A history lesson
Since the origins of writing more than 5,000 years ago, people have tried organizing information in order to be able to easily access its various elements. The first known of these attempts can be seen with examples such as the earliest records of libraries.
As the volume of information has increased throughout history, this has encouraged the development of structures that facilitated quick searches from a given collection of data. With the advent of computers, indexes of large volumes of data could begin to be generated automatically, and as such, the science of search, or information retrieval was born.
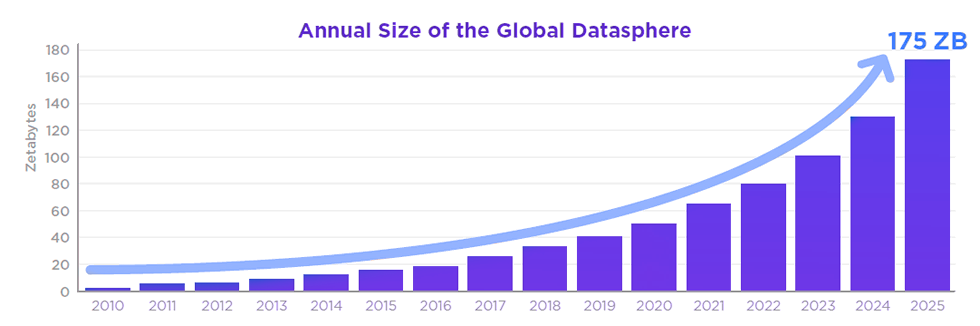 Results of astudyfrom theIDCreflecting the annual increase in size of digital data. The application and research of information retrieval is key to ensure that this data can be easily accessed by companies and Internet users from all around the globe. (Fromhttps://www.nutanix.com/theforecastbynutanix/technology/data-protection-in-the-enterprise)
Results of astudyfrom theIDCreflecting the annual increase in size of digital data. The application and research of information retrieval is key to ensure that this data can be easily accessed by companies and Internet users from all around the globe. (Fromhttps://www.nutanix.com/theforecastbynutanix/technology/data-protection-in-the-enterprise)
What is information retrieval?
Modern information retrieval (IR) is considered a subfield of computer science that dates its origin to early work laid down by researchers from the 50’s and early 60’s. It deals with the creation of systems capable of retrieving and presenting information from a set of given resources in a way that is relevant to a user’s query.
Information retrieval has only been increasing in importance since the creation of the Internet. Web search engines handle and process an ever-growing ocean of data for our consumption, and e-commerce businesses are always looking to find the best methods to show off their products to their consumers.
.svg) The structure of a traditional information retrieval system.
The structure of a traditional information retrieval system.
A classic information retrieval process begins when a user enters a query composed of certain keywords into the IR system. This query represents a statement that summarizes the information that is needed, and it is used by the IR system to match and extract the relevant documents or items that have been previously indexed in its database (e.g with methods like inverted indexes). This approach differs from that of SQL-like queries for relational databases, as IR queries may or may not match, and the corresponding results in IR systems are ranked using heuristic methods.
How is information retrieval related to recommender systems?
While not all experts agree on it¹, the general consensus is that recommender systems (RecSys) fall into the category of information filtering (IF), and more generally, under the umbrella of information retrieval. As such, recommender systems can be seen as information retrieval systems that remove redundant or unwanted data from a certain stream of information. Through the contextual knowledge of their users, recommender systems provide suggestions for items that are ranked in such a way that is the most relevant to a particular user.
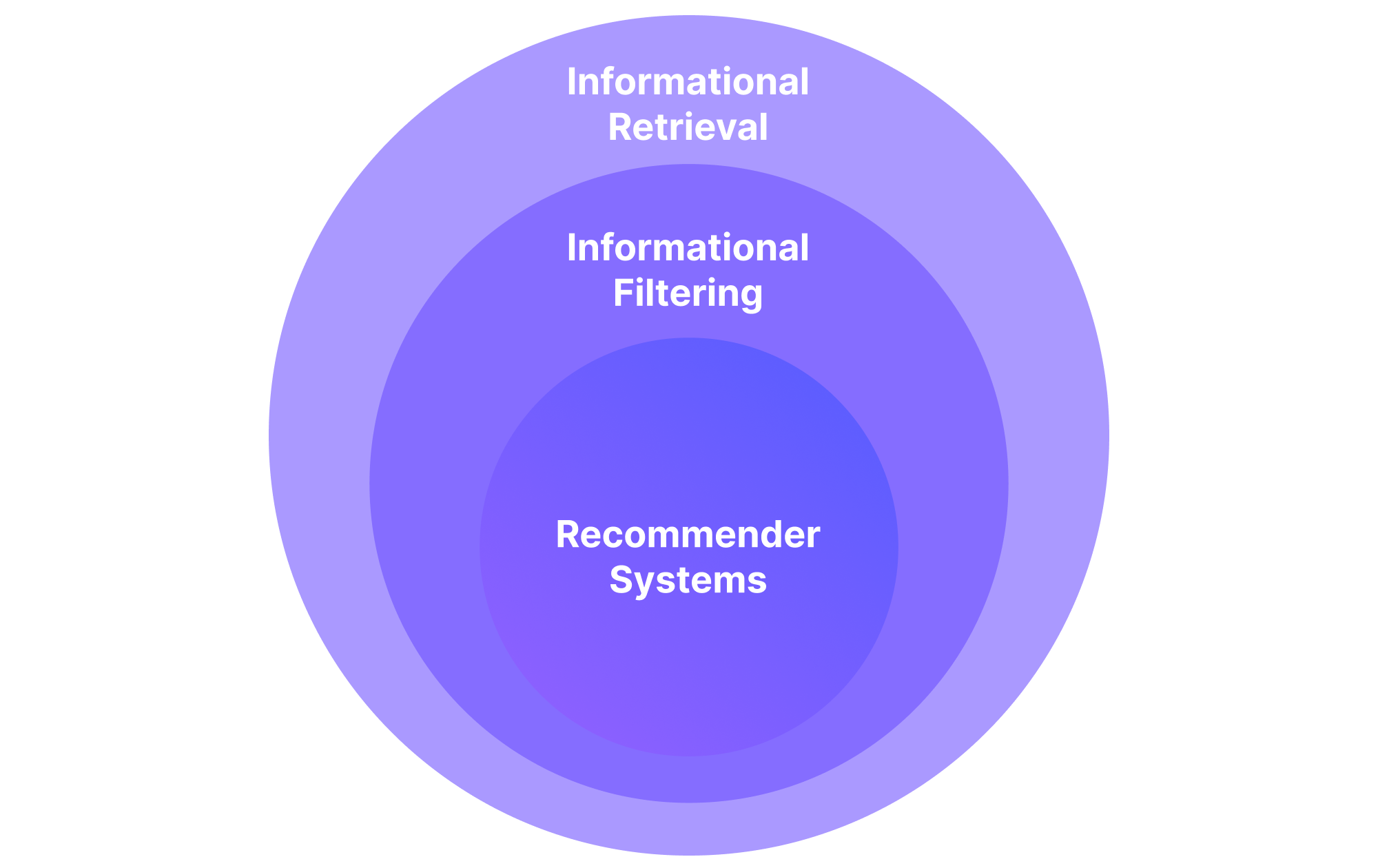 Onion diagram of the hierarchy between information retrieval and recommender systems.
Onion diagram of the hierarchy between information retrieval and recommender systems.
Another common way of defining the differences between information retrieval and recommendation systems is that, while the former responds to explicit demands from its user in the form of a query, the latter provides dynamic suggestions using the user’s profile. As such, in the case of RecSys, the query is implicit, and the recommender needs to be able to infer it from all the user-related data that is available.
Closing the gap between classic IR and RecSys
An important fact to take into account is that, while generally the use cases and technology between more traditional IR systems and RecSys are distinct, over the years more and more recommender systems have appeared making use of IR techniques and vice versa. For instance, since IR models are traditionally focused on generating a ranked list of documents, one can easily extend them to the creation of top-N based RecSys.
As an example, let’s take a dual usage approach of IR and RecSys. Think of a traditional e-commerce website. In it, the search engine is based on an IR system indexed on the products of the shop, while at the same time, a recommender system takes information from the user visiting the webpage and shows products at the sidebar that the system has considered that might be of interest to the user. Through this architecture, both types of systems are clearly separated from each other.
Now, let’s think of a more modern hybrid approach to IR and RecSys. Think of a web search engine like Google. While traditionally IR algorithms such as PageRank have been the backbone for organizing the results that are shown to the end user, modern web search engines make use of RecSys techniques to narrow down relevant search results based on the user’s personal information, such as age, localization or prior search history.
You may be wondering why until recent years this hybrid approach has not been usually followed by the industry. At its core, these models have been associated with a high level of difficulty in their construction. However, the rise of machine-learning has opened up the possibility of creating these systems through a more streamlined solution.
The power of machine-learning
The usage of machine-learning has enabled modern recommender systems to better understand the relationships and complex patterns within the available metadata that they access, and at the same time, implement IR techniques into their working pipeline to get more accurate ranking engines.
Through the usage of embedding models, different types of data can be easily understood and processed accordingly by RecSys. At the same time, continuous learning approaches make these models solid in production, as new information can be easily fed back to these models and sporadically retrained with it at a low cost. Furthermore, at inference time, IR techniques are able to be used to further narrow down ranking results. Currently, leading business models such as Amazon, Meta or Spotify are researching and making use of both IR and RecSys to boost the quality of the software that they produce.
Conclusion
Recommender systems are an important technology that we use every day, but it’s important to remember that they’re heavily rooted in the methods and systems from the field of information retrieval. Modern recommender systems are combined with classical information retrieval methods and make use of machine-learning to deliver powerful tools to developers.
Here at Shaped we offer an elegant and easy-to-use API to deliver state-of-the-art performance of modern recommender systems with the power of machine-learning, while keeping it simple and delivering an experience that eliminates the difficulties inherent in the construction of these systems.
Further reading
If you want to learn more about IR systems:
- Keep up with IR related conferences such as SIGIR, ECIR and ISMIR and join their Slack communities.
- Read books like “Introduction to Information Retrieval” by Christopher Manning, Prabhakar Raghavan and Hinrich Schütze or ”An Introduction to Neural Information Retrieval” by Bhaskar Mitra and Nick Craswell. Both are great beginners choices to dive deep into IR.
- Daniel Valcarce doctoral dissertation “Information Retrieval Models for Recommender Systems” is a great read and source of references to interesting papers in the area.
- Check out from time to time what researchers are doing at the IR category on arXiv.
📖 ¹ The similarities and dissimilarities between IR and IF systems have been widely debated in the literature. The majority of current authors tend to refer to the ideas laid in the work of Belkin and Cro (1992) “Information Filtering and Information Retrieval: Two Sides of the Same Coin?” as to why IF and as such, RecSys are considered as a part of IR. However, some older authors still prefer to refer to them as different but closely related fields due to their inherent dissimilarities. We highly recommend you to read the work from Belkin and Cro if you want to get a deeper understanding of this topic.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.