
If you missed it, check out our favorite papers and talks from Day 1 of RecSys 2022here.
Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)
Authors: Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, Yongfeng Zhang
Lab: Rutgers University
Link: https://arxiv.org/abs/2203.13366
The authors bring the power of large language models into the RecSys ecosystem. They present P5, a unified pretrain, personalized prompt & predict paradigm built on top of T5 checkpoints. It uses all data including user-item interactions, item metadata, and user reviews are converts them to a common format — natural language using prompt templates.
This new data formulation allow the authors to train P5 as a multi-task recommender where different 47 personalized prompts to cover 5 task families are used for training.
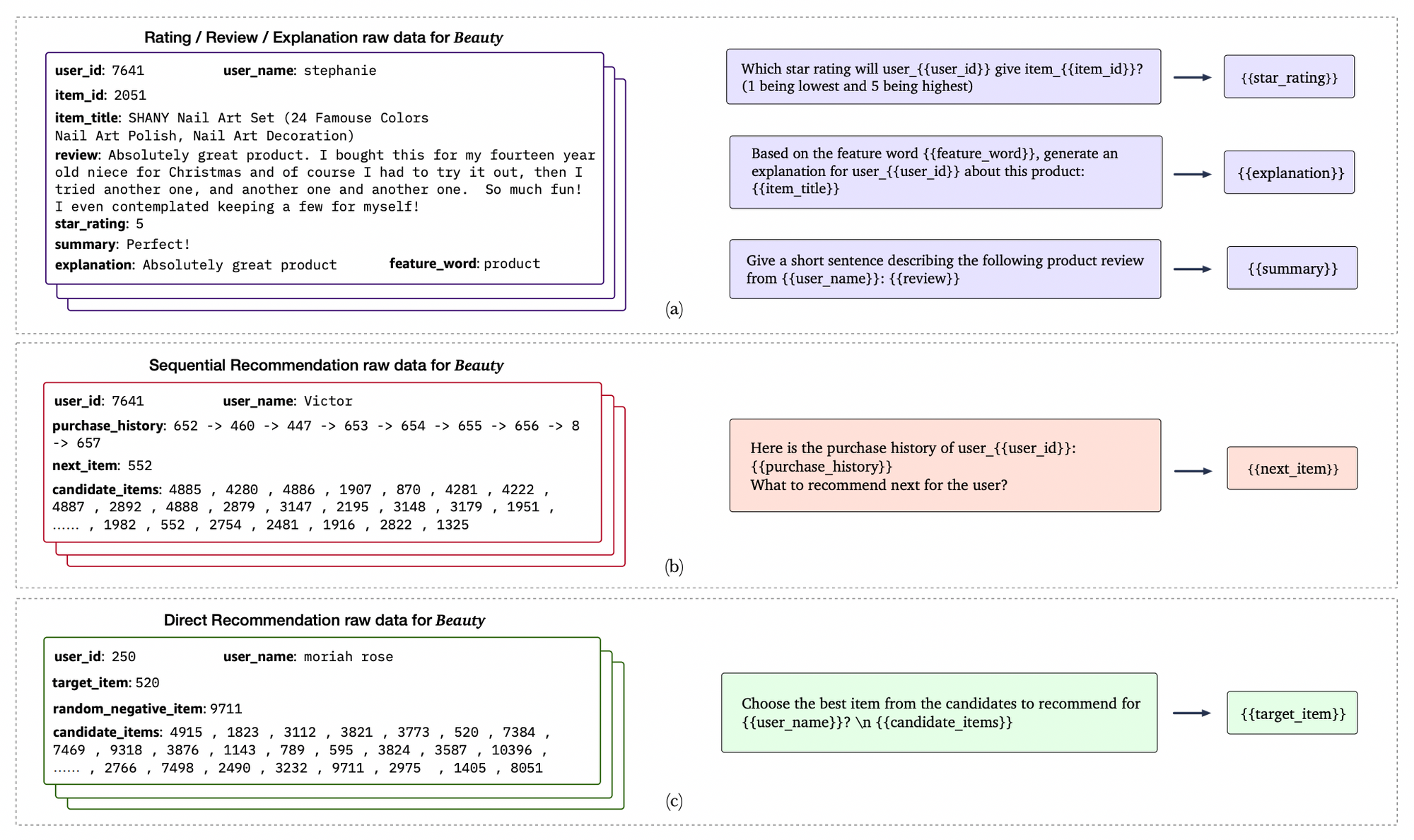
Each prompt consist of input–target pairs from raw data - simply substituting the fields in the prompts with the corresponding information. The raw data for the five task families of P5are from three separate sources. Specifically, rating/review/explanation prompts (a) have shared raw data. Sequential recommendation (b) and direct recommendation (c) uses similar raw data, but the former particularly requires the user interaction history.
By treating all different task as a text generation problem it possesses the potential to serve as the foundation model for downstream recommendation tasks, allows easy integration with other modalities, and enables a unified recommendation engine.
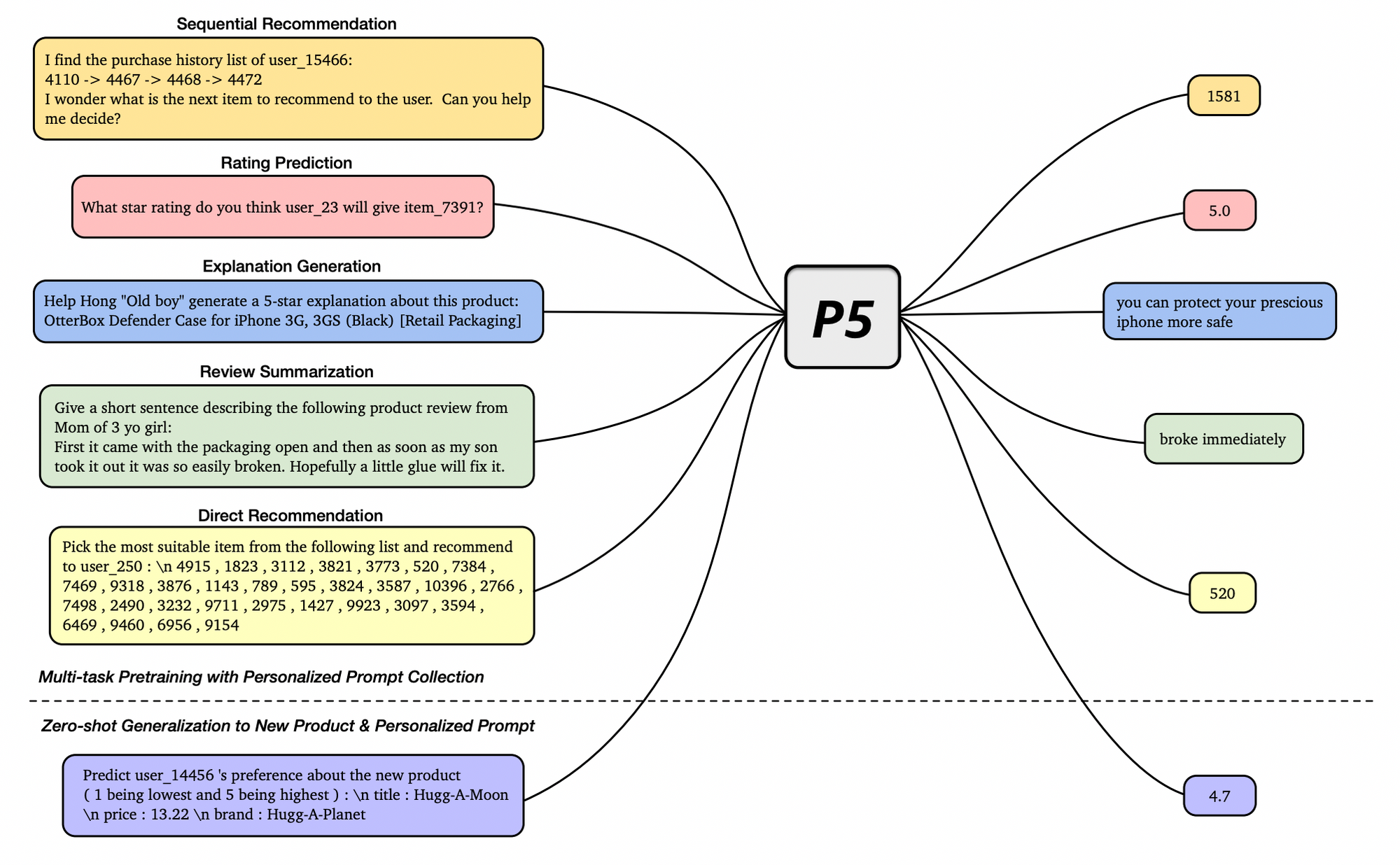
Their results show similar or better performance across multiple task when compared to specific trained models, with biggest uplifts on the sequential use-case. Visit their paper for more detailed table results.
We are very excited about this paper as it brings a new level of model generalization within the RecSys space and we are happy to give it our Shaped best paper award :)
RADio – Rank-Aware Divergence Metrics to Measure Normative Diversity in News Recommendations
Authors: Sanne Vrijenhoek∗, Gabriel Bénédict∗, Mateo Gutierrez Granada, Daan Odijk, Maarten de Rijke
Lab: University of Amsterdam, RTL Nederland B.V.
link: https://dl.acm.org/doi/pdf/10.1145/3523227.3546780
RADio introduces a rank-aware Jensen Shannon (JS ) divergence and experiments with diversity-aware news recommendations. The work is motivated by the gap between normative and descriptive diversity metrics. For example, traditional information retrieval diversity metrics likely wouldn’t be considered diverse according to the criteria maintained by newsroom editors.
The overall methodology they propose is as follows:
- Collect metadata from a news dataset that reflects democratic norms that you want the recommendation algorithm to follow. This metadata can be collected manually or through an NLP pipeline.
- Compare discrete distributions of that metadata to a recommendation algorithm via a rank-aware divergence metric.
The great thing about this process is that it gives data practitioners a way to tweak the trade-off between different target values in the recommendation, or even explicitly optimize on these normative metrics. For example, imagine a large media organization that wants to dedicate a small section of their website to a recommendation element titled “A different perspective”. They could optimize their metrics against DART’s [1] theoretical model of democracy to make informed decisions about which recommendation system is better suited to the normative stance they’re looking for.
What is rank-aware f-Divergence?
f-Divergence is a generalization of divergence measures like Kullback–Leibler (KL) and Jensen–Shannon (JS). This work proposes rank-aware f-Divergence which adds an optional discount factor between the P and Q comparison distributions. They find that a Mean Reciprocal Rank (MRR) discount: MRR = 1 / R_i, works well. If one of the divergence distributions is just a set of items, the rank-aware weighting can be removed.
[1] Recommenders with a Mission: Assessing Diversity in News Recommendations, Sanne Vrijenhoek, et al. (2021).
Countering Popularity Bias by Regularizing Score Differences
Authors: Wondo Rhee, Sung Min Cho, Bongwon Suh
Lab: Dept. of Intelligence and Information & Dept. of Computer Science andEngineering .Seoul National University
link: https://dl.acm.org/doi/abs/10.1145/3523227.3546757
Authors motivate their work by discussing two biases present in today’s matrix factorization methods:
- Data: Long-tail distribution for item popularity.
- Model: Unfairly higher scores to popular items among items a user has equally liked.
They then propose methods to handle model bias. Notably, they propose two regularization terms that aim to reduce model bias by giving equal scores to positive and negative items:
- Pos2Neg2 Term - 2 positive and 2 negative items are sampled per user at a time and the scored difference is minimized.
- Zerosum Term - 1 positive and 1 negative item is sampled and the sum is regularized to be close to 0.
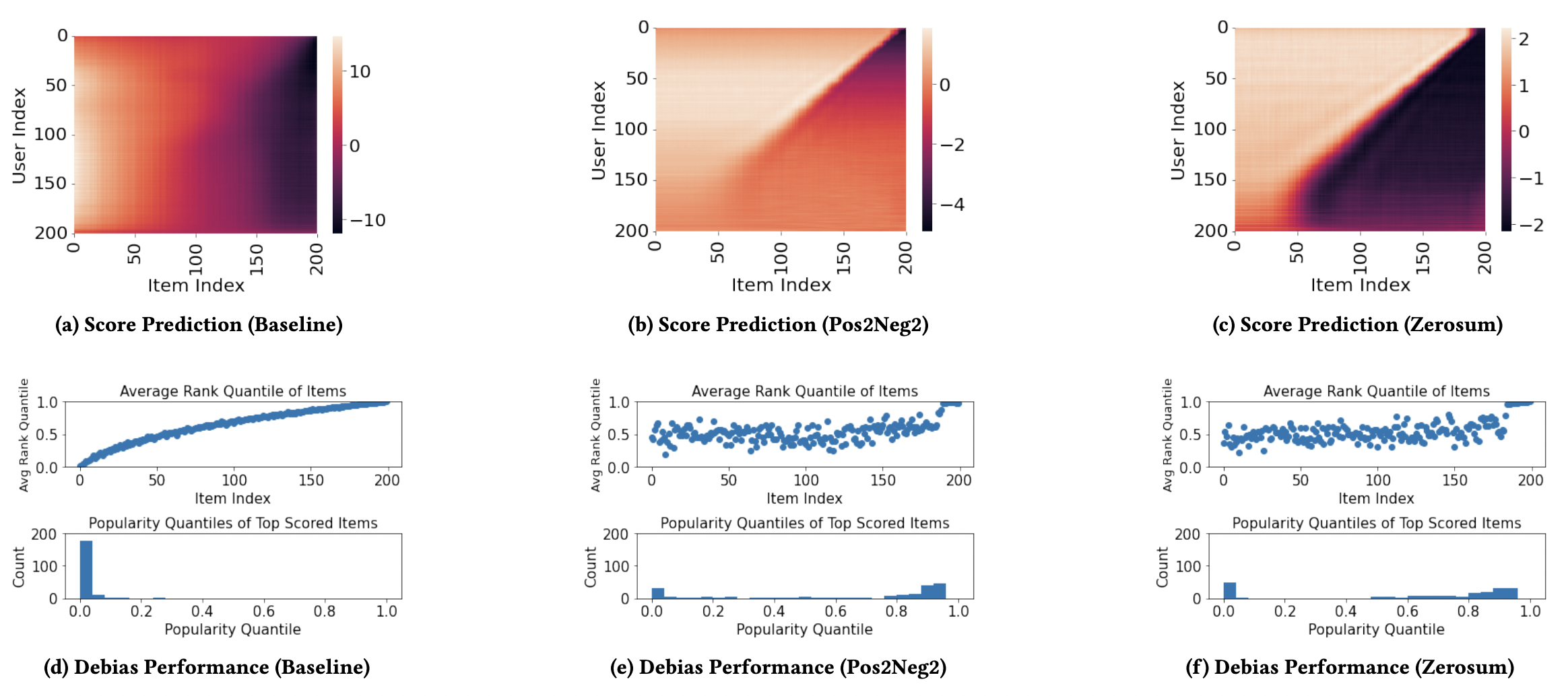 These plots show that the distribution of positive and negative scores is more symmetric than the baseline for both regularization terms.
These plots show that the distribution of positive and negative scores is more symmetric than the baseline for both regularization terms.
These plots show that the distribution of positive and negative scores is more symmetric than the baseline for both regularization terms.
The terms are experimented with by adding each term to a Bayesian Personalized Ranking (BPR) loss. For datasets where the baseline model performed well (i.e. Movielens, Gowella, Goodreads) ZeroSum generally had accuracy within a 2% error rate from the baseline and a generally improved debias metric (PopQ) compared to other debias methods and the baseline.
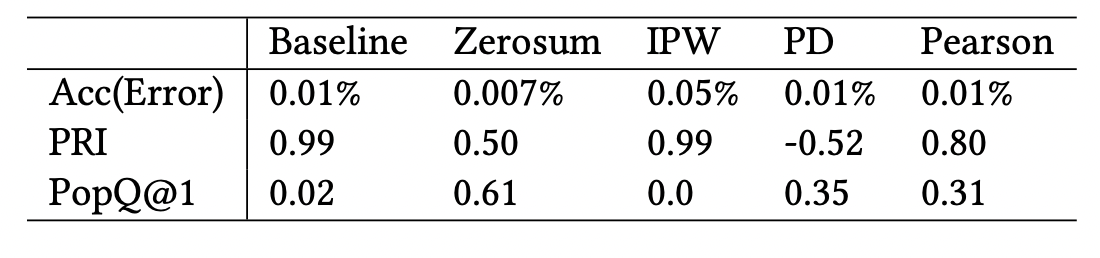 PRI and PopQ@1 (introduced in this paper) are popularity rank correlation metrics, that measure correlation of a ranking algorithm against a popular toplist. PD and Pearson are previous debiasing methods.
PRI and PopQ@1 (introduced in this paper) are popularity rank correlation metrics, that measure correlation of a ranking algorithm against a popular toplist. PD and Pearson are previous debiasing methods.
Don’t recommend the obvious: estimate probability ratios
Authors: Roberto Pellegrini, Wenjie Zhao, Iain Murray
Lab: Amazon
Link: https://www.amazon.science/publications/dont-recommend-the-obvious-estimate-probability-ratios
Recent papers evaluate recommendation systems with popularity-sampled metrics, which measure how well the model can find a user’s next item when hidden amongst generally-popular items. This paper shows that optimizing popularity-sampled metrics is closely related to estimating point-wise mutual information (PMI).
What is PMI? You can think of PMI as a measure of how much more likely two outcomes are to occur together compared to what we would expect by random chance assuming independence. It works by normalizing the conditional probability p(y | x) by the prior probability p(y). A PMI of zero, corresponding to a probability ratio of one, means that we won’t observe the outcomes x and y together more often than if they are independent. In contrast, a large positive value of the PMI implies a strong association between the outcomes. The reason it’s attractive score to rank items to recommend for a user is that it avoids recommending products that are not really personalized.
The authors then propose two methods to train a model that fits the PMI:
- Train directly on the classification task but sample with replacement in proportion to the general popularity.
- Embedded prior model. Estimate both the customer-specific predictions and the item popularity distribution separately and plug these into the ratio. There’s several ways these models could be constructed and trained, they use a neural network for convenience and experiment with training the models a) sequentially vs b) jointly vs c) using a loss that ignores the user-specific part when estimating the prior. They find that a) and c) are best.
Finally, they demonstrate that on the movielens dataset using the embedded prior model improves the popularity-sampled HIT@k metric by 5% for SasRec and BERT4Rec. And show that they recommend less popular products by evaluating the highest average index compared to the baseline.
 Average Index@10 computes the average global popularity index for the top 10 ranked items.Type image caption here (optional)
Average Index@10 computes the average global popularity index for the top 10 ranked items.Type image caption here (optional)
Recommending for a Multi-Sided Marketplace with Heterogeneous Contents
Authors: Yuyan Wang, Long Tao, Xian Xing Zhang
Lab: Uber
Link: https://dl.acm.org/doi/pdf/10.1145/3523227.3547379
Uber’s presents a recommender solution to their 3-sided marketplace for food delivery. Recommending restaurants to users on Uber eats while taking into account constraints and objectives from restaurants and delivery partners.
They propose a collection of machine learning models (MOHR) to balance between different objectives and serve recommendations to all groups.
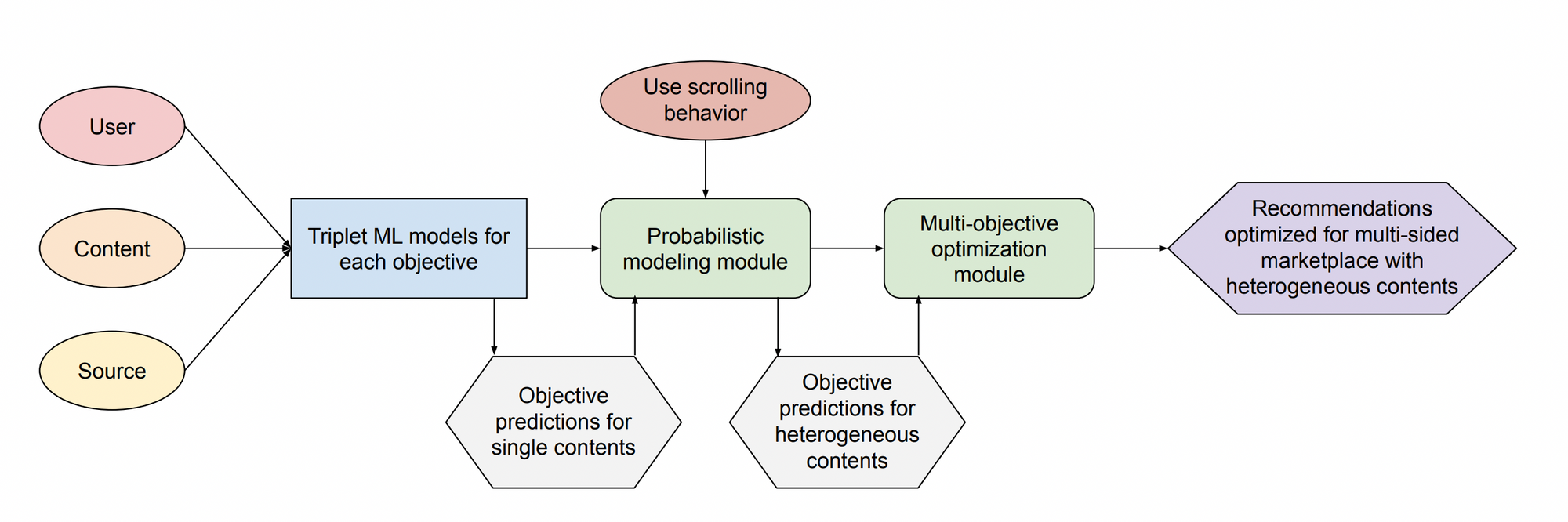
MOHR has multiple steps:
1. MO Multi-objective prediction for every (user, restaurant, source) triplet:
- User level: Conversion (placing order) and retention (coming back).
- Company level: Basket value and other financial metrics.
- Marketplace fairness: Ensure marketplace exposure fairness.
2. H State based user browsing model:
- State based user-browsing model to account for their limited patience. User state is modeled as their current viewing position with Markovian state transitions.
- Horizontal transition: continue browsing the next restaurant
- Vertical transition: abandon the current carousel
- Terminator: order from the current restaurant
- Carousel-level objectives can be expressed as a summation of the probability that a user order from a restaurant such that the user scrolls to the position of the carousel and restaurant.
3. R Multi objective optimization for ranking
- Maximize one of (conversion, retention, bookings, fairness) while constraining on the amount tolerable sacrifice for the others.
- This is a large scale linear programming problem. As the problem use Lagrange duality to solve the optimization.
They initially were reductant to A/B test their method due to cost and risk of churn so they evaluated with offline replay method first, using random ranking data where restaurants are randomly shuffled and presented to the users. After initial positive results they moved to real A/B test and allude to being the current production model, increasing conversion and generating multiple millions of dollars.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.