
Browsing behavior is everything you do on web pages: clicks, scrolling, purchasing, and watching content. These are what we call “events” or “interactions” in the recommendation space, they are signals between a user (you) and the interacted content. Commonly these signals have been presented as user-item pairs by models to learn user preferences and later be able to produce recommendations to users.
 Traditional interaction matrix/
Traditional interaction matrix/
In the past couple of years, the industry has shifted to model the ordered list of interacted items by the user instead of user-item pairs. This means that the interactions are now presented as a list where order represents the time interactions occurred, often called session-based recommendations.
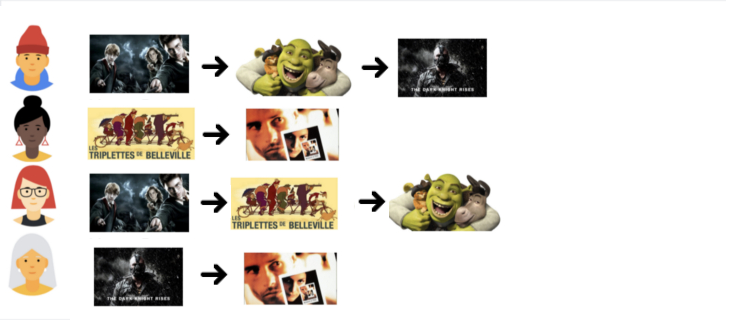 User interactions as an ordered list.
User interactions as an ordered list.
And what field has been gaining popularity during the last years and models problems as an ordered list of tokens? Natural Language Processing (NLP)! Thanks to their recent breakthroughs in machine translation, speech recognition, text synthesis, and large language models we now have models capable of learning intrinsic relations between tokens of a sequence. When we speak, we produce a list of words in which order is crucial to provide them with meaning.
The recommendations industry has been taking advantage of these NLP advancements and has been treating user lists of interactions as text. Using the same models in translation, speech recognition, or even text generation. This allows them to quickly learn what your browsing intentions are as these models are susceptible to the most recent interactions. An example of this is Netflix [1], where they use session-based models to quickly adapt to what you want to watch.
Let’s say you have watched hundreds of action movies on Netflix but just happens to be you are watching episode 4 of Friends, what is it most likely you will watch next?
- Another action movie.
- Episode 5 of friends.
Most likely episode 5, episodes are usually watched sequentially. This is a simple example but shows how personalization often performs best when it looks at the most recent data.
[1] - https://arxiv.org/pdf/2206.02254.pdf
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.