Everybody knows the good ol’ 100k-MovieLens dataset. It’s easy to understand, and has obvious use-cases: it can be used to give movie recommendations to its users. There’s nothing hard about training a MovieLens-based model, but it’s an entirely different challenge to put this in production and keep it running at all times. The challenge is orthogonal to the challenge of just training the model.
Challenges
What kind of challenges are there with putting a MovieLens model in production you might ask? There’s a few:
- Run the hyperparameter tuning jobs in parallel to keep the runtime low irrespective of how many params are experimented with. This is something that’s hard to achieve on a development machine / Jupyter Notebook.
- Do the re-training on new data as fast as possible.
- Have automated daily re-deployments on new data.
- Creating a REST endpoint that can automatically scale up to thousands of requests per second and then scale down when it’s no longer needed.
- Security/privacy.
ㅤ
To put things into perspective, this is the MLOps landscape in 2023.
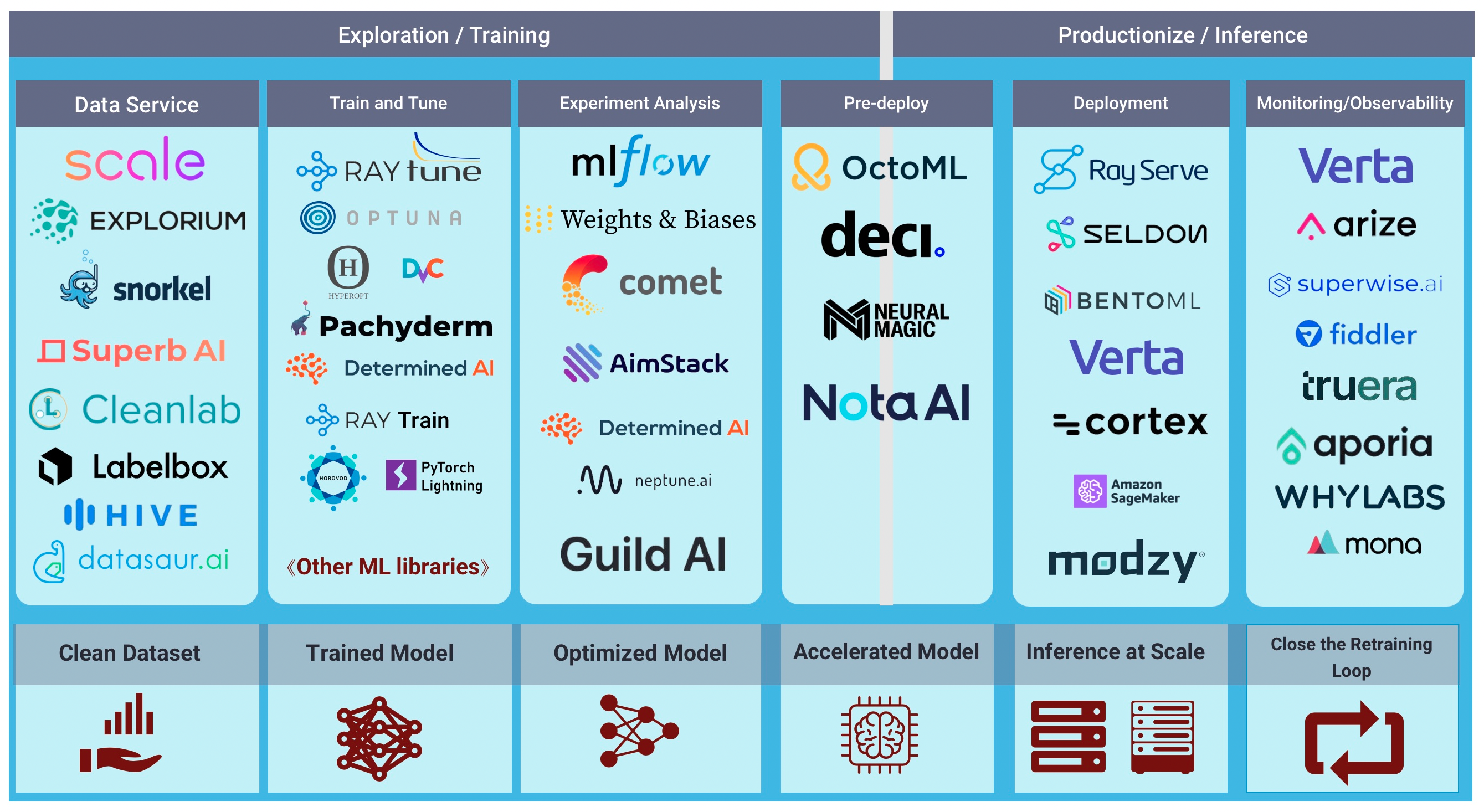
There are tons of tools and services that need to be used in concert to be able to get a dataset from zero to production. And when it comes to putting RecSys models in production and run them at scale and also support automatic daily re-deployments on new data, there’s not much on the market right now that would allow you to get started in less than half an hour.
ㅤ
On the downside, if one were to build such a system themselves, it would take many months to get something reliable out, and tinkering with a Kubernetes-based environment might also be needed. This is no job for a data scientist / ML engineer.
Alternative
![]()
Shaped products can come to the rescue. Shaped manages the whole lifecycle of a model starting with the fetching of the dataset up to the deployment of the model in production. All that’s needed is to provide the dataset, and Shaped handles the rest.
Now, full disclaimer: I’m the DevOps engineer at Shaped, so I might have bias towards this, but from my observations, Shaped is the only service in town that satisfies the previous requirements most efficiently.
In this following section, we’ll setup a model based on the 100k-MovieLens dataset and we’ll have it up and running in no time. This dataset contains 100,000 ratings from ~1000 users on ~1700 movies. With it, we’ll be able to predict the most likely movies each user will want to watch.
This tutorial will be shown using Shaped’s local dataset connector, but you can easily translate to any of the data stores or real-time connectors we support.
Let’s get started! 🚀
Download public dataset
To start off, let’s fetch the publicly hosted MovieLens dataset we’ll be training our model with.
wget http://files.grouplens.org/datasets/movielens/ml-100k.zip --no-check-certificate
unzip ml-100k.zipTaking a look at the downloaded dataset, there are three tables of interest:
- ratings which are stored in ml-100k/u.data
- users which are stored in ml-100k/u.user
- movies which are stored in ml-100k/u.item
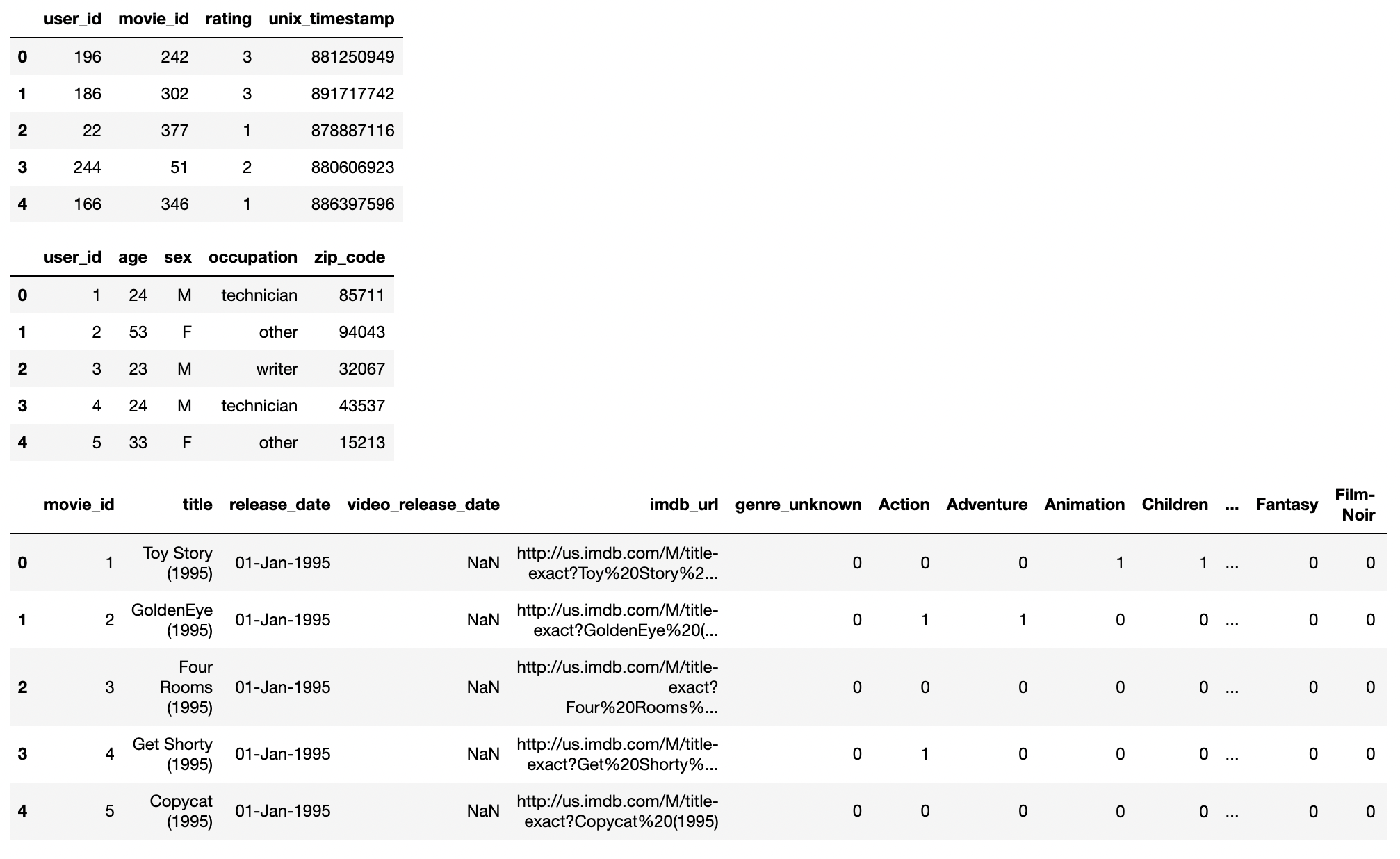
Unfortunately each of these tab separated files don’t have a header (which is required by Shaped). To address this, we can prepend the header with the following command:
(echo "user_id\titem_id\trating\ttimestamp"; cat ml-100k/u.data) > ml-100k/u.data_with_headerTo keep things as simple as possible, this tutorial only uses events to create the model, but if you want to use the user and item data as well, just prepend the headers in the same way.
Create MovieLens Shaped dataset
For this tutorial we’re going to be creating a Shaped Dataset and inserting the ratings records to it. To create this dataset, you first need to create a dataset definition which includes the schema as follows:
dataset_name: movielens_ratings
schema_type: CUSTOM
schema:
rating: Int32
user_id: String
item_id: String
timestamp: DateTimeYou can use this definition to create the ratings dataset with the create-dataset command using Shaped’s CLI:
shaped create-dataset --file movielens_dataset.yamlInsert ratings
We now want to insert the movielens ratings into the dataset, which we can do with the dataset-insert command.
shaped dataset-insert --dataset-name movielens_ratings --file ml-100k/u.data_with_header --type 'tsv'You’ll see the records uploading in batches of 1000, once it has reached 100k records you can move forward.
Create Shaped model
We’re now ready to create your Shaped model! To keep things simple, today, we’re using the ratings records to build a collaborative filtering model. Shaped will use these ratings to determine which users like which movie with the assumption that the higher the rating the more likely a user likes the rated movie.
ㅤ
Here’s the create model definition we’ll be using, and the corresponding create-model command.
model:
name: movielens_movie_recommendation
connectors:
- type: Dataset
id: movielens_ratings
name: movielens_ratings
fetch:
events: |
SELECT user_id, item_id, timestamp AS created_at, rating AS label
FROM movielens_ratingsshaped create-model --file movielens_movie_recommendations.yamlFor further details about creating models please refer to the Create Model API reference.
Inspect your model
It should take between 15 to 30 minutes to finish the fetching, training and putting into production the recommendation model.
While the model is being setup, you can view its status with either the List Models or View Model endpoints. For example, with the CLI:
shaped list-modelsResponse:
[
"models": {
"created_at": "2023-03-18T19:17:51 UTC",
"model_name": "movielens_movie_recommendation",
"model_uri": "https://api.prod.shaped.ai/v1/models/movielens_movie_recommendation",
"status": "FETCHING",
}
]As you see the model is currently fetching the data. The initial model creation pipeline goes through the following stages in order:
- SCHEDULING
- FETCHING
- TRAINING
- DEPLOYING
- ACTIVE
You can periodically poll Shaped to inspect these status changes. Once it’s in the ACTIVE state, you can move to next step and use it to make rank requests.
Fetch your recommendations
You’re now ready to fetch your movie recommendations. You can do this with the Rank endpoint, just provide the user_id you wish to get the recommendations for and the number of recommendations you want returned.
Shaped’s CLI provides a convenience rank command to quickly retrieve results from the command line. You can use it as follows:
shaped rank --model-name movielens_movie_recommendation --user-id 1 --limit 5{
"ids": [
"134",
"408",
"484",
"483",
"86"
],
"scores": [
0.9,
0.8,
0.7,
0.3,
0.2
]
} The response returns 2 parallel arrays containing the ids and ranking scores for the movies that Shaped estimates are most interesting to the given user.ㅤ
If you want to integrate this endpoint into your website or application you can use the Rank POST REST endpoint directly with the following request:
curl https://api.prod.shaped.ai/v1/models/movielens_movie_recommendation/rank \
-H "x-api-key: {api_key}" \
-H "Content-Type: application/json"
-d '{
"user_id": "1",
"limit": 5,
}'Clean up
Don’t forget to delete your model once you’ve finished with it, you can do it with the following CLI command:
shaped model-delete --model-name movielens_movie_recommendation