
This post explains why this is happening and — if you’re building a recommendation engine yourself — how you can combat it.
Recommendation models are trained on past interests
Models trained and evaluated on what you already like. Consequently, the model will be rewarded to recommend similar items compared to your previous interaction preferences. The problem here is that a naive algorithm will get stuck by only recommending your past preferences and not exploring new content or your new potential preferences.
Most AI algorithms being used today use historic data to train and evaluate, a facial recognition system trains on millions of images while keeping random sets (validation & test) to measure their ability to generalize to unseen data. This also happens in recommendation systems, where the system is often trained on your past interactions, keeping some out of the training set to evaluate the model later on.
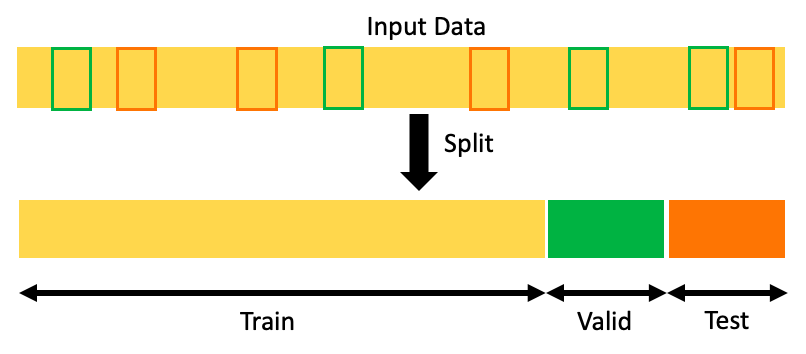 Random train/val/test split
Random train/val/test split
This method does not account for the evolution of user preferences over time as it randomly selects the sets. Recommendation systems will often add an extra test to sort chronologically and select only the latest interactions from each user as val/test sets, this way the systems are evaluated on the “latest” user preferences.
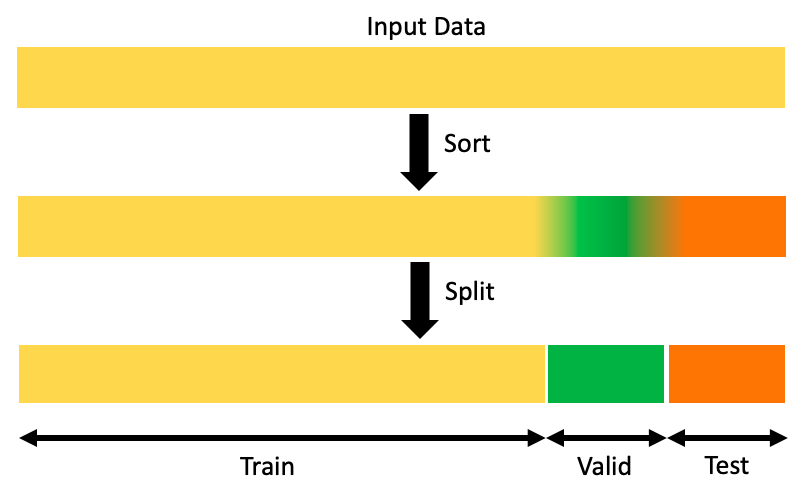 Chronological train/val/test split
Chronological train/val/test split
This makes sense right? The model will be better trained to suit your latest preferences. Well, problems rise when these feeds are used for long periods of time and the test set becomes the output of previously trained models, the latest user interactions are coming only from the personalized feed. This means the models will be testing themselves on their previous outputs, which were probably the only option in the user feed.
Left unchecked, models will converge to a bubble - recommending the same content while training metrics slowly increase. This phenomenon is called filter bubbles or echo chambers, users are constantly trapped in information bubbles.

A filter bubble is the intellectual isolation that can occur when websites make use of algorithms to selectively assume the information a user would want to see, and then give information to the user according to this assumption.
Websites make these assumptions based on the information related to the user, such as former click behavior, browsing history, search history, and location.
What can be done to avoid this from happening
There are several methods to avoid this from happening, or at least diminish its effects.
Actively promote new or low interacted items
- If the same items are always being recommended, can we break the chain by pushing new or random items to the top of the feed? Makes sense right?
- This is what is commonly done in the reordering step of a recommendation system. Where items that have not been highly ranked are given a second chance to make it to the top of the list. Several heuristics can be used here such as item age, recent popularity, or even randomness. All with the intent of keeping the results fresh and personalized.
- This isn’t a silver bullet but can still dramatically reduce the likelihood of users entering a bubble in their feed.
Serving multiple models together
- Combining different recommendation systems to populate the feed, this way the feed and results will come from several sources. Each system can be optimized toward different metrics, keeping the feed fresh. An example could be combining a system that looks at your browsing data with one that focuses on your demographics.
Focus on long-term impact instead of short-term rewards.
- Since these systems only look at whether you click or not their recommendations (short-term view) why don’t we look to change to a long-term view? What is the service usage of users over multiple months?
- Measuring the activity of users over time and their responses to the system can help detect these filter bubbles, and incorporating these metrics in our model training will likely help.
In my experience, a combination of the three solutions is often the best —this is how it’s done at Shaped. The first and second are relatively easy to do while the third is very tricky to measure as there is a lot of work in denoising user activity over long periods of time.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.