I’ve been a HackerNews user for almost 15 years now; it’s probably the most consistent site I’ve visited over that time. For social media, I’ve gone from Myspace to Facebook to Instagram to LinkedIn to TikTok. For note-taking and calendar apps, I’ve churned through hundreds of different solutions. Even for news, I’ve jumped between different publishers and aggregators. But one website has been a constant for tech knowledge: HackerNews!
As I’ve used HN, though, my way of using it has changed. When I was younger, I was interested in everything. Whether it was the latest iPhone announcement or a deep technical topic about rewriting IP tables, I tried to consume it all. I lived on the “top” feed.
More recently, I’ve been more nuanced with what I read. For me, deeply personal blogs and opinions on topics I’m interested in (like AI, recommendations, research) are what’s most interesting. I try to avoid reading too much about big tech announcements since I usually hear about them at the office anyway. I just don’t have the time to dive into as many random technical topics, even though I’d still like to.
So, the “top” feed has become a bit stale for me. Despite my constant interest in HN, the content I want to read has changed dramatically, and the static ranking algorithms make me feel like I have to sift through noise. I’m finding more recently that I’ve been digging through “new” to find things that might be interesting but aren’t just the mainstream discussion.
What I really want from HackerNews is a personalized ranking algorithm. I want a feed with a bit of everything I enjoy, plus new topics I might not have seen before that may not make it to the top. I also want it personalized based on context: in the morning, I typically want to read surface-level announcements; during work, I want denser content related to what I’m working on; and when I go home, I want more personal opinion pieces that I can reflect on.
Coincidentally, I’m the founder and CEO of Shaped, a company building a platform for recommendations and search. Our bread and butter is “For You” feeds, and we’ve helped many companies with the exact problem I’m facing. So, using HackerNews’s public API, I was able to take the problem into my own hands. The site is at hn.shaped.ai, and it supports a “For You” feed that uses your “favorites” as signals for personalization. I also added “similar stories” to make it easier to find related content.
In this post, I’m going to walk through how I built it. It took under two days: one day for the HackerNews client and one for the feed—basically the time of a personal hackathon. At the end, I’ll talk a bit about next steps.
Day 1: Building the HackerNews Client
Requirements
When I set out to build this, I didn’t want to just demo Shaped’s capabilities. I wanted a legitimate HN experience that I’d actually use. This meant it wasn’t all about the “For You” feed; I also needed to replicate a reasonable HN experience where I could read posts and comments on mobile. I also upvote, favorite, and comment occasionally, so those features were a must. The only feeds I really use are “top” and “new,” so I made sure they were available too.
Getting Started
In the age of AI tools, building a HackerNews clone is incredibly easy. I just went over to lovable.dev and typed in: “Can you build me a clone of HackerNews with a top and new feed?”. It generated basically exactly what I wanted: a minimal web client that pulled from HackerNews’s public APIs.
I was honestly amazed that it created such a nice design (arguably better than HN’s 2000s feel) and was smart enough to find the public API. Every couple of months, I get wowed by AI when I use it for a new use case, and this was definitely one of those times. It really made me reflect on whether the last 15 years of obsession over coding and software engineering best practices had been worth it…
 Initital HackerNews client from lovable.dev
Initital HackerNews client from lovable.dev
I hit publish and tested it out a bit. Here’s what was missing:
- Pagination, so I could scroll more than one page.
- Mobile support was lacking.
- The ability to log in and upvote.
Pagination and mobile support were easy fixes with just a bit more prompting. However, logging in and upvoting were going to be more difficult, as we were now moving from a passive client to an active one.
Adding Authentication and Upvotes
Unfortunately, HackerNews’s official API doesn’t support authentication. Lovable’s first suggestion was to build our own authentication system and our own system for upvoting only within our client. This didn’t really work for me, as I wanted my upvotes (and future comments) to be reflected on the actual HackerNews website. Again, this wasn’t just being built for a demo; I wanted it to replace my current HN experience.
I kept trying different prompts to get Lovable to work it out, but it kept pushing back on this being possible. This is where a bit of independent thinking finally came in. I realized there were definitely a lot of HackerNews clones out there (just look at all the clients on the iOS App Store). How were they building it?
Well, unsurprisingly, HackerNews has an unofficial REST API for all of these POST requests. The reasons Lovable was against using it were:
- Potential legal issues: I’m genuinely unclear of the risks here but figured because there are so many other HN clients, it wouldn’t be an issue. This would be a different story for the New York Times, but I figure Y-Combinator isn’t too worried about this (let me know if they are!).
- CORS problems: We can address this by adding a lightweight back-end layer for our client that makes the POST requests and returns them to the client.
There was some negotiation with the Lovable agent, but I was able to get it to generate all the code for this. For the back-end, it chose to useSupabase edge-functions (which I hadn’t used before but it worked great as a lightweight serverless compute toolt). I needed to set up my Supabase account and link it with Lovable, but after a few approvals, it generated an hn-proxy edge function to handle authentication, upvotes, and favorites.
With Supabase connected, I was also able to set up a serverless Postgres database with two tables, posts and events. This would contain a cache of posts and user actions, both for performance and, later on, for building our “For You” feed.
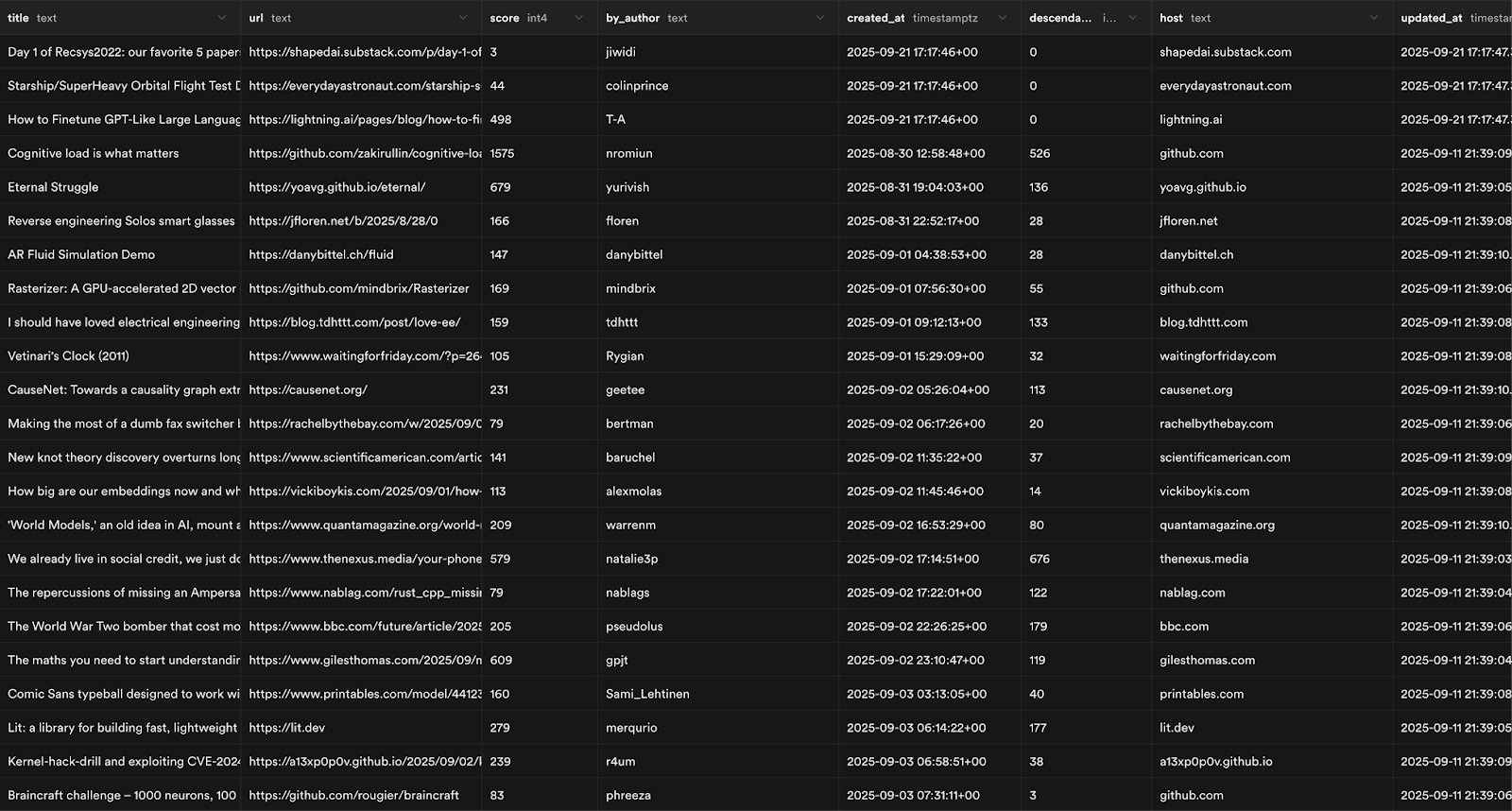 Posts table schema, includes columns: url, score, title, author, published_at, number_of_comments, host, updated_at. All of these fields are used for display but also will be perfect as features to our ranking algorithms later on.
Posts table schema, includes columns: url, score, title, author, published_at, number_of_comments, host, updated_at. All of these fields are used for display but also will be perfect as features to our ranking algorithms later on.
Polish
The client was feeling functional, so I reserved the rest of the day for polish. I’m still not sure how Lovable’s credit system works, but this is where I sent the most prompts. I would do some QA, then go back and ask it to solve all the UX issues and bugs, like:
- Make sure all upvotes are colored, stored, and persist across all pages.
- Add skeleton UIs when loading.
- Make sure the feed loads smoothly.
- Make sure we’re not storing duplicate posts in the database.
- And many more…
Finally, I set up the DNS records for hn.shaped.ai, shared it with our team at Shaped for some extra dogfooding, and finished up for the day.
 The polished HackerNews client. Includes a user profile page, authentication, upvotes, and a top and new feed.
The polished HackerNews client. Includes a user profile page, authentication, upvotes, and a top and new feed.
Day 2: Building the “For You” Feed
Background
There are many ways to build a “For You” feed. The system for this doesn’t need to be as sophisticated as Meta’s or TikTok’s. No recommendation problem is exactly the same, so we can’t use the same system they’re using either.
News recommendations, in general, are quite different from social media and e-commerce. What makes something relevant for news? A simple way to think about it is with these two categories:
- Recency: It’s more relevant if it’s new.
- Popularity: It’s likely more relevant if other people like it.
In fact, this is exactly how HackerNews’s ranking algorithm works, which Paul Graham explained in a comment here. Basically, it works as follows:
rank = (upvotes - 1) / (hours_since_post + 2) ^ 1.8
The intuition is that as upvotes grow, the rank grows, and as time increases, the rank decays.
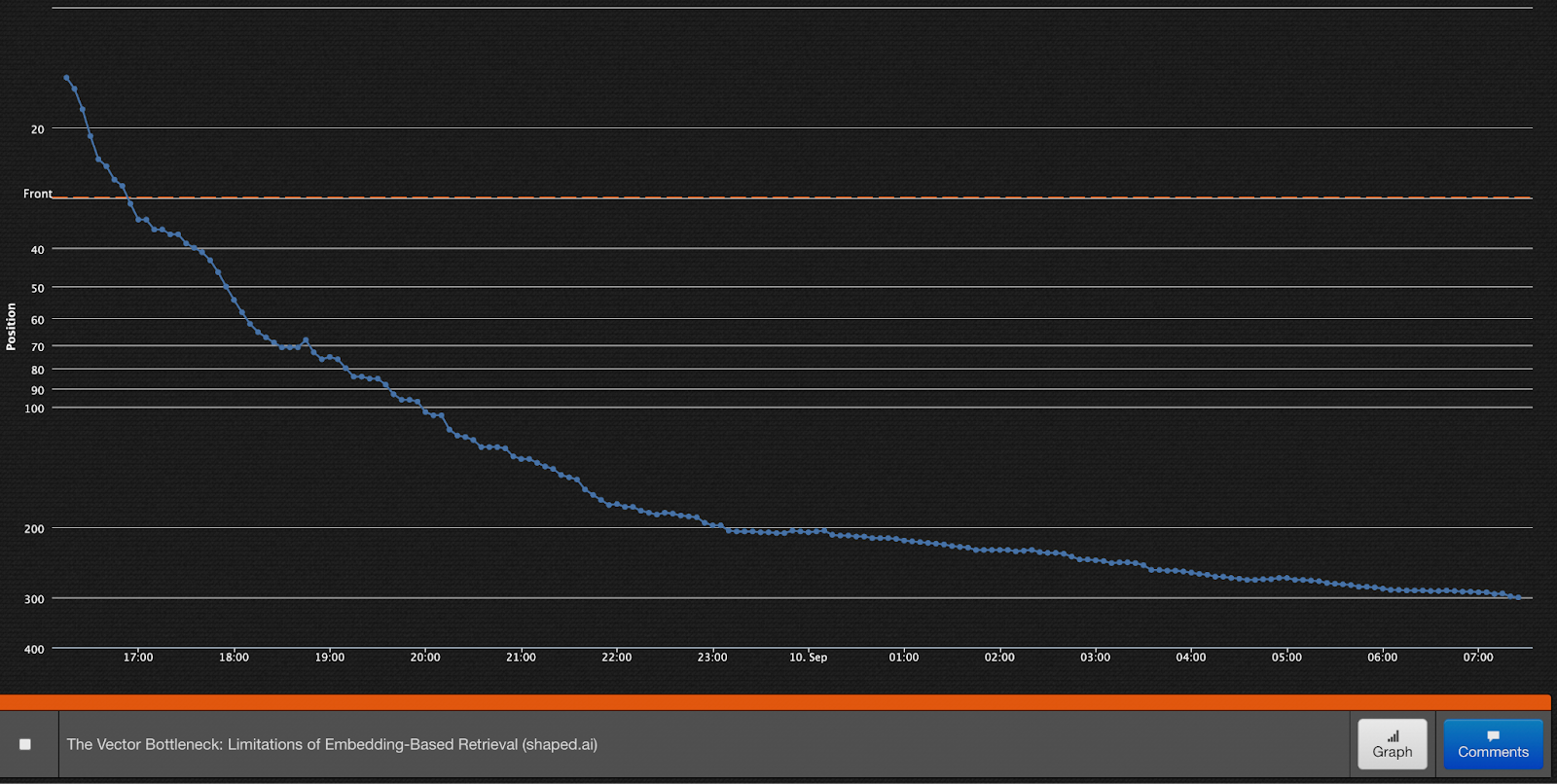 Here’s an image of a post I made the other day that only got a few upvotes. You can see the exponential decay on time pretty clearly. If there were more upvotes, it would just spend more time on the front page and have a better chance to go viral.
Here’s an image of a post I made the other day that only got a few upvotes. You can see the exponential decay on time pretty clearly. If there were more upvotes, it would just spend more time on the front page and have a better chance to go viral.
The Next Level of Relevance: Personalization
So how can we take this to the next level? Personalization!
There are two ways we can think about adding personalized relevance:
- Content-Filtering: What if posts rank slightly higher if they discuss similar content to what you’ve previously engaged with (e.g., favorited)?
- Collaborative-Filtering: What if posts rank slightly higher if they’re popular within a segment of users that are similar to you?
Ultimately, what I want is a feed that adds one of these as an extra term in the ranking function. Something like this:
rank = ((upvotes - 1) * (1 + content_similarity)) / (time_since_post + 2) ^ 1.8
For the first feed I built, I did exactly this and stuck with just content similarity. The main reason is that content-filtering algorithms are more robust when there isn’t much data. It works perfectly fine with only my own interaction data. Collaborative filtering, on the other hand, needs enough user data to find people who are actually similar to me.
Using Shaped to Build the Feed
Shaped is perfect for building these kinds of personalized feeds. At a high level, here’s what I needed to do:
- Connect the data: Get the posts and events tables from Supabase into Shaped.
- Create a ranking model: Define the objective function above in a Shaped model.
- Integrate into the client: Create a “For You” button that pulls results from Shaped.
I created two Datasets in Shaped: a Postgres Connector that syncs from the Supabase database every 10 minutes, and a Custom API that provides an endpoint to push events like favorites directly to Shaped in real-time. This real-time ingestion allows for in-session ranking, meaning the feed can react immediately after you favorite something.
After creating those, I could see the posts start syncing. I went back to Lovable and asked it to push all favorite events to Shaped.
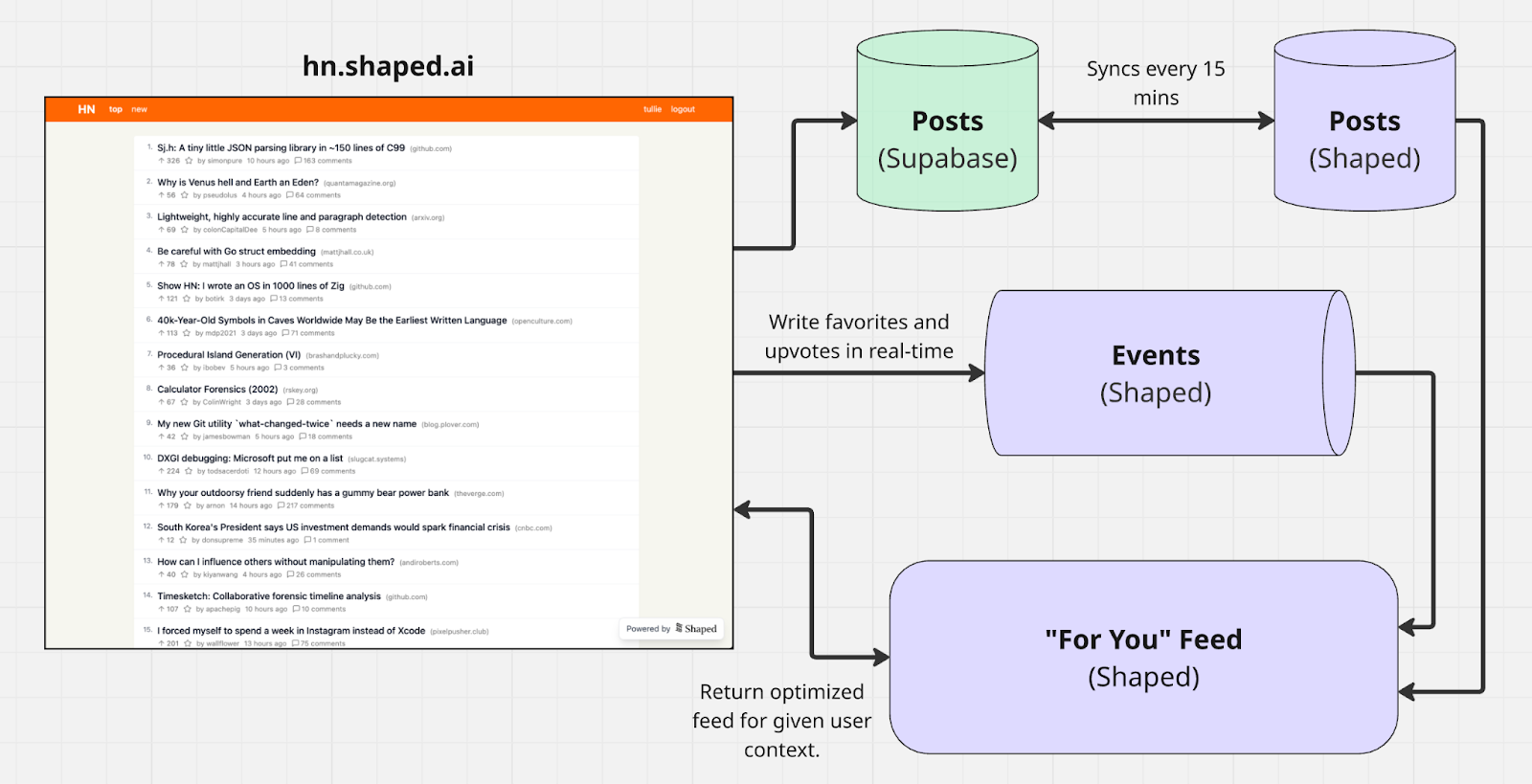 High level diagram for Shaped powered “For You” feed.
High level diagram for Shaped powered “For You” feed.
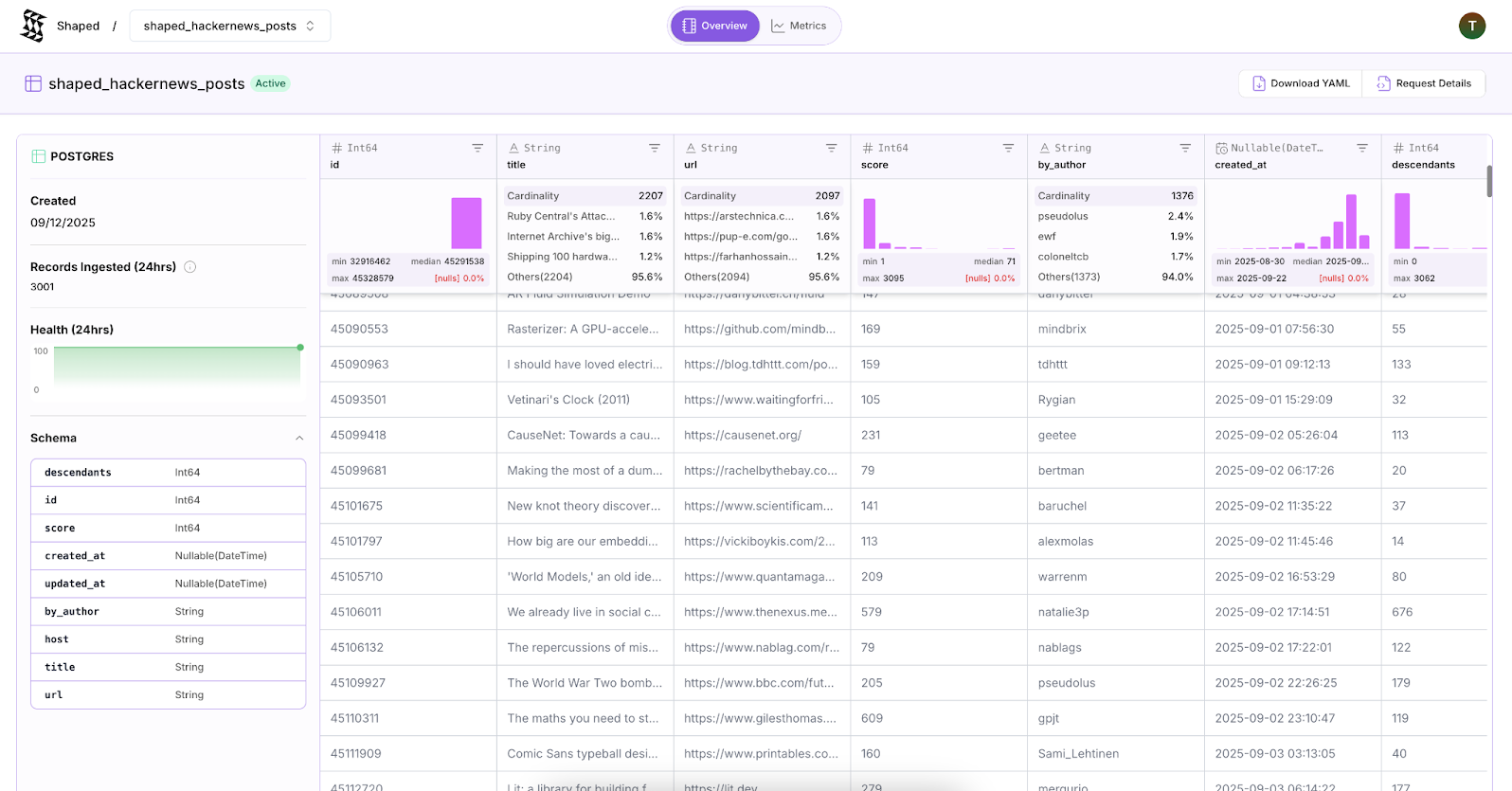 Screenshot from the Shaped dashboard showing the posts dataset that’s synced every 15minutes with the Supabase Postgres db.
Screenshot from the Shaped dashboard showing the posts dataset that’s synced every 15minutes with the Supabase Postgres db.
Setting up the Shaped Model
Next, I needed to create the Shaped model that represents our objective. Shaped uses a 4-stage ranking framework:
- Retrieval: Defines the initial pool of candidates. For us, this is the last 300 posts.
- Filtering: Defines items to filter out. Here, we’ll filter out pages of data as the user scrolls, creating an infinite feed.
- Scoring: Defines the objective function we’re optimizing for—our personalized rank score.
- Ordering: Assembles the final ranking. For now, we’ll just sort by score.
I created a Shaped model definition for this. The definition is made up of two parts: Fetch and Model.
Fetch
This section defines which datasets we want to pull data from (e.g. in this case the posts and events dataset). Shaped provides a SQL engine to make it easy to select the data we’re going to need for any ranking algorithms. In this case we’re selecting everything from the database but deduplicating, for the events we’re selecting all favorite events that haven’t been subsequently unfavorited.
# Select all items features and dedupe
items: |
SELECT
item_id,
title,
url,
score,
by_author,
published_at,
descendants,
host,
updated_at
FROM (
SELECT
id AS item_id,
title,
url,
score,
by_author,
published_at,
descendants,
host,
updated_at,
ROW_NUMBER() OVER (PARTITION BY id ORDER BY updated_at DESC) as rn
FROM
shaped_hackernews_posts
) AS ranked_items
WHERE
rn = 1
# Select all favorite events unless they've been subsequently unfavorited
events: |
SELECT
user_id,
item_id,
published_at,
event_type AS event_value,
(
CASE
WHEN event_type = 'FAVORITE' THEN 1
WHEN event_type = 'UNFAVORITE' THEN 0
END
) AS label
FROM (
SELECT
user_id,
item_id,
published_at,
event_type,
ROW_NUMBER() OVER (PARTITION BY user_id, item_id ORDER BY published_at DESC) as rn
FROM
shaped_hackernews_events
WHERE
event_type IN ('FAVORITE', 'UNFAVORITE')
) AS ranked_events
WHERE
rn = 1 AND event_type = 'FAVORITE'Model
The model section defines how our feed will be built exactly. For example it describes that we’ll be pulling 300 items from the chronological retriever (one of Shaped’s preset retrievers). It also defines the value model we’re aiming for which we’ll discuss afterwards.
name: hackernews_for_you
language_model_name: Alibaba-NLP/gte-modernbert-base
pagination_store_ttl: 600
inference_config:
query:
retrieve:
- name: new
limit: 300
order_by:
order_type: COLUMN
columns:
- name: published_at
# Personalized retrieval using dense embeddings
policy_configs:
scoring_policy:
policy_type: score-ensemble
value_model: |
# Popularity
(item.score - 1)
# Personalization
* (1 + cosine_similarity(
text_encoding(item),
pooled_text_encoding(user.recent_interactions)
))
# Time Decay
/ (((now_seconds() - item.published_at) / 3600) + 2) ** 1.8A few extra notes:
- Content similarity model? I used Alibaba-NLP/gte-modernbert-base, a fine-tuned ModernBERT model great for this kind of task.
- **How does the personalization term actually work?**We look at the cosine-similarity of each item text embeddings, with the mean pooled text encoding of the last 30 previous interactions. This is providing a value between 0 and 1 that defines how similar the post is to previous favorites. Closer to 1 means more similar and the + 1 is to ensure the value is multiplicative to the popularity term.
- What events are we using? Just favorites and unfavorites for now. I tried using upvotes, but they were too noisy for a content-filtering algorithm, and debugging was tricky since you can’t un-upvote. We can revisit this with more data.
After registering the model and waiting about an hour, we had a workable ranking pipeline! We can see the results on CLI with the following curl query. Shaped also provides a CLI to do this easily.
# curl_hackernews_rank.sh
curl -X POST "https://api.shaped.ai/v1/models/hackernews_for_you/rank" \
-H "x-api-key: <API-KEY>" \
-H "Content-Type: application/json" \
--data '{
"user_id": "tullie",
"limit": 30,
"return_metadata": true
}'The Final ‘For You’ Feed
To put it all together, I went back to Lovable and asked it to create the “For You” feed using the Shaped API. It was now ready for action!
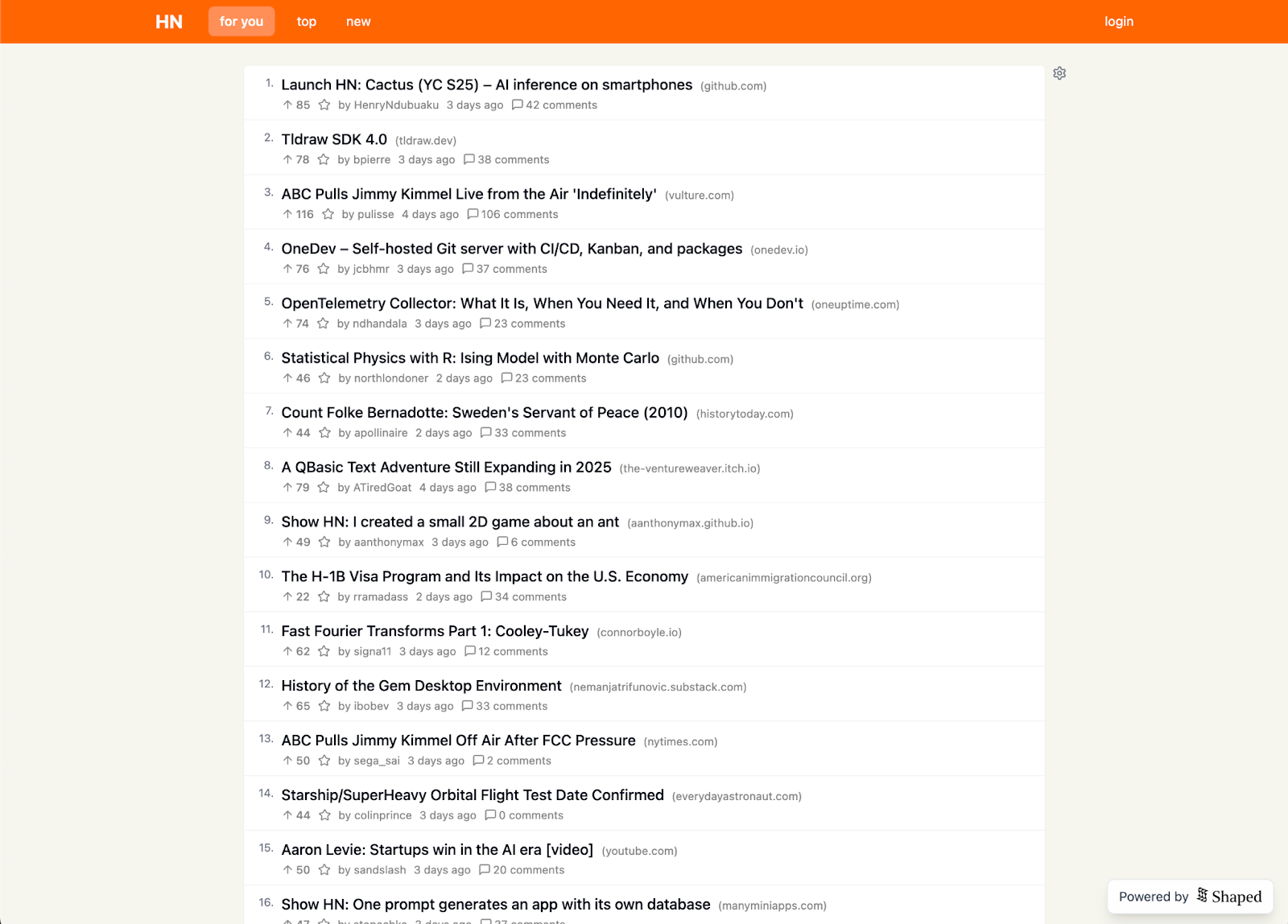 The “For You” feed tab.
The “For You” feed tab.
The ranking formula is configurable in real-time. For example, if you just want the standard HackerNews objective, you can use this:
(item.score - 1) / ((((now_seconds() - item.published_at) / 3600) + 2) ** 1.8)And adding content relevance looks like this:
((item.score / 1000) + cosine_similarity(text_encoding(item), pooled_text_encoding(user.recent_interactions))) / ((((now_seconds() - item.published_at) / 3600) + 2) ** 1.8)The denominator of the item.score term is used to normalize the popularity values into a distribution that’s similar to the content similarity values. 1000 seemed to balances popular, recent, and personally relevant content well. You can see below that posts related to AI are boosted into my feed, but the top and most recent posts are still mostly maintained.
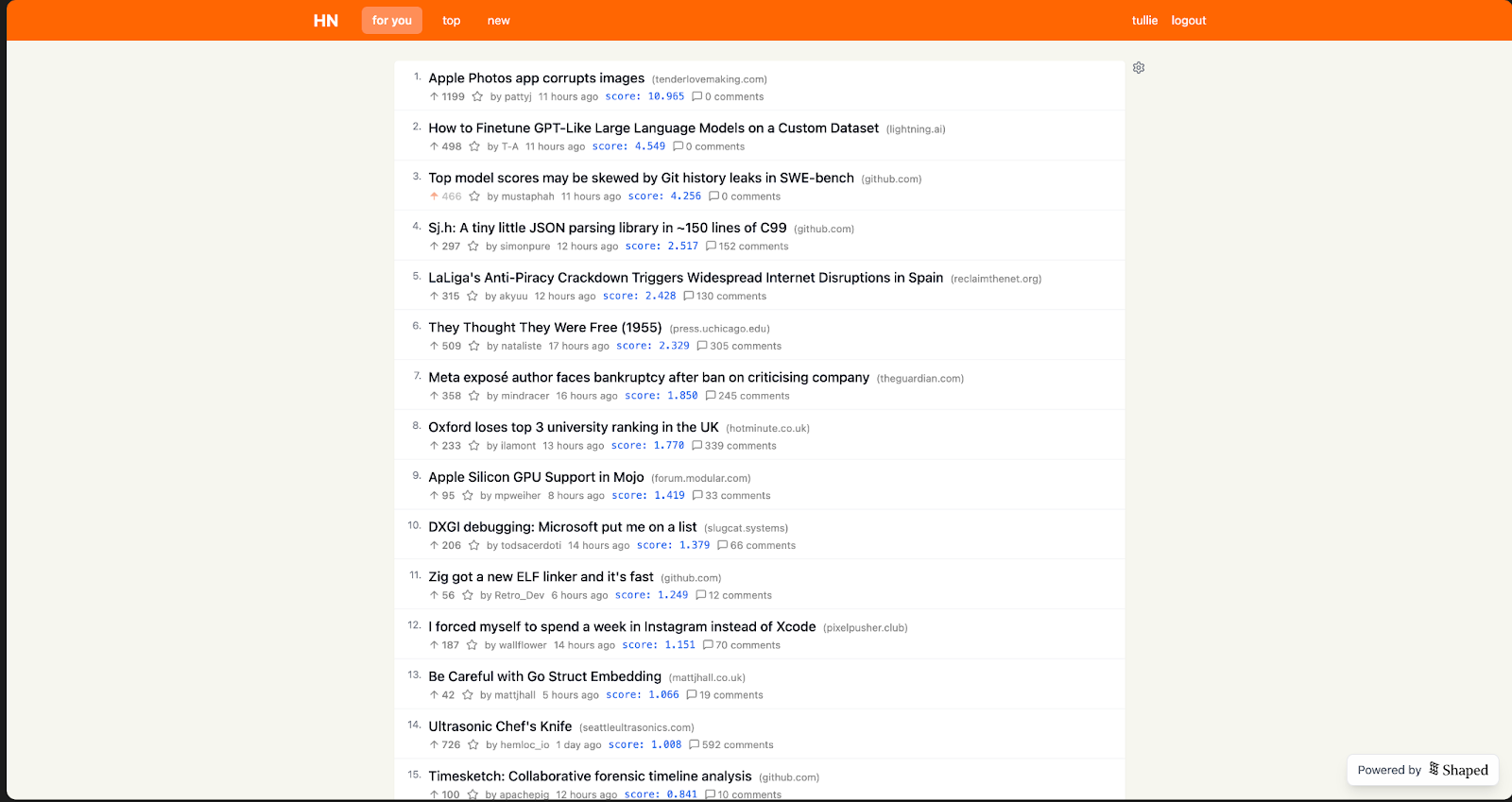 Top feed: (item.score - 1) / ((((now_seconds() - item.published_at) / 3600) + 2) ** 1.8)
Top feed: (item.score - 1) / ((((now_seconds() - item.published_at) / 3600) + 2) ** 1.8)
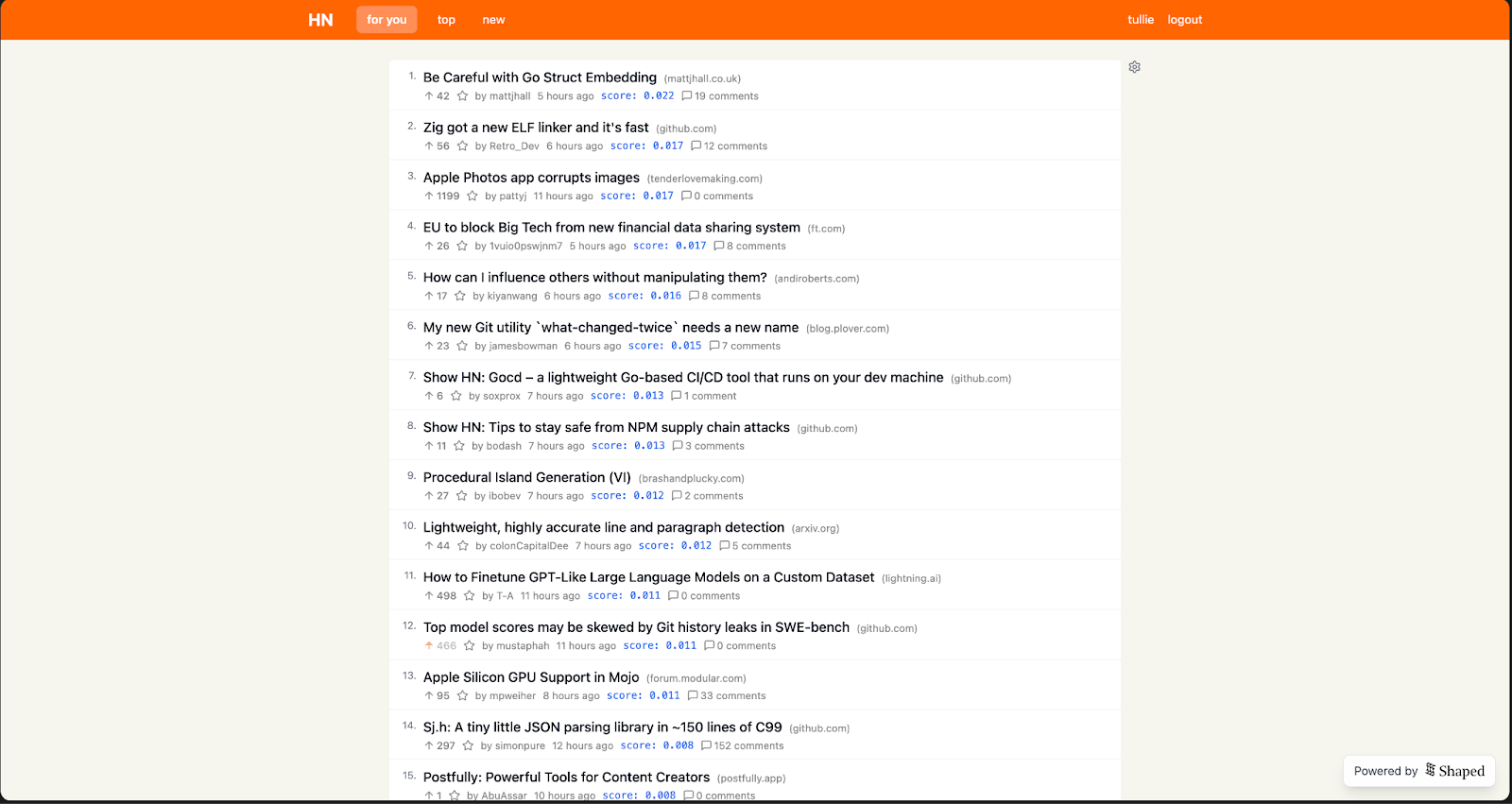 Personalized feed: ((item.score / 1000) + cosine_similarity(text_encoding(item), pooled_text_encoding(user.recent_interactions))) / ((((now_seconds() - item.published_at) / 3600) + 2) ** 1.8)
Personalized feed: ((item.score / 1000) + cosine_similarity(text_encoding(item), pooled_text_encoding(user.recent_interactions))) / ((((now_seconds() - item.published_at) / 3600) + 2) ** 1.8)
As you can see from the images, the personalized feed isn’t dramatically different from the “top” feed. However, I’ve already noticed a few key trends where it deviates:
- It consistently boosts content about software engineering and AI.
- More “new” content appears in the feed. This makes sense — the personalization term in the ranking function effectively acts as “free upvotes,” giving newer items a better chance to surface.
Overall, this is a great starting point. I’m excited to start using it for my daily news intake and adapt it based on feedback.
Future Improvements and What’s Next
I kept this first version as simple as possible, mostly because I didn’t have the data to do anything more scientific. My hope is that by releasing this and sharing it, we can build a set of 10k+ interactions. Then I can start adding more collaborative signals and using weaker engagement types (like clicks and time-spent).
If it gets used more widely, I can also start doing more A/B tests to continue tweaking the algorithm. This is really how big tech companies do it—it’s not necessarily about the algorithms themselves, but the ability to run experiments quickly and evaluate the results.
There are a few other things I’d like to monitor with the current feed:
- Diversity of content: This can be an issue with content-filtering. If I only interact with a narrow set of items, I could put myself in a filter bubble.
- Smarter exploration: The recency decay in the HN algorithm is fairly rudimentary. This causes a lot of good content to drop off the front page quickly. It would be interesting to try something like a multi-armed bandit algorithm to better handle the explore-exploit problem.
Finally, there are several other features I want to add:
- Similar stories: Using a simple content similarity algorithm to find related content.
- Semantic search: Algolia’s search is keyword-based. Shaped provides hybrid search, combining lexical and dense vector search, which could be a powerful upgrade.
- Personal configurability: Since Shaped allows for so much configuration, there’s no reason we can’t let the end-user choose their own ranking system. If someone wants to play around with their own decay or relevance settings, why not let them?
Conclusion
I’ve always wanted a personalized HackerNews feed that prioritizes the content I actually enjoy. I would say we’ve achieved that, as I’m now consistently getting topics about AI and other interests pushed to the top of my feed. I was also worried that some of the serendipity would be lost, but I think the trade-off we’ve struck between content, popularity, and recency works well.
I’m excited to see if others get the same value as me and to keep improving the algorithm as we get more data. Please let me know if you find it helpful! And finally, if you want to use Shaped for any of your own “For You” feed projects, please reach out to the team.
Want us to walk you through it?
Book a 30-min session with an engineer who can apply this to your specific stack.