
Background
New York Magazine has been publishing since 1968, and it reaches about 25 million readers per month (Comscore) across politics, culture, fashion, food, and everything in between. With one of the most diverse editorial portfolios in publishing — spanning Intelligencer, The Cut, Vulture, Grub Street, The Strategist, and Curbed — the next frontier was bringing that same editorial range to each individual reader’s homepage experience.
Delivering on that vision fell to the product team at Vox Media, New York’s parent company, who set out to build a personalization layer that matched the depth and quality of New York’s editorial.
A personalized news feed with better engagement than trending
Using Shaped, Vox Media launched a personalized article feed on New York Magazine’s website that increased page views per session by 2.5x.
The feed works in two stages. Shaped computes embedding vectors for each new article as it’s published. At runtime, ShapedQL matches those vectors against a reader’s interaction history to find the most relevant candidates. A time-decay factor ensures the feed stays anchored to what’s publishing now, alongside what each reader is most likely to want to read.
Balancing personalization with recency
NYMag publishes dozens of articles a day across Grub Street, Vulture, the Cut, and its politics desk. A restaurant review from yesterday might as well be ancient history. Any recommendation system had to surface articles no more than twelve hours old. A feed built purely on user behavior would inevitably resurface last week’s news.
To prevent staleness in the feed, Vox Media wanted a system that could balance two objectives:
- Personalization: how well an article matches a reader’s demonstrated interests
- Recency: how fresh an article is, with articles no more than 4 weeks old entering the feed

Shaped query language gave them the flexibility to model these business needs into a repeatable query.
SELECT *
FROM retrieve(
similarity(
embedding_ref='headline_similarity',
encoder='interaction_round_robin',
input_user_id='$user_id',
name='headline'
),
similarity(
embedding_ref='category_similarity',
name='category'
),
similarity(
embedding_ref='vertical_similarity',
name='vertical'
),
filter(
where='published_at >= now() - INTERVAL 4 WEEK',
)
)
WHERE item NOT IN personal_filter(user_id=$user_id)
ORDER BY score(
expression=
'(
0.5 * ("headline")
+ 0.25 * ("vertical")
+ 0.1 * ("category")
+ (0.3 * item.total_pv + item.last_12_pv)
)
/ pow((now_seconds() - item.article_created_at) / 3600)
* 10000'
)
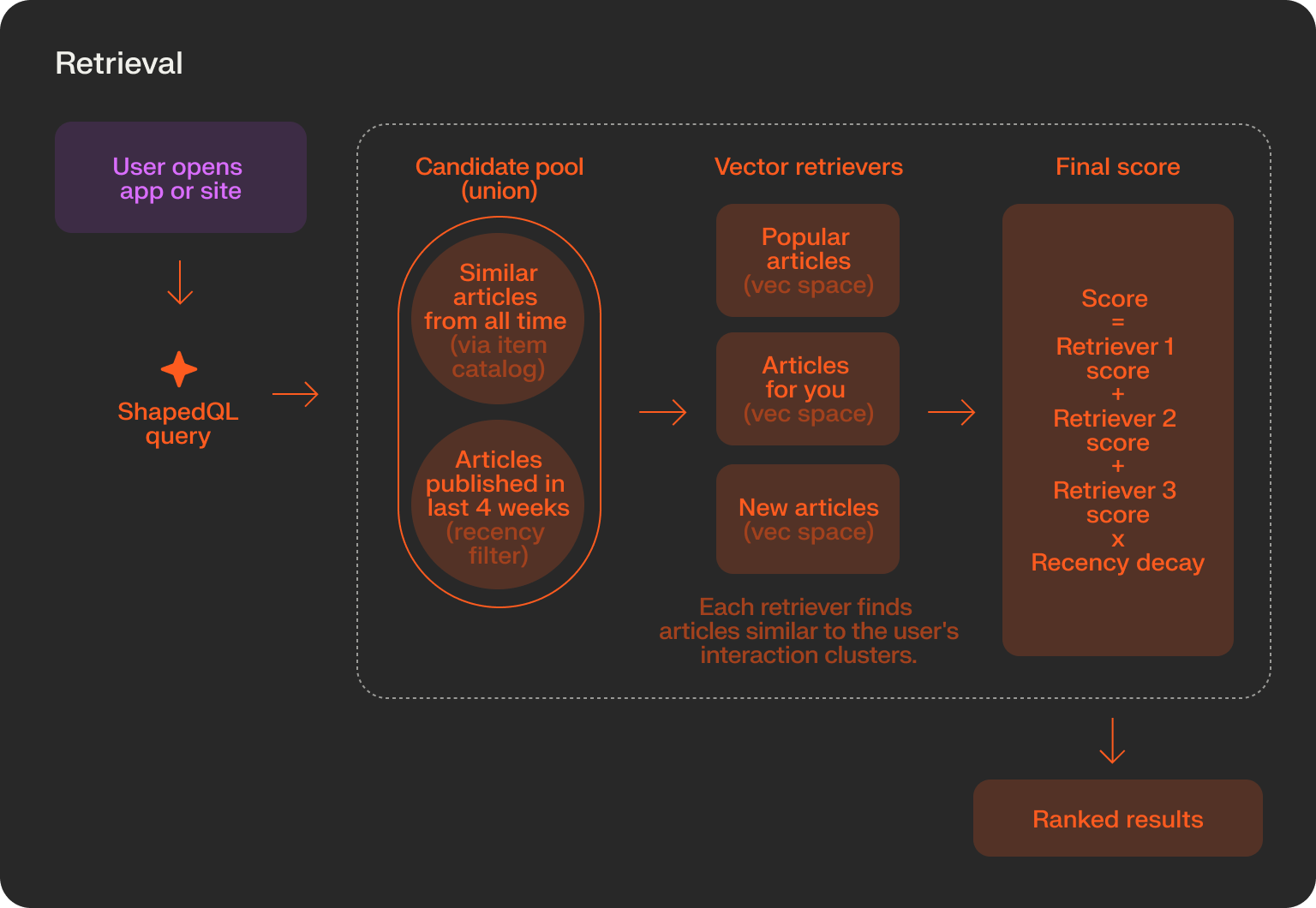
LIMIT 30They SELECT a candidate set of 1500 articles from four retrievers. They find the most similar articles to the user’s history from three vector spaces: headline, vertical, and category. They also retrieve articles from the last 4 weeks.
The WHERE clause filters out any items the user has read before.
The ORDER BY clause is where the final magic happens. It calculates a score for each of the 1500 input articles in real time and ranks them accordingly. The feed returns the 30 best-scoring items from this operation.
The Vox Media engineers found that weighing each embedding space differently gave a better looking feed than equal weighting. They also added a velocity score that weighed the items popularity in the last 12 hours. A time decay term lets the system balance “what this reader likes” with “what is happening right now”.
The final score is a linear combination of the weights:
(0.5 * (“headline”) + 0.25 * (“vertical”) + 0.1 * (“category”) + (0.3 * item.total_pv + item.last_12_pv)) / pow((now_seconds() - item.article_created_at) / 3600) * 10000
In one query, the app retrieves articles that are similar to the user’s interactions, unions the candidates with recently posted articles, and ranks the top candidates in a final list.
Learning which features actually drive engagement
NYMag’s editorial range means that a reader might click a Jonathan Chait column in the morning and a Grub Street restaurant review at lunch. The retrieval engine had to make sense of that range.
By representing each content feature as its own embedding space, the system could retrieve articles based on contextual similarity to a reader’s actual behavior rather than keyword overlap. But not every feature made the cut.
Vox tested each embedding space against a suite of real queries, and dropped the features that did not pass a human interpretation of similarity. Counterintuitively, the two features you’d think mattered most – article title and content – did not have an impact were dropped.
The text features that made the cut were:
- Headline
- Short description (generated)
- Topic (generated)
- Author
- Publish date
- Editorial desk - eg The Cut, Intelligencer, etc
- Category (generated)
- Subcategory (generated)
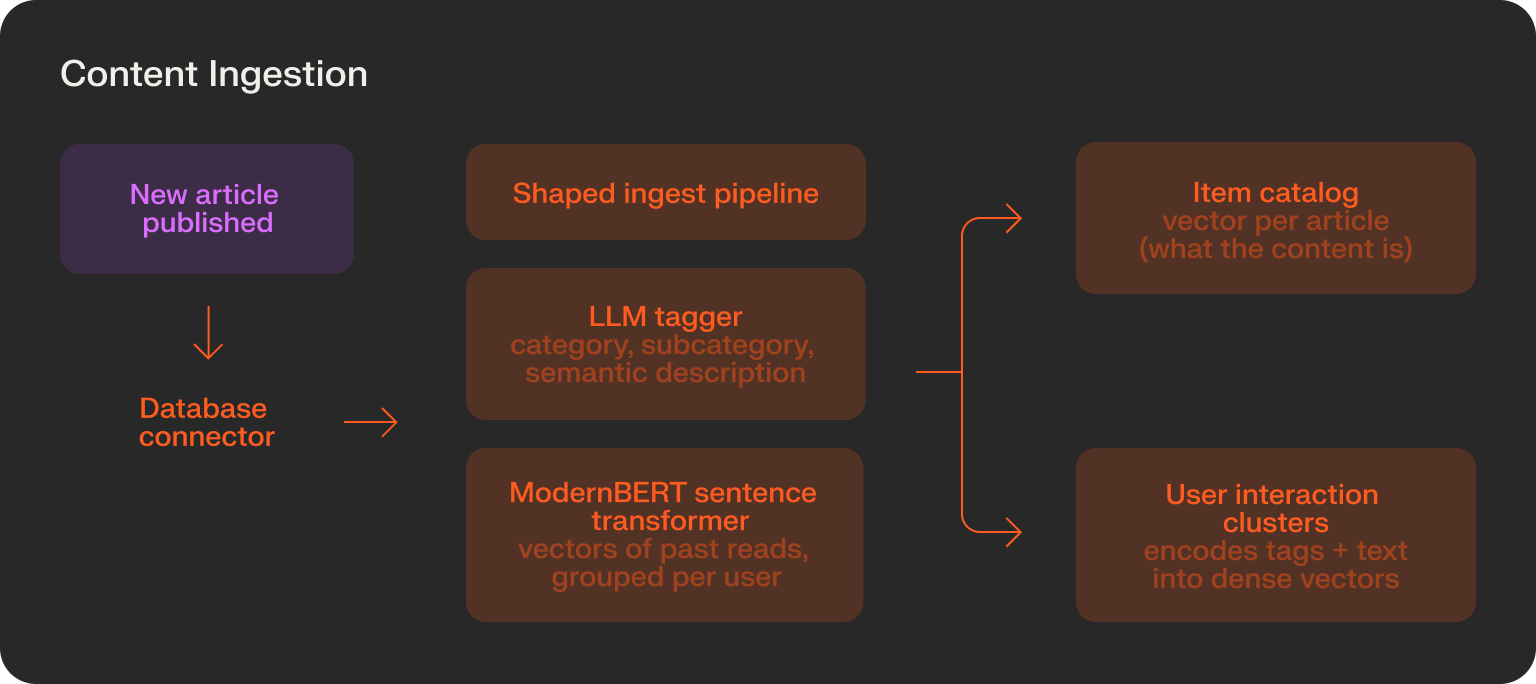
The final result was a data pipeline that ingested new articles, generated new features from the article content, and then encoded them into vectors.
In the process, the system effectively created audience segments organically. Readers who consistently engaged with food content were served a meaningfully different feed than those drawn to politics or culture.
Fixing noisy input text features with LLMs
The next challenge came almost immediately: to build good embeddings, you need good text features.
New York Magazine’s editorial tags were detailed but inconsistent. An article might carry six or seven tags spanning broad and narrow topics simultaneously: “Dining,” “Upper West Side,” “Pasta,” “Opening Night.” Feeding that raw data into an embedding model produced poor results because the model couldn’t distinguish between what was meaningful and what was incidental.
Vox used AI enrichment to extract a standardized, structured feature set from each article. A restaurant review that previously carried tags like “Dining,” “Upper West Side,” “Pasta,” and “Opening Night” would instead be classified as:
Category: Food & Drink
Subcategory: Restaurant Review
Short description: A concise semantic summary used to generate high-signal embeddings
This step didn’t discard editorial judgment, just standardized it so each article could be encoded in the same embedding space.
A powerful model using embeddings only
Vox Media made a deliberate choice to build the feed on embeddings alone, without training any ranking models. They chose this approach for its simplicity and control. An embedding-based approach can use a single input signal (page views) and avoid the engineering team needing new instrumentation on their site.
Shaped computes embeddings for new articles as data is ingested. At query time, a reader’s most recent interactions are fed directly into the request and Shaped creates a new embedding for these interactions in real-time. This means the feed can reflect up-to-date behavior rather than a static snapshot.
Testing and results
The new architecture was A/B tested on users by running the multi-embedding model against the legacy trending feed.
Across the test group, the personalized feed drove a 2.5x increase in page views per session compared to the legacy trending feed. Readers served the personalized feed clicked more articles because the system was surfacing content that matched their actual interests.
Page views drove the core business metric: whether subscription conversion volume increased alongside engagement. Readers who were consistently served relevant content converted to paid subscribers at a higher rate. The recommendation layer was functioning as a top-of-funnel driver for NYMag’s paywall.
The final system
Vox Media’s final architecture was a content personalization engine that relied purely on item and interaction vectors. When new articles are written, they are pushed to Shaped via database connector. They then immediately get tagged by an LLM and encoded into vectors with a ModernBERT sentence transformer model.
”Shaped gives us the control we need to keep our readers reading without diluting the human curation and breaking news that NYMag is known for. And our engineers were able to build it without starting from scratch.”
When a user opens the website or app, the app sends a ShapedQL query to find similar articles that match a user’s previous interactions, and then rank them based on recency and similarity.
What’s next
After seeing strong results with New York Magazine, Vox Media is planning to expand Shaped across its other publications. Upcoming use cases include geo-located restaurant search, keyword-driven article search, and personalized feeds for other titles in the Vox Media portfolio.