(Title image from Even Oldridge and Karl Higley’samazing blog post)
We’re excited to announce several features that make it easier to create highly engaging ranking models configured to your marketplace or media platform use-case. Before getting into those, we’d like to explain a bit about how Shaped works internally:
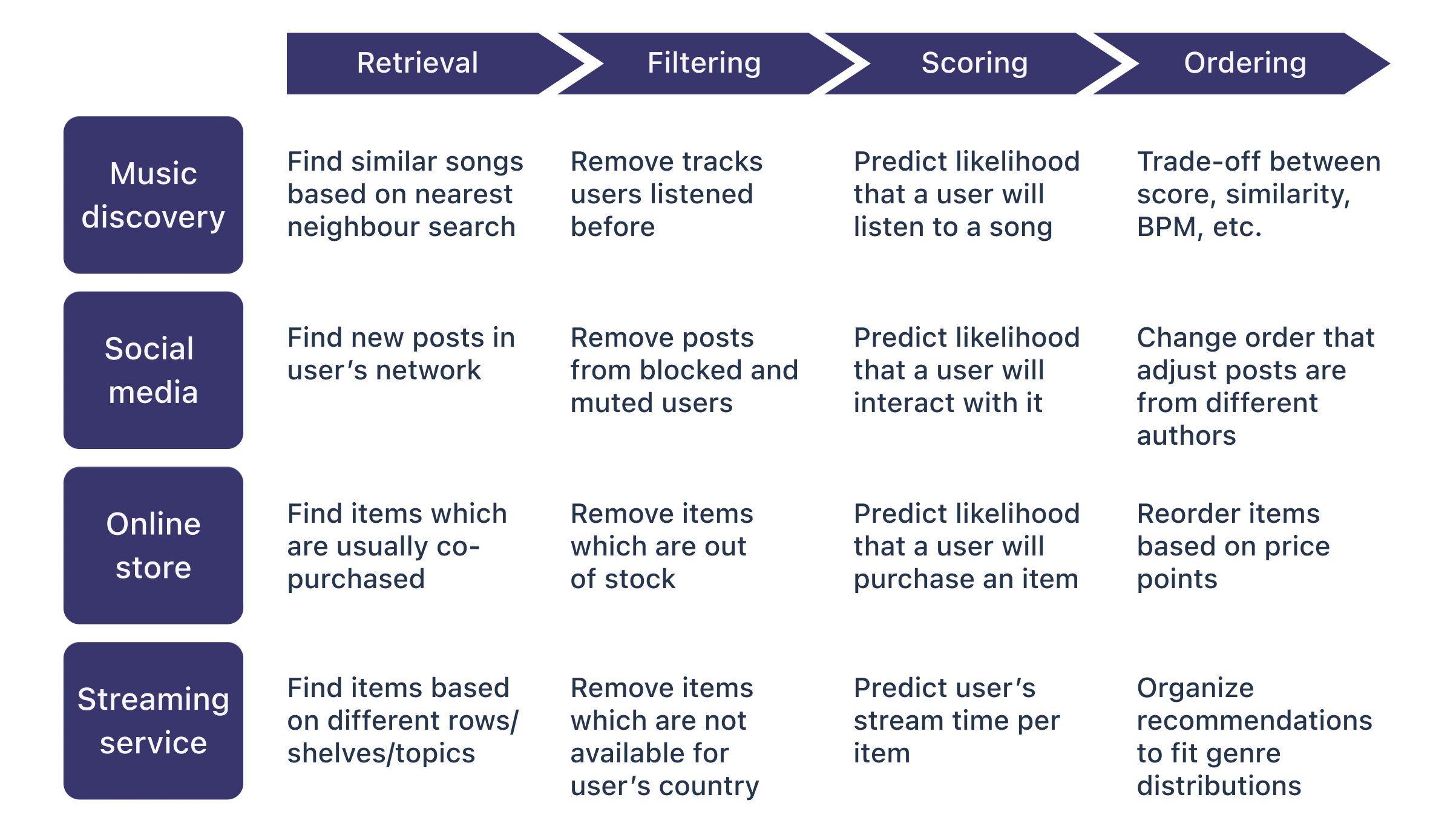
Shaped’s ranking architecture is composed of 4, real-time stages:
1. Retrieval stage: retrieves the candidate items that are ranked for the user. For the majority of our use-cases we use a light-weight collaborative filter model which learns from your users interactions to find the top most relevant items for each user.
2. Filter stage: filters out any candidate items that have a hard constraint on removal. For example, items that the user has already viewed.
3. Scoring stage: a scoring model is used to decide the confidence that the user will engage with each item in the candidate set. It’s an expensive operation that provides better estimates of relevance than the retrieval stage by using more signals, like user or item contextual information.
4. Ordering stage: the final stage decides, given the scores, how to order the final ranking. A naive ordering will just sort the scores, but to avoid filter bubbles, bias and handle the exploration vs exploitation problem, we intelligently add some indeterminism to the final ordering.
*Why am I telling you this?*
Well, traditionally, Shaped has configured these stages by looking at your data characteristics (schema, volume, cardinality etc…) and determining what’s best for your use-case. However, we’ve realized that to create the most value for our users, we need to expose how these stages are configured to give users direct control over their business objectives. Users need flexibility to choose things like what items are filtered, how these items should be retrieved, and most importantly, what specific objectives should be optimized? (e.g. what is the balance for creator vs consumer engagement?). This brings us to today’s announcement…
Introducing Shaped’s Model API
We’re excited to be launching Shaped’s “Model API”. The Model API allows users to configure all the aforementioned options using a simple request and a bit of SQL.
Retrieval & Filtering
The retrieval and filtering configuration API allow you to provide both global and personalized SQL queries that define what candidate items should be ranked for each user. By default we rank all the sourced items that we train on, however, here are some examples of when you might want to use custom filters:
1. Global filter — Your app has a “Discover” page that recommends both online and in-person meetup events. You want Shaped to filter out all events that are online (but train on both online and in-person).
2. Personalized filter — Your app has a “Discover” page that recommends movies to watch. You want Shaped to train on all interaction data, but only return movies the user hasn’t previously watched, or if they have watched it, only recommend it if it’s saved to their favorites.
3. Global and personalized filter — Your social media app has a “For You” feed that serves curated posts to your users. You want Shaped to train on historic interaction data, but only return posts that have been interacted with in the last 2 weeks (global) and nothing the user has already interacted with (personalized).
Scoring
Using Shaped you can configure whatcontextual signalyou want to train and use with your scoring model. There are lots of reasons why this is helpful, for example, if you listen to songs on Spotify the genre of the music is a contextual feature that might be key to why it’s relevant to you.
One of the main reasons contextual features are important is that they combat the cold-start problem. This happens when a new item or user is introduced into the system and does not get recommended due to having no interactions. When we use contextual features we are able to learn information that isn’t dependent on the user/item specifically but that can be generalized across your data.
As an example, let’s dive into how Airbnb promotes new listings: Airbnb has millions of rental listings and many of them come and go over time. How does Airbnb decide to promote these new listings specifically to you? They learn from the contextual features of the listing itself! In this post, Mihajlo Grbovic shows an example of how important location context is for their recommendations.
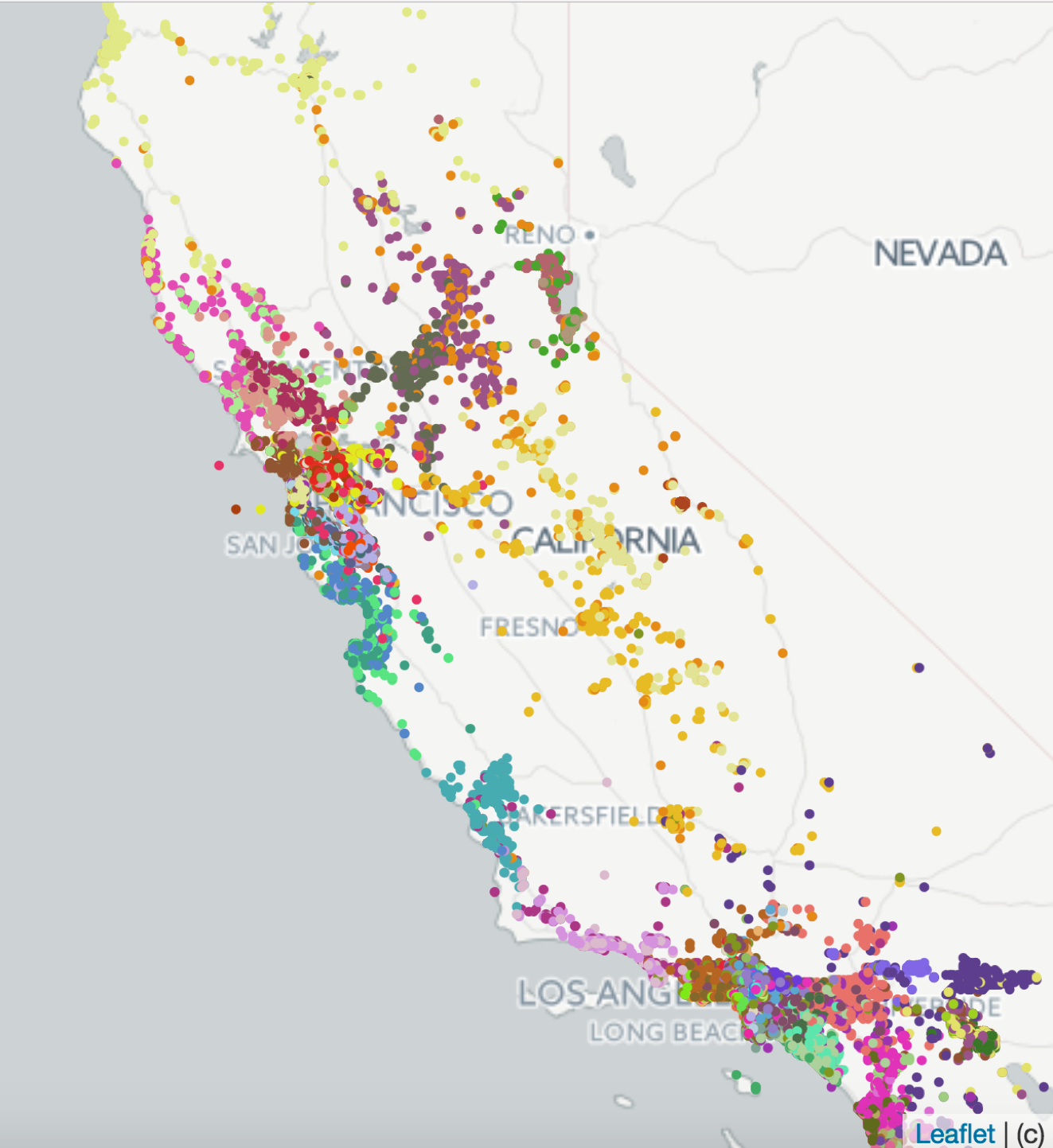 In this image fromAirBnB’s post, we see that item similarity embeddings belong to the same location cluster (for example the north coast of Los Angeles is mostly purple). This means when a new listing is added, a contextual location feature can be fed to the model, and this context can be used to better recommend the listing based on that location. For example, if the user is likely to prefer listings from the Los Angeles north coast, the ranking model knows to promote new listings in that area despite not having much interaction data.
In this image fromAirBnB’s post, we see that item similarity embeddings belong to the same location cluster (for example the north coast of Los Angeles is mostly purple). This means when a new listing is added, a contextual location feature can be fed to the model, and this context can be used to better recommend the listing based on that location. For example, if the user is likely to prefer listings from the Los Angeles north coast, the ranking model knows to promote new listings in that area despite not having much interaction data.
Reordering
Finally, as part of this release we’ve exposed a parameter called, “exploitation factor”, as a configuration to the reordering stage. This allows you to choose a value between 0 and 1 that defines how much you want the ranking algorithm to explore new content/products vs exploit the items that we have high confidence will be engaging to that user.
Our 2-sided marketplace beta customers have found that tuning this parameter is a trade-off between consumer engagement increase(as exploitation factor approaches 1) and creator engagement increase (as exploitation factor approaches 0). In practice, you want to choose the exploitation factor that balances these best for your business goals. It’s also worth noting that tweaking this parameter affects the algorithms diversity, and is important to avoid filter bubbles (see this post where we dive more into this).
Future
We’re excited to see what kinds of ranking models you’ll create with this extra customizability. We’re already seeing more use-cases than we originally thought (personalization is literally everywhere) and we hope that continues. Keep following along as we have a ton of new improvements in store this year — we’re just getting started! Get in contact at hello@shaped.ai if you’re interested in trying out our API for your own discovery use-case or want to help build Shaped.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.