
Welcome back to the second installment on data requirements for recommendation systems! In part 1, we looked at the types of data used, the importance of high-quality interactions, and strategies for improving interaction signals. We highlighted that there is no minimum amount of data required for a recommendation system; instead, what matters is the quality of interactions and contextual information about users and items being ranked. In part two, we will explore the challenges posed by sparsity, discuss the significance of contextual information for enhancing recommendations, and examine the latest advancements in machine-learning techniques that are reducing data requirements for businesses of all sizes.
Sparsity
Sparsity refers to the amount of available data or the density of data points in a dataset. In the context of recommendation systems, sparsity can refer to the number of ratings or interactions that users have had with items. The sparsity requirements for recommendation systems can vary depending on the type of system and the goals of the recommendations. Some recommendation systems may be able to function effectively with relatively little data, while others may require a larger, denser dataset in order to make accurate recommendations. In general, it is generally easier to make higher quality recommendations when there is more data available.
One way you can unpack why higher quality recommendations are roughly proportional to interactions / (users * items) is looking at a classic collaborative filtering method: matrix factorization. In matrix factorization, you have a feedback matrix, where rows are users, items are columns and the cells contain the event label (e.g. positive event as 1, negative event as 0). You can think of the recommendation task as one where you need to predict the missing cells of this matrix. Matrix factorization solves this by learning a lower dimensional latent space that represents the feedback we do know, to predict the feedback we don’t. As you can imagine, the more sparse this feedback matrix is, the harder it is to predict the missing values. E.g. if 99% of the feedback matrix is complete with data then it should be much easier to predict what that 1% is. If we only have 0.1% then it becomes much harder.
 Matrix Factorization is a simple embedding model
Matrix Factorization is a simple embedding model
One rule of thumb that’s quoted as an ideal minimum anecdotally is that you need less than 99% sparsity of interactions relative to the user and item matrix to make good recommendations. Sparsity doesn’t necessarily change when you add any type of data. If you increase more users and items you’ll need exponential amount of interactions to have equivalent sparsity!

For example:
- 1000 users and 1000 items you need > 10,000 interactions.
- 100,000 users and 1000 items you need > 1M interactions.
- 1,000,000 users and 10,000 items you need > 100M interactions.
- 1,000,000 users and 100,000 items you need > 1B interactions.
But is this the whole story? Not at all. Minimum thresholds of data are a misnomer. In the example above, we set each row to represent a new unique user and each column as a new unique item, but this doesn’t consider all the shared attributes of the user and item entities — contextual information. These extra attributes provide another feature to represent similarity between users and between items.
💡Minimum thresholds are a misnomer.
Contextual information
Intuitively there are two ways we think about the improvement here:
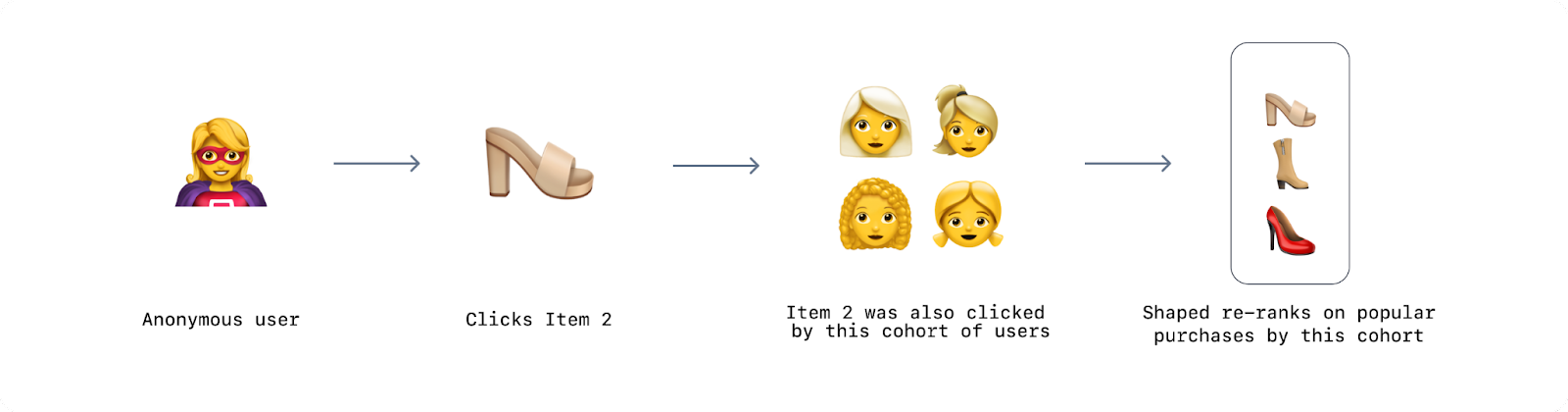
- Having a prior on the similarity of entities (users or items) based on the similarity of features, gives us more information about the relationship between users and items before they’ve made many interactions. For example, if an anonymous user is added, and they click on an item that’s popular with women in their mid-30s, we can start off by recommending them something that we know other female’s in their mid-30s like. If an item is added, and we know it’s red, and a type of shoe, can we recommend it to people that like things that are red, or shoes!
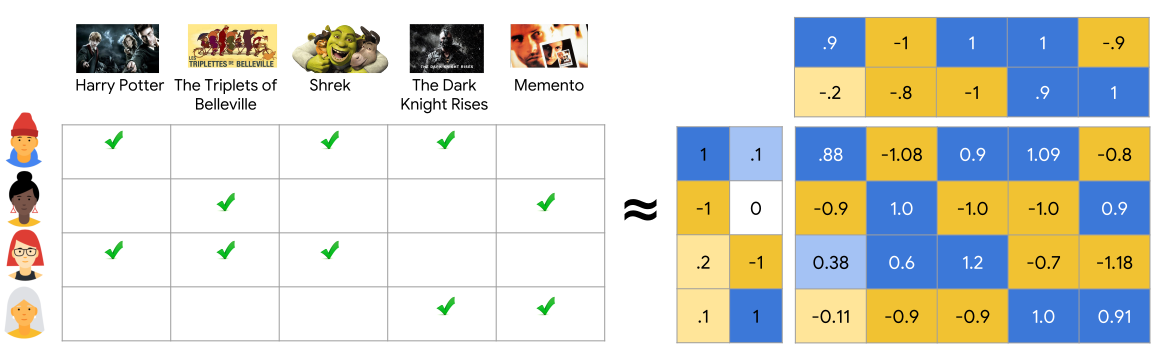
- Having extra user or item features means there’s more ways to relate the interaction relationships together. If we take the matrix factorization example again, one way to handle these attributes is to just concatenate them to the sides of the matrix (by the way, this is why user and item attribute features in recommendation systems are often called “side-information”). If we now fill in the feedback matrix of the new attribute rows and columns with their respective interaction values, assuming the cardinality of the features is less than the number of interactions (which is guaranteed), and we use the same number of interactions, this feedback matrix must be more dense then the original feedback matrix without the attributes.
 Fig. 1. Example of contextual or ‘side information’ excerpted from Movielens dataset
Fig. 1. Example of contextual or ‘side information’ excerpted from Movielens dataset
This all comes with a lot of caveats, which is why there’s never an answer of exactly how much data you’ll need. But what we can conclude is that quality of recommendations is correlated with the number of high quality interactions and amount of high quality contextual information.
One recent advancement in recommendations systems is big tech companies using deep learning to extract high quality contextual information from the content itself. For example, their recommendation systems understand whether a video is dancing (see below),keyboard cats orsports highlights without any additional metadata.
 An example of avideo understanding modelwe use at Shaped to add high quality contextual information to recommendations
An example of avideo understanding modelwe use at Shaped to add high quality contextual information to recommendations
As you’d expect deep learning has high initial data requirements for model training. For example, foundational large language models (LLM) likePaLM andGPT-4 required billions of data points, many machine-learning engineers and huge compute power to train over many months. With that in mind, it might seem as though the bar to deploy a modern recommendation system with deep learning into production is only getting higher.
Latest innovations in machine-learning
Thankfully the opposite is occurring! 🙃 These innovations have reduced the minimum data requirements and made it easier than ever to get started. LLM have enabledtransfer learning to other contexts and use cases — which is likely to include whatever you’re building! For example, a pre-trained model on out-of-domain data (for example public or purchased datasets) means you need less unique domain specific data to get good results. In an effort to build community, companies like Meta are even open-sourcing their advanced video deep learning models ongithub or publishing them onHugging Face. Transfer learning means we can literally stand on the shoulders of these giants. We no longer need gigantic datasets (or technically any data at all) to use deep learning in production.
At Shaped we use a combination of pre-trained models, traditional, and deep learning techniques to get the best performance possible for each customer. This means anyone can get started today with much less data than was required previously!
Unlocking the potential of your existing data
It’s essential to recognize that the data you need for your recommendation system might already be at your fingertips, hidden within various tools and platforms. For example, tools like Google Analytics and Segment are often underutilized as sources for recommendation systems. By tapping into these rich data sources, you can uncover valuable user interactions, such as page views, clicks, and dwell time, that provide crucial insight into user preferences and behavior.
Moreover, you can leverage other data sources such as CRM systems, which hold a wealth of customer information including demographic data, purchase history, and engagement with marketing campaigns. By integrating this data into your recommendation system, you can enhance the user experience with personalized recommendations based on a more holistic understanding of their preferences and interests.
Conclusion
In conclusion, the age-old question of “How much data do I need for a recommendation system?” doesn’t have a straightforward answer. However, what we do know is that the quality of recommendations is closely tied to having high-quality interactions and rich contextual information. As machine learning and deep learning innovations continue to advance, the data requirements for building powerful recommendation systems are becoming increasingly accessible for businesses of all sizes.
So, don’t let the fear of not having enough data hold you back from implementing a recommendation system that could significantly boost your conversions and user engagement. By leveraging pre-trained models, transfer learning, and existing analytics tools, you can harness the power of your data to create personalized and effective recommendations for your users. You likely have much more data than you think, and the benefits of a recommendation system are just waiting to be unlocked!
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.