The widespread success of ChatGPT has launched a new wave of interest in large language models. If you are on Twitter you may have noticed how people impressed by the capabilities of ChatGPT herald a new age of AI and many use this as a marketing opportunity for their products fueling the hype. But being a researcher taught me that it is important to look at new technology without the rose glasses. And even with impressive LLMs, their issues are just as significant.
When training language models, we aim for them to produce natural-sounding text. OpenAI introduced RLHF (reinforcement learning from human feedback) through InstructGPT and ChatGPT to ensure the models generate text that aligns with human expectations. However, RLHF does not guarantee that the models verify the accuracy of their outputs.
Recently, Microsoft released the public beta testing version of their new Bing AI search engine. Users who have signed up and received invitations can now interact with the chat-based search engine. While it does use web search to retrieve information and generate text based on it, it still produces false information when there isn’t enough data available. Although it represents a step in the right direction by incorporating more factual information, relying solely on web search doesn’t seem to be sufficient and it rather looks like a patch on the problem.
A recent paper by Meta AI presents a solution that allows LLMs to use external tools via simple APIs, achieving the best of both worlds. Toolformer integrates a range of tools, including a calculator, a Q&A system, two search engines, a translation system, and a calendar. Today we will do a deep dive into this cutting-edge framework and see how it can solve crucial LLM problems.
What’s wrong with the best LLMs?
When using ChatGPT I have, for example, asked information about the newest tools or developments in the field. However, more often than not it will hallucinate, giving me non-existing methods, facts, and citations. For example, when talking to ChatGPT about recent trends in federated learning I asked it to cite a study it was referring to while talking about FL in healthcare:

💡 Journal of Medical Systems does indeed exist but the study and authors do not! If you remember Meta’s Galactica model and you had a chance to try it out, the example above is one of the reasons the demo was pulled from the web.
Well, perhaps another reason that the scientific community is way stricter compared to your average user when it comes to erroneous output and theories. If a model manages to write convincing but pseudoscientific papers that can be seen as dangerous
Researchers at Meta AI noted that in the majority, large models (albeit their impressive results) struggle with basic functionality like arithmetic or factual lookup, whereas smaller and simpler models perform better. Specifically, LLM problems can be listed as:
1. Inability to perform precise calculations due to a lack of mathematical skills
2. Limited awareness of the passage of time (you can ask a chatbot about current dates and times)
3. Difficulty accessing the latest information about current events
4. Tendency to generate false information or hallucinations
4. Challenges in understanding low-resource languages (try using ChatGPT in another less available language)
5. Architectural limitations of LMs and large models, in general, make it impractical to feed new data in order to solve specific hallucination issues, additionally feeding a large new corpus to the model can often cause it to forget already previously gained knowledge this coupled together with the cost of model retraining motivates a search for a simple and efficient approach.
And how to fix it
So how to address these issues? Let’s say instead of using plain web search in hopes to achieve a factually correct result while also trying to generate an appropriate text and at best ending up with two pieces of information that might agree or disagree with each other, we could have a model that when recognizing a specific query will find the useful and correct information.
💡 If you are a developer building a financial product you likely would want access to correct real-time information about the market, this means you would likely use an API. Modern apps or software rely on a vast variety of APIs to bring and send vital information. We can view them as tools in a toolbox.
APIs can do a lot of things which means for engineers there are a lot of capable tools.
And wouldn’t it be nice if the model knew how to use those 🤔? This is the key behind the Toolformer, which learns a way to use these tools in real time providing a natural pipeline for responding to various queries. So how does it do it?
Toolformer’s approach
To understand the solution we must start with the key technique researchers used called ICL or In-Context-Learning.
ICL refers to a type of machine learning approach where the model learns from examples that are presented within a specific context or environment. The goal of in-context learning is to improve the model’s ability to understand and generate language that is appropriate for a given context or situation. For example, in a natural language processing (NLP) task, a language model might be trained to generate responses to specific prompts or questions. So how do we make it work for the API?
There are 3 steps in the training process of the Toolformer:
- Sampling API calls
- Executing them
- Filtering operation
Researchers have noted that there are very few datasets that provide natural API calls. To address this and with the goal of providing a model with an idea of what an API call is, they first used a language model to generate some example API calls from prompts.
 An exemplary prompt P(x) is used to generate API calls for the question-answering tool.
An exemplary prompt P(x) is used to generate API calls for the question-answering tool.
From the figure above we want the model to keep generating API calls that help to fully answer the question.
This way we can take a dataset of inputs and annotate it with API calls. However, you might see the problem already, it’s not a guarantee that API call the model generates will be accurate or appropriate. We want calls to be set up in a way that gives the best answer so naturally, we need to filter them.
💡 Note that I don’t point to an exact language model in this case, in the paper the methodology is built around a model M, this is done in order to generalize the approach to big and small language models with different architectures. Toolformer is better conceptualized as a framework wrapper around your model of choice.
Elegant Filtering
Before we filter out the samples we need to see how accurate the responses from API calls are, hence we want to execute the calls. This is done entirely outside the model. And as for API calls how the execution is done depends entirely on the API itself – for example, it can involve calling another neural network, executing a Python script, or using a retrieval system to perform a search over a large corpus of data.
The key bit is that we are getting a text sequence r_i for some call c_i.
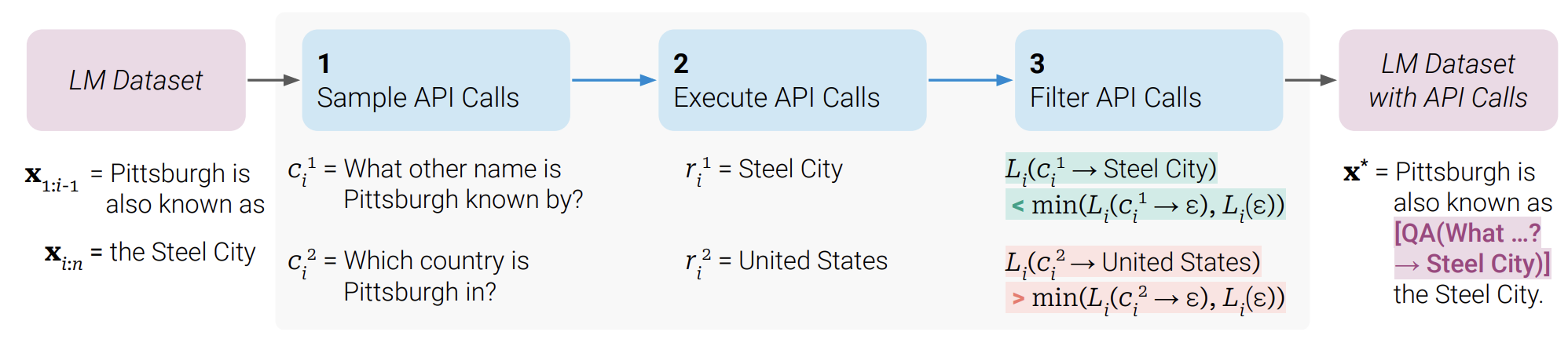 An example that illustrates a filtering procedure for a question-answering tool: Given an input textx, first we need to sample a positioniand corresponding API call candidatesc. We then execute these API calls and filter out all calls which do not reduce the lossLover the next tokens. All remaining API calls are interleaved with the original text, resulting in a new textx.*
An example that illustrates a filtering procedure for a question-answering tool: Given an input textx, first we need to sample a positioniand corresponding API call candidatesc. We then execute these API calls and filter out all calls which do not reduce the lossLover the next tokens. All remaining API calls are interleaved with the original text, resulting in a new textx.*
An example that illustrates a filtering procedure for a question-answering tool: Given an input text x, first we need to sample a position i and corresponding API call candidates c. We then execute these API calls and filter out all calls which do not reduce the loss L over the next tokens. All remaining API calls are interleaved with the original text, resulting in a new text x*.
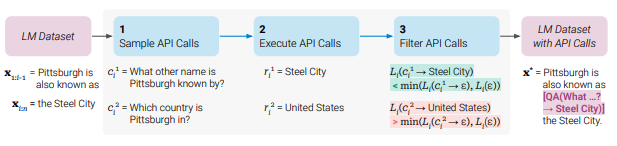
The language model dataset includes the phrase “Pittsburgh is also known as the Steel City”, which serves as a sample text for the model. When prompted with “Pittsburgh is also known as”, the model must generate an API call to correctly identify the answer, which in this case is “Steel City”.
To evaluate the model-generated API calls, the researchers examined two samples: “What other name is Pittsburgh known by?” and “Which country is Pittsburgh in?” The corresponding API call results were “Steel City” and “United States”, respectively. Since the first sample produced the correct result, it was included in a new LM dataset that includes API calls:
“Pittsburgh is also known as [QA(”What other name is Pittsburgh known by?”) -> Steel City] the Steel City.”
 An example of embedding API calls in text. The actual Toolformer generates the output with this structure in mind.
An example of embedding API calls in text. The actual Toolformer generates the output with this structure in mind.
💡 Using this API embedding approach does the following: we don’t need a lot of human annotation, we can make our model use APIs in a more general way and expand the toolset in the future, and we can use the same dataset that we used for pertaining as this helps us to make sure that the model doesn’t lose its original abilities.
But this L term is interesting, after all, it is key in telling us what API calls to keep so let’s understand it better.

On the surface this is a simple cross-entropy loss There are two key parts here:
- The weights $w_
{i-j}$ , is the weight for tokens in the input example x, for a given position i-j
 This function defines the weighs used to weigh the log probability for each token position i within the input example
This function defines the weighs used to weigh the log probability for each token position i within the input example
- Probability for each token position, given the previous token.
This can be better viewed as:
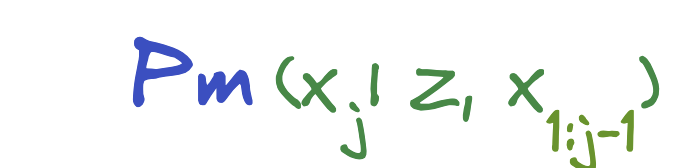
$P(x)$ is a prompt that causes a model $M$ to generate API calls, $x_{1:j-1}$ is the prefix of the sequence of tokens before the jth token.
If the model predicts a high probability for each token at the API call position the loss is low. Tokens closer to the API call are weighted more. The last bit is the filter. The idea here is to have a threshold between two losses:
 L+ is the loss that includes the API call and its result. L- is the minimum between two losses: The first one is doing no API calls at all and the second is with doing a call but not providing a response.
L+ is the loss that includes the API call and its result. L- is the minimum between two losses: The first one is doing no API calls at all and the second is with doing a call but not providing a response.
💡 We only keep generated API calls if adding the API call and its result reduces the loss by at least t, compared to not doing any API call or obtaining no result from it.
We then want to fine-tune the model on a new dataset that contains our text with API calls.
Results
But to break a conventional approach to training LLMs is a big claim to fame, so researchers provided a lot of different experiments to validate Toolformer. Here we will talk about key ones.
To begin let’s recall that Toolformer uses a language model as a base. Therefore researchers selected 4 models:
- GPT-J: A regular GPT-J model without any fine-tuning or API data.
- GPT-J + CC: GPT-J finetuned on C, a subset of CCNet, without API calls.
- Toolformer: GPT-J finetuned on C∗, our subset of CCNet augmented with API calls.
- Toolformer (disabled): The same model as Toolformer, but API calls are disabled during decoding.
You can find and read about the CCNeT dataset here.
💡 An important thing to keep in mind is that OPT and GPT-3 are very large models, with 66 and 175 billion parameters respectively. For comparison, GPT-J is only 6 billion parameters, meaning that Toolformer is but a fraction of these models in terms of size.
Wiki search with LAMA
The goal here is to complete some statements with a missing fact. Using the LAMA dataset, ToolFormer outperforms the baseline models and the LLMs.

Question Answering
A very straightforward task. Here, however, while Toolformer shows good performance clearly improving upon baseline, GPT-3 outperforms on all 3 Q&A datasets. To recall: for an API, a wiki search tool is used here. This can be the reason behind poor performance as the quality of the wiki search might be lacking.

Mathematical reasoning
Here Toolformer significantly outperforms both baselines and LLMs on math datasets. This is possible since Toolformer knows how to use a calculator tool.

Understanding of time (temporal reasoning)
This task is crucial in order for a model to be able to not only understand the context of a question and provide accurate facts given some specific timeline or date. But also to isolate knowledge pertaining to some events in a range of time. Here once again Toolformer gives top performance. TempLAMA is used to answer questions where the facts change with time.
💡 In this example for TempLAMA researchers discovered that the calendar tool is used only 0.2% of the time, meaning that most of the time it used the Wiki search tool. This is a limitation of Toolformer that we discuss further, as ideally we could use both calendar and wiki tools but Toolformer is limited to one call.

Scaling Law
Language models often come in different sizes, and to make sure Toolformer scales well with the size, the researchers decided to evaluate it using GPT-2 model, with 124M, 355M, 775M, and 1.6B parameters, respectively. Only a subset consisting of three tools was used: the question-answering, the calculator, and the LLAMA benchmark in form of the wiki search tool.
 Note that GPT-2 models are listed here as Toolformer and Toolformer(disabled)
Note that GPT-2 models are listed here as Toolformer and Toolformer(disabled)
From there the conclusion is that on the smallest models API inclusion does barely anything. The gap between models with API and without remains significant across different tasks. and if the model is larger it is better at using tools.
Is Toolformer an answer to everything?
The answer as you might have guessed is no. Researchers acknowledge it in a series of limitations that they hope to resolve in the future and push the AI community to address.
- Toolformer’s inability to use tools in a chain (i.e., to use the output of one tool as input for another tool) is due to the independent generation of API calls for each tool.
- Toolformer is unable to interactively use a tool, such as browsing through hundreds of search engine results to refine a search query.
- Toolformer’s decision to call an API can be sensitive to the exact wording of its input.
- Toolformer does not take into account the computational cost of making an API call for a specific tool when deciding whether or not to use it.
- While Toolformer via using an API is less susceptible to mistakes, the burden of fact-checking is passed onto an API that while significantly better still is not 100% guaranteed to produce a factually correct or perfect response
And with this, we wrap up our deep dive into Toolformer.