.png)
Introduction
Yann LeCun is one of the most well-known researchers within the field of AI. In fact, he along with two others, are known as the “Godfathers of Deep Learning”. LeCun has been pushing the limits of AI since the 1980’s and 90’s. His research has helped build the foundation of what we know as AI and deep learning today. Furthermore, LeCun has an impressive track record including being a Silver Professor at New York University, Chief AI Scientist at Meta, and one of the 2018 Turing award winners.
On June 27th, 2022 LeCun’s much anticipated paper “A Path Towards Autonomous Machine Intelligence” dropped on OpenReview. This blog will serve as a summary of the paper and my own personal response.
Overview of paper
This paper can more or less be summed into one simple question; “How could machines learn as efficiently as humans and animals?”. Not a simple question to answer and perhaps why this paper serves simply as a proposal to future directions of study rather than a conventional technical paper that shares novel research.
LeCun expressed in a recent interview at the WAICF (World Artificial Intelligence Cannes Festival) that as he approaches retirement, he hopes to inspire future AI researchers by presenting his vision for the future of this field.
Summary of paper
“Could someone summarise and dumb it down for us smooth brains?” -EfficientSir2029, Reddit 2022
If you, like EfficientSir2029, are worried about your smooth brain, I’m here to help with an unpretentious summary of Yann’s paper. As a previous student in Yann’s deep learning class at NYU, I know all about struggling to understand the words out of Yann’s mouth.
The first important point of this paper is that ML models severely lack the ability to adapt to a new situation they haven’t seen before. For example, he discusses how an adolescent can learn to drive a car in hours while ML models require a very large iteration of training so they know how to respond in the rarest of situations.
So what do human babies have that machines don’t? LeCun hypothesizes that the difference is humans (and animals) have the innate ability to learn world models, or “internal models of how the world works”.
LeCun proposes a model consisting of six separate modules. I recommend reading each module’s description in the paper, but here I will give a brief overview of each module with the main focus on the world model.
The six modules are defined as: configurator, perception, world model, cost, actor, short-term memory. The tweet above shows a (rather complicated) diagram of how the modules all related to one another.
- The configurator module: can be thought of as the composer of an orchestra. Given a task, the module pre-engineers the other modules.
- The perception module: estimates the current state and can represent the state of the world in a stratified manner.
- The world model module: the main piece and is explained below in more detail.
- The cost module: essentially the same as the definition you probably already know of cost. The goal is to minimize the cost function which in turn explains how well the model is performing on a given set of data.
- The short-term memory module: to create order to the predictions, this module store information about each state of the world as well as corresponding cost-function. This module is also needed to build long-term memory.
Key point: This paper describes a roadmap for developing machines whose behavior is intrinsic rather than hard-wired or requiring supervision/rewards.
So how can we create a world model?
Yann proposes using self supervised learning. LeCun is known for his strong belief in self-supervised learning (SSL). In fact, a couple years ago, LeCun made his (controversial) cake analogy. If you’re unfamiliar with his cake analogy I’ve linked a blog post that explains it here. In this paper, LeCun reiterates yet again the importance of SSL.
In short, SSL is necessary to allow machines to gain human-like reasoning and understanding.
How can we create multiple plausible predictions and teach the models what is important to predict and what is not?
This brings us to the star of the paper: the Joint Embedding Predictive Architecture (JEPA).
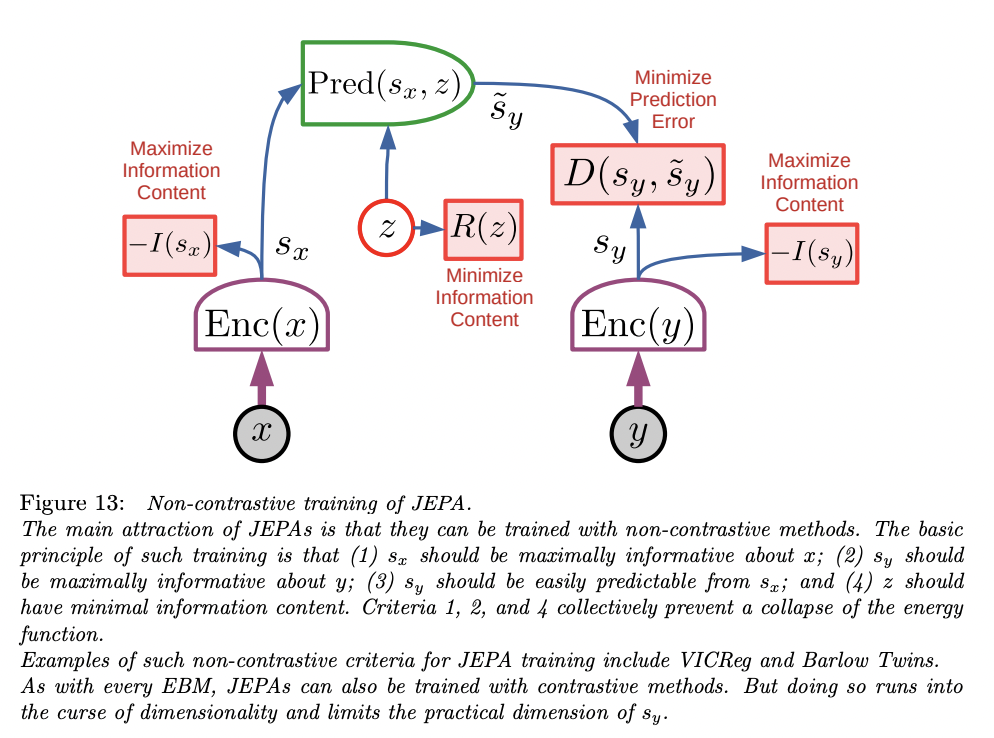
JEPA is a SSL energy-based model (EBM) that captures the dependencies between two given inputs, say x and y. Let’s go through an example of applying JEPA to a recommendation task (this is Shaped’s blog after all 😉). Given we have historical data about what songs a user has listened to, we want to build a recommendations system that can predict what the user would want to listen to in the future. In this case, x could be the last 5 songs a user has listened to and y could be future music plays. JEPA has the ability to predict in representation space. The two inputs are fed into the two encoders and the model is taught to predict sy from sx (with both being two abstract representations of each input). The predictor can use a latent variable, z, to minimize information content and the prediction will vary given a set of feasible predictions for the next song.
The ability of the JEPA to predict in representation space makes it considerably preferable to generative models that directly produce a prediction of y.
One advantage, as mentioned in the paper, is that JEPA can choose to ignore certain details that are not easily predictable or relevant. LeCun explains that in a video prediction it is impossible to predict every pixel value or detail of a future frame. He writes, “The details of the texture on a carpet, the leaves of a tree moving in the wind, or the ripples on a pond, cannot be predicted accurately, at least not over long time periods and not without consuming enormous resources.”
Furthermore, this means they can be stacked on top of one another to learn representations for not only short-term but also long term prediction. The encoding of one JEPA leads to the input of the next JEPA and so on.
A blog post by Meta gives a great example of how stacking JEPAs could allow both short-term and long-term predictions of “a cook making crêpes”. They write “a scenario can be described at a high level as “a cook is making crêpes.” One can predict that the cook will fetch flour, milk, and eggs… At a lower level, pouring a ladle involves scooping some batter and spreading it around the pan. This continues all the way down to the precise trajectories of the chef’s hands millisecond by millisecond. At the low level , the world model can only make accurate predictions in the short term. But at a higher level of abstraction, it can make long-term predictions.”
Any press is good press
I was surprised to learn that there is very limited discussion of this paper. Considering that Yann is one of the most well-known AI researchers, I was expecting to find multiple blog posts and responses to this paper. Sadly, I was met with a mere 11 comments on a Reddit thread and a few tweets in response to Yann’s tweet announcing the submission of the paper on OpenReview.
Feedback on Social Media
As mentioned the discussion online isn’t exactly riveting but let’s breakdown some responses. Comments include:
“Fun! How many JEPA ‘levels’ should we imagine inside the successful autonomous machine intelligence?” - @livcomp
A great question in my opinion and given Yann’s simple response of “Good question.”, I think we can interpret this as this is something that has yet to be answered.
Data Science Blogs
“If Yann is right, Meta AI will evolve a new kind of artificial intelligence as they build and work on the Metaverse with $Billions of dollars funded by their advertising based business model that Facebook has perfected over the last nearly the last 20 years!” - Michael Spencer (check out his blog here: https://datasciencelearningcenter.substack.com/p/yann-lecuns-paper-on-creating-autonomous)
“Really sad” -ML_anon (Schmidhuber, we all know this was you, no need to be anonymous - see the appendix below)
Personal opinion and closing remarks
Overall, I quite enjoyed reading this paper and think that it can serve as an inspiration to future ML researchers. In my opinion, the merge of cognitive science along with the every-growing technological evolution seems apparent yet innovative. However, not everyone agrees with LeCun’s proposed path to human-level AI. Another theory is “reward is enough” from the scientists at DeepMind. In short, they believe using the correct reward function and reinforcement learning algorithm is the path towards autonomous AI.
As a current ML researcher and long time LeCun fan, I know I will be on the look-out for the newest paper applying his proposed models. If you haven’t already, I hope this blog inspires you to read (or re-read) Yann’s latest work. If the 62 page pdf intimidates you, perhaps an even better option is to listen to this youtube video on Yann’s channel.
Appendix
So besides Jürgen Schmidhuber’s expression of disapproval, there wasn’t much to work with. If you’re like me and live for the drama, then it comes as no surprise that Schmidhuber was said to be “royally pissed off” by Yann’s paper. If you’re not familiar, the two have long had some tension. I recommend googling more about it, but in short Schmidhuber feels he was robbed the credit of being a founder of deep learning given his work on LSTMs and furthermore, that the wrong people (aka the 3 godfathers) are wrongly credited for the work of others. In fact so much so that he’s written 11,000 words about it. Maybe they should start a new reality tv show “Keeping up with the AI researchers”…
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.