.png)
Let’s break down a paper that tackles one of the biggest bottlenecks in next-generation recommendation systems. The industry is buzzing with the shift from traditional, feature-heavy models to end-to-end generative approaches. Meta recently made waves with their HSTU architecture (which this paper calls “MetaGR”), showing that a generative, Transformer-based model could learn directly from raw user behavior sequences and achieve state-of-the-art results. But this power came at a steep price: a massive computational overhead that makes real-world deployment a headache.
Enter “Action is All You Need: Dual-Flow Generative Ranking Network for Recommendation**” by Hao Guo, Erpeng Xue, et al.**This paper, a collaboration between researchers at Meituan, Renmin University, and Tsinghua University, doesn’t just tweak Meta’s model—it fundamentally re-architects the data flow to solve the efficiency problem while simultaneously boosting performance. They introduce the Dual-Flow Generative Ranking Network (DFGR), a clever design that proves you can have your cake and eat it too: state-of-the-art accuracy and industrial-grade efficiency.
For anyone running large-scale recommendation systems and feeling the pain of rising compute costs and latency constraints, this work is a must-read. It offers a practical path forward for deploying powerful generative models without breaking the bank.
The N² Problem: Why Meta’s Approach Gets Expensive, Fast
To understand why DFGR is such a breakthrough, we first need to grasp the core issue with MetaGR. The key idea behind generative ranking is to treat recommendation like a language modeling task. You feed the model a user’s history, and it predicts the next action on a candidate item.
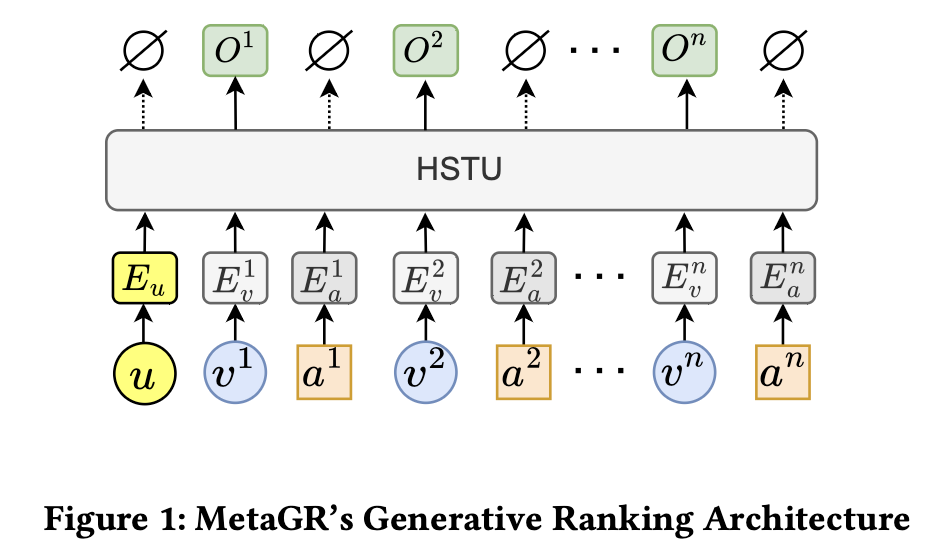 MetaGR constructs its input sequence by “interleaving” items and their corresponding actions. So, a user’s history of clicking item A and then viewing item B becomes a sequence of four tokens: MetaGR’s Generative Ranking Architecture
MetaGR constructs its input sequence by “interleaving” items and their corresponding actions. So, a user’s history of clicking item A and then viewing item B becomes a sequence of four tokens: MetaGR’s Generative Ranking Architecture
While this captures the full interaction, it doubles the length of the input sequence. This is a critical problem for the self-attention mechanism at the heart of Transformers, which has a computational complexity that scales quadratically with sequence length, O(N²). Doubling the sequence length from N to 2N means the compute cost blows up by a factor of four ( (2N)² = 4N² ). For users with long histories, this becomes prohibitively expensive for both training and real-time inference.
DFGR’s Secret Sauce: The Dual-Flow Architecture
The authors of DFGR identified that the root of the problem was splitting a single user interaction into two separate tokens. Their solution is both elegant and powerful: keep the interaction as a single token but process it in two parallel, coordinated streams.
Here’s how the Dual-Flow Generative Ranking Network works:
- Single-Token Representation: First, each interaction (e.g., “clicking item A”) is merged into a single input token that contains information about both the item and the action. This immediately halves the sequence length back to N, a huge efficiency win.
- Two Parallel Flows: The model then duplicates this sequence and creates two distinct processing paths:
- The Real Flow: This stream sees the true historical actions (e.g., ‘click’, ‘view’, ‘purchase’). Its job is to provide rich, accurate historical context.
- The Fake Flow: This stream sees the same items, but the action information is replaced with a generic “fake” placeholder token. Its job is to predict the true action for each item in the sequence, which is how the model learns.
Crucially, the loss is only calculated on the output of the Fake Flow. But if the Fake Flow has no real action information, how can it learn effectively? This is where the magic happens.
 Model Architecture of Dual-Flow Generative Ranking Network.
Model Architecture of Dual-Flow Generative Ranking Network.
During the self-attention calculation at each step, the Fake Flow gets to “peek” at the Real Flow. It uses its own Query (Q), representing what it wants to know, but it gets to attend to the Keys (K) and Values (V) from the Real Flow’s hidden states. This allows each token in the Fake Flow to build a contextual understanding based on the actual historical events without ever directly seeing the label it’s supposed to predict. It gets all the context without any of the spoilers, enabling efficient end-to-end training.
The Showdown: Experiments and Results (Section 4)
Theory is great, but the proof is in the performance. The DFGR authors conducted a comprehensive set of experiments on two public datasets (RecFlow, KuaiSAR) and a massive, real-world industrial dataset called TRec.
-
Blistering Efficiency Gains The theoretical advantage of DFGR translates directly into practice. Compared to MetaGR:
- Inference is 4x faster. Because inference only requires a single forward pass with a sequence of length N (compared to MetaGR’s 2N), the quadratic complexity reduction is fully realized.
- Training is ~2x faster. While DFGR processes two flows, each is of length N. The total complexity is roughly 2 * O(N²), whereas MetaGR’s is O((2N)²) = O(4N²). This halving of computational load is a massive win for model iteration.
 Comparison among MetaGR, and our proposed gen-erative ranking networks, including single-flow (SFGR) andDual-flow (DFGR). Assuming all models employ the sameTransformer hyperparameter configurations and input set-tings. 𝑁 denotes the number of items in the sequence, while𝐾 represents the average number of items per session.
Comparison among MetaGR, and our proposed gen-erative ranking networks, including single-flow (SFGR) andDual-flow (DFGR). Assuming all models employ the sameTransformer hyperparameter configurations and input set-tings. 𝑁 denotes the number of items in the sequence, while𝐾 represents the average number of items per session.
-
Superior Ranking Performance Not only is DFGR faster, but it’s also more accurate.
- On the public datasets, DFGR consistently outperformed a suite of strong baselines, including DIN, DIEN, and MetaGR, achieving up to a 1.2% AUC improvement over MetaGR.
- On the industrial TRec dataset, the results were even more impressive. DFGR surpassed not only MetaGR but also the platform’s highly-optimized production DLRM, which used hundreds of manually engineered features. This demonstrates that the end-to-end generative approach, when designed efficiently, can break through the performance ceiling of traditional models.
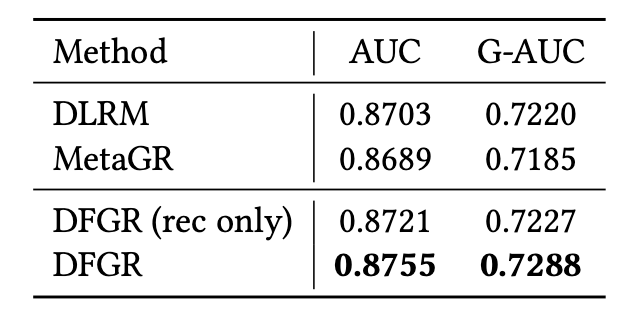 Overall performance comparison on industrial dataset TRec.
Overall performance comparison on industrial dataset TRec.
- It Scales! One of the most promising findings is that DFGR adheres to “scaling laws.” The authors show that as they increase the computational budget for the model, its performance (measured by G-AUC) improves in a predictable, logarithmic fashion. This is crucial for industrial applications, as it means that investing more compute resources will reliably translate into better model quality.
 Scaling Laws with Computational Complexity.
Scaling Laws with Computational Complexity.
Final Thoughts: The Next Generation of Recommenders is Here
The “Action is All You Need” paper presents a significant step forward for generative recommendation models. It addresses the most critical blocker to adopting Meta’s powerful SOTA approach—computational inefficiency—and delivers a solution that is not only faster and cheaper but also more accurate.
Key takeaways for practitioners:
- Efficiency is a Feature: DFGR’s dual-flow mechanism is a masterclass in optimizing Transformer architectures for a specific task, slashing the punishing quadratic complexity of its predecessor.
- End-to-End Beats Hand-Tuning: The model’s ability to outperform a heavily feature-engineered industrial baseline by learning directly from raw sequences is a powerful testament to the potential of this paradigm.
- Generative Ranking is Ready for Primetime: By solving the core efficiency and performance challenges, DFGR establishes a practical and effective blueprint for the next generation of industrial-scale ranking systems.
This work effectively bridges the gap between cutting-edge academic research and the practical demands of real-world deployment. It provides a clear, compelling, and computationally sound foundation for building the recommender systems of the future.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.