B model nails the task perfectly again
- GPT-J model does a similar job to 7B model, some good some not quite right
We shouldnt necessarily say that by suggesting slightly different movies the model fails as novelty is one of the core metrics in RecSys. The question now is how do we separate models’ ability to generalize and actual failure.
Trying to beat Netflix
To finetune LLAMA models I will be using the Huggingface library to wrap my models. Additionally to optimize I will convert the original LLAMA model and weights into float16 precision (this can be pushed even further via quantizing to 8 bits). This helps in two following ways: 1) Using the Trainer module allows for easy distributed learning and device switching during training, which would be key in fine tuning any large model 2) Better integration with monitoring aka WandB 3) Better community support for potential issues and training/inference tricks. Compared to other experiments online done on a similar matter I want to approach it from a more scientific and quantitative perspective. Many claim LLMs are good recommenders but how does it look in practice? To do this I will be using MovieLens dataset.
The task in itself is simple given the user’s prior list of liked movies recommend me an N number of them. To make it consistent I will give the model 6 movies the user liked (to give more datapoints with semantic meaning) and ask for 4 back.
So let’s begin. First we want to process our dataset into a usable LLAMA format like so:
This gives us a processed dataframe that contains all best liked movies, so all we need to do is to create a large collection of training data in a specific format by providing an instruction, input, and output fields and then save it in a json format. For GPT models we can just combine instruction and input.

We then load the data and the model and train it. To do it efficiently I am utilizing the approach developed by Microsoft in 2021 from the paper LoRA: Low-Rank Adaptation of Large Language Models. To oversimplify: LoRa freezes pretrained weights of the model and injects special trainable rank decomposition matrices into each layer of the Transformer architecture within the model, greatly reducing the number of trainable parameters. After implementing LoRa we get a reduction of trainable parameters to roughly 0.06%. For 7B LLAMA model for example it was:
trainable params: 4194304 || all params: 6742609920 || trainable%: 0.06220594176090199
If you are using multi-node training you should use the Accelerate module from Huggingface or your own implementation using torch.distributed. I managed to train everything on a few A100 GPU’s, specifically 4 should be enough to load and train 65 LLAMA model. This requirement can be reduced by either quantizing the model or training it with mixed precision.
All models were trained for 10 epochs using AdamW optimizer on a dataset of ~17000 records where ~3000 were held out for evaluation.
The training and testing results are below:
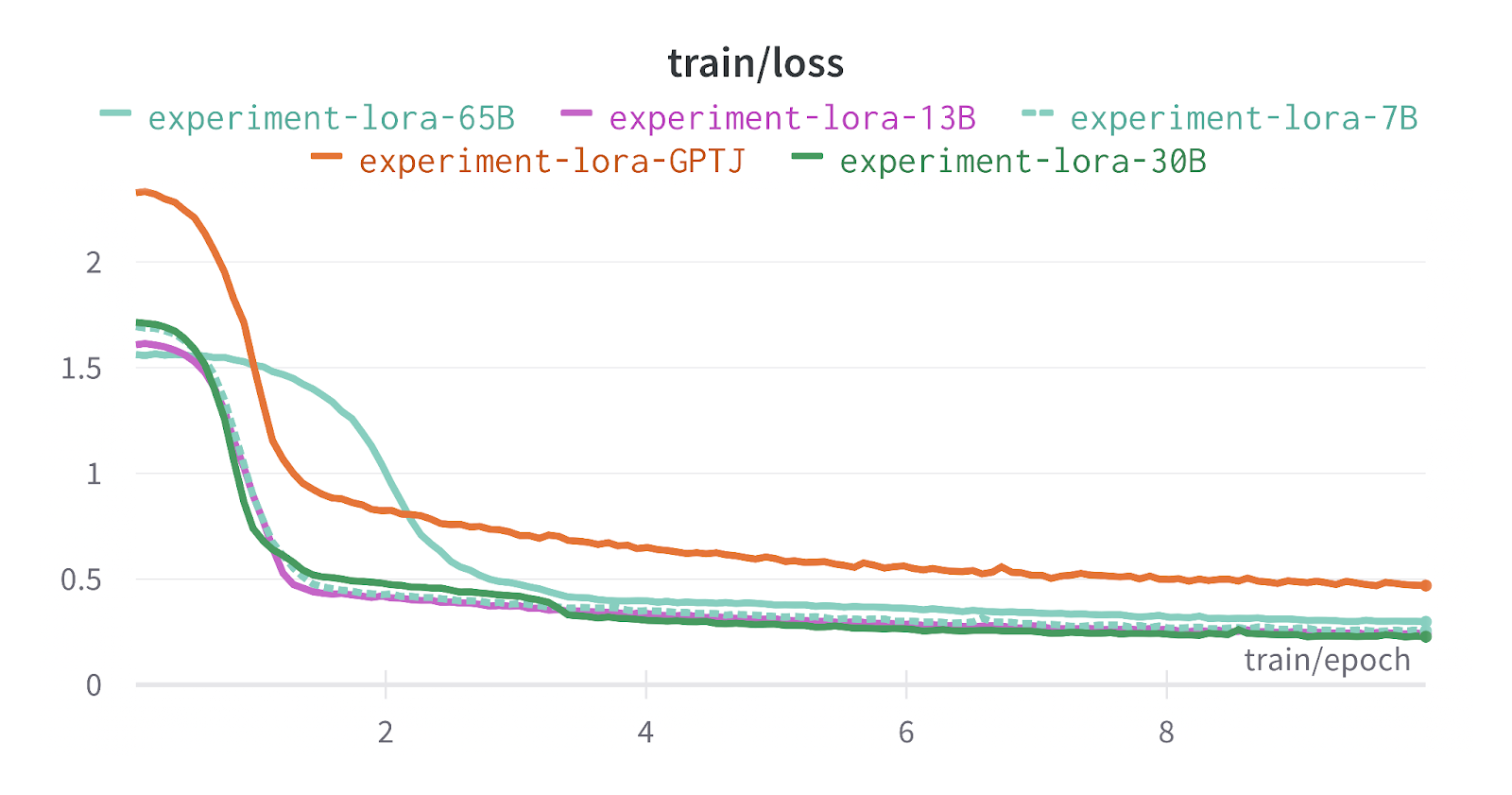
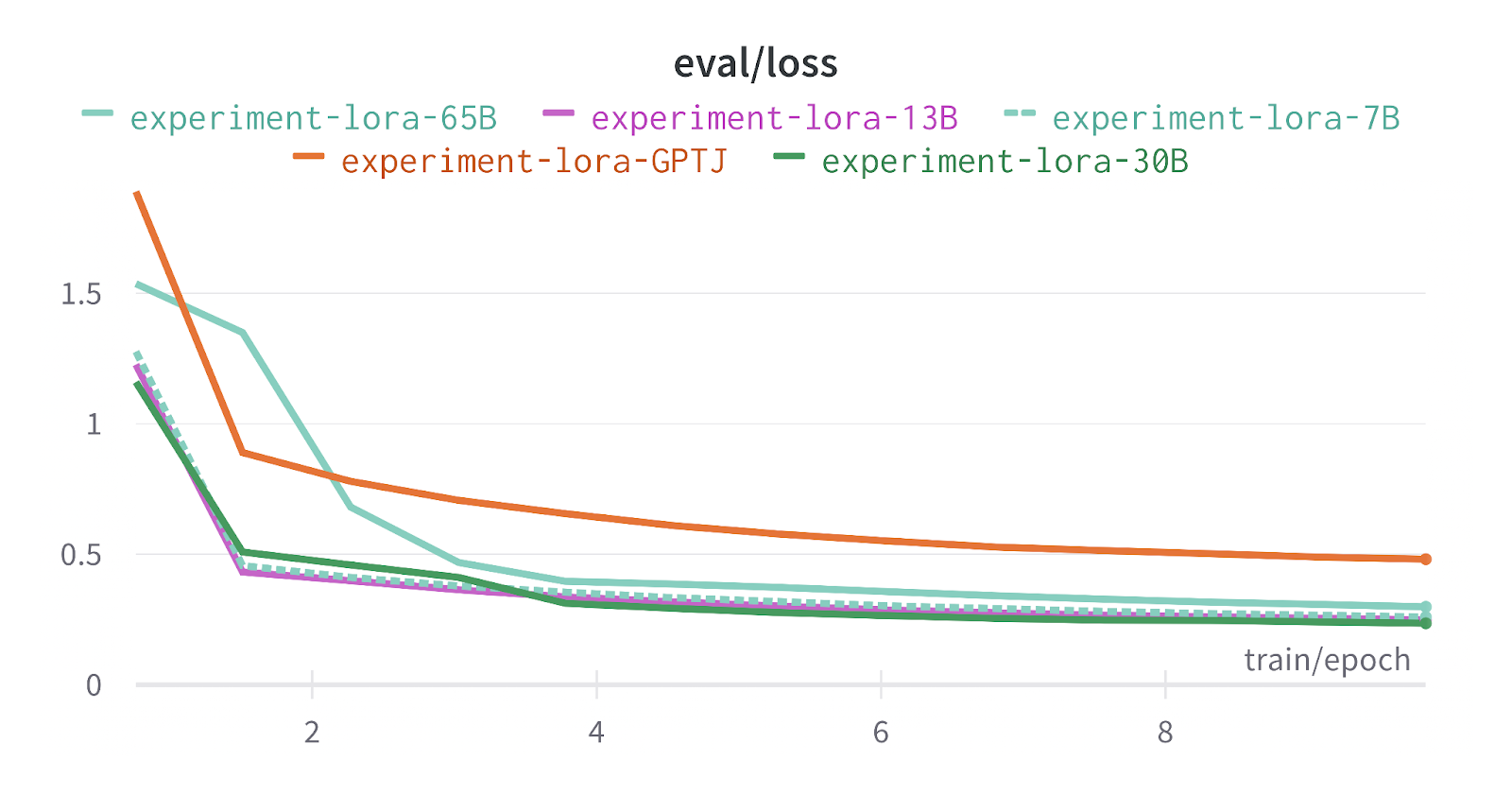
*Note: 65B LLAMA model has a slightly different graph from all other LLAMA models as it was trained on a cluster of V100’s instead of A100’s. x-axis is a number of epochs y-axis is loss
This looks good so far. We can see loss decreasing in a stable manner around epoch 1 and 2 and then evenly plateauing. After generating the results from finetuned models we can observe that they definitely learned the format and the task of recommending movie data. But unlike other hyped-up few experiments you might have seen on blogs and Twitter claiming that LLMs are new amazing recommendation systems, I want to take a scientific approach and statistically measure if they are any good on a more complex setting.
Checking LLM’s Homework
MovieLens is a good dataset for the following reasons:
- It is well known among the researchers and developers, therefore it is a good dataset to develop an LLM RecSys baseline.
- Distribution of items included in the dataset is more complex. The task would be easier if for example all movies matched the same genre or director or actor, but in reality many users like different movies from multiple time periods and styles.
- Since the dataset is systemized it is easier to derive statistical measures from it.
One good way to do this is to measure precision@k, more specifically MAP@K or mean average precision@k. Since we don’t have a standard binary task we can use precision definition used for the task of information retrieval, formula for which is below:
![]()
In our case relevant documents will be the original output for each prompt from the evaluation set and the retrieved documents of course will be the completed movies. We will treat items that are in the original completion as relevant and others as not. Since the output can hallucinate and is in string format we need to tune the generator and add some post processing. To be on the safe side I added the function that for each item the model spits out it will find the closest by the common character number. Ideally this should be done using embeddings and vector search based on similarity to leverage semantic information connected to each movie title, but for now we will assume that model learned the names of movies well and we will get very close matches. It can be done like so:

But on second thought this can cause issues with some other strings having more characters and as a result more common characters rather than the target string. To avoid this bug I will use a classic string metric calledLevenstein distance. This is based on the idea of

edit distance, TLDR: how many edits will it take me from “kitten” to “kitkat”, so if less editing is required the more similar the strings are.
In essence I will get an array of mapped movies -> [1, 5443, 321, 514] and compare it to the one model produces after parsing -> [1, 43, 321, 3513], then we measure precision according to formula and take a mean over the whole eval dataset.
So let’s run it and get the MAP@K scores:
Drumroll…
- GPT-J (6B): 0.005
- LLAMA-7B: 0.007
- LLAMA-13B: 0.018
- LLAMA-30B: 0.021
- LLAMA-65B: 0.019

Wait a minute… That’s not mindblowing. So should we just say that LLMs are not capable of recommending and that’s it?
Well… not so fast. While I deliberately chose a statistical approach for a scientific view there are few important points to consider:
- **Real life is different:**in it that all finetuned models recommended movies in a format I asked for, with a caveat that I had to use more expensive strategy aka beam search as compared to greedy search, this was done to stabilize the output (no odd words, sequences, characters) and to reduce hallucination. In real life the recommendation process is often less complex, when I repeated the same test as above with thematically similar movies all models did really well. Rec systems often have more parameters to go on from, so movie name and dating is not enough. Perhaps a movie description and extra tags to characterize the input would be better.
- **LoRA limits:**keep in mind that LoRA is only one of the strategies you can employ to make a recsys LLM. Two popular finetuning approaches are Adapters and RLHF (the way chatGPT was trained). The choice will depend on your data and application, adapters can be good for specific generations while RLHF is a good approach for diverse chatbots. You can also finetune the whole model but this has to be carefully executed since you do not want the model to forget or break.
- **LLMs are naturally more diverse recommenders:**in my experiments I found that on occasion the model would sometimes recommend movies outside the dataset and format them to the MovieLens format. This shows that compared to traditional paradigm of recsys LLMs have a better innate ability for discovery of new items and suggestions,
In Conclusion
So what do these results mean? I believe that LLMs show big promise in being. For production however, a layer of post processing will have to exist between the user and the model. A combination of traditional recsys and LLMs might give the best results akin to ToolFormer as an in ensemble. The results in this post suggest that we should not treat LLMs as wonder solution for all problems, and in production their potential needs to be carefully harnessed and tested, for example if we encode the movie descriptions and titles using these models and then perform a similarity search we can get good recommendations based on the similarity.
The potential is great, this post is just a first taste of things to come. Stay tuned for more to see our experiments to improve and change existing Recsys paradigms.
Interesting Observations
- Using characters like ‘(‘, ‘)’, ‘[‘, ’]’, ‘=>’ often prompted the models to write code as the completion, probably because these characters are very common in most languages, but I had a lot of Python completions specifically. Code would almost always be about movie recommendations, very ouroboros-like.
- Temperature value is the most impactful hyperparameter, for LLAMA models I found it to be especially sensitive, setting it too high made the model talk in a different language (or imaginary one). This is also dependent on the size of the model.
- By comparison to LLAMA GPT-J is an old model therefore its capabilities with pretraining may be lacking
- Might be a good idea to give both liked and disliked movies with corresponding prompts to push the model to adjust it’s latent space from both sides: increase probability in one -> decrease in the other
- MovieLens dataset has dates attached to each movie name, this is done as multiple titles can have the same name, sequels, different movies filmed across different timeline etc. However, it might have a negative effect: e.g. if all movies liked are from the 1990s the model can focus on recommending movies from the same time period rather than focusing on similar genres. Additionally having dates is another target of hallucinations, don’t be surprised if you see Star Wars (2025) recommended. One advantage of traditional RecSys is that it is largely not susceptible to hallucinations. Therefore some post processing is required.
- Large part of success of the LLM as a RecSys relies on the parameters of the generator, things like repetition penalty, sampling top-p and top-k values, and of course model temperature that determines closeness to the original prompt format and model “creativity” with its responses.
- Generator parameters hold almost equal importance to training parameters of your model. They require fine-tuning to produce constant stable output.
- There is a huge computational cost to evaluating the model using generative method versus evaluation during training. I encountered this when I was testing the model. Since I am using the generate method, what LLM needs to do is to find a way to search for most probable tokens. Rule of thumb is: more sophisticated the strategy is the better the results but also higher is the computational cost. Higher parameter count vs simpler search strategy is a fun experiment to explore.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.