What if you could improve your agent’s retrieval performance AND make it more efficient by fine-tuning a model on your corpus? That’s exactly what a new paper called Learning to Retrieve from Agent Trajectories suggests.
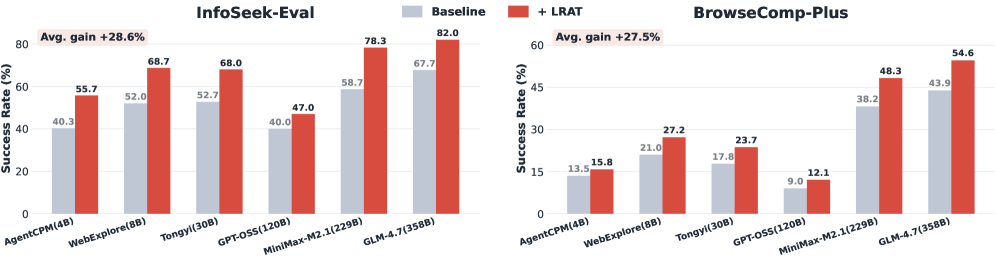
The paper suggests a learning to retrieve approach can improve an agent’s ability to answer correctly and complete tasks with less steps. The authors propose a training framework called LRAT and demonstrate success rate gains of up to 38% and agents solving tasks in 30% fewer steps, across six models.
Your search is built for a human
For decades, information retrieval research has operated on a simple assumption: the thing consuming results is a human.
When a human searches, they satisfy an immediate informational need. They scan results, click a promising result, and move on. When an agent searches, it is gathering evidence as a turn in a multi-turn loop. It’s not finding information, it’s gathering evidence to advance toward a goal.
For agents, the query is an action, not a question.
The emphasis on human queries is in every major search strategy:
- Dense embedding models like ModernBERT are trained on datasets derived from human search queries and results
- BM25 is designed around short, keyword-driven, human query patterns
- MS MARCO, the dominant test dataset for retrieval models, is built from Bing queries and clicks from human searchers
- Commercial search APIs like Google are built on ranking systems trained on view and click data from humans
- Traditional vector databases like Pinecone ship with models trained on human search patterns
The solution is a learning-to-retrieve model
This approach makes sense when your user is a person. But the paper demonstrates that optimizing it for an agent has big gains.
The paper suggests a twist on classic learning to rank, by offering a learning to retrieve approach. In learning to rank, we train a machine learning model like a neural network or decision tree to choose the optimal ranking for a set of candidate items, based on a set of interactions (typically clicks, views).
In learning-to-retrieve, we fine-tune a dense embedding to decide which documents are worth giving the agent in the first place. Rather than ordering a set of items from most to least relevant, the model fetches a small subset of documents from a corpus of millions.
The paper’s key insight is the inputs for that model: instead of using human clicks and views, they use agent trajectories.
Using agent traces to tune an off-the-shelf embedding model
The paper’s insight is what we train that retrieval model on - an agent trajectory. Instead of using clicks and queries, it trains on the actions in the agent loop.
Three numbers that summarize an agent’s journey
Each trajectory is a sequence of thinking, searching, browsing, and post-browse reasoning steps. To constrain the search space, the authors extract three minimal signals:
- Query-document pairs – the input and search result
- Labels for each pair – if the result was browsed, it gets a positive. Otherwise negative
- Weight based on reasoning length. Longer trace = more relevant
These three numbers get fed into a process called contrastive learning, where the embedding model is trained to pull the vectors for positive query-document pairs closer and negative pairs further apart.
Over a huge training set, this process tunes an off-the-shelf model using an agent’s actions. The authors run this contrastive learning process on two embedding models, Qwen3-Embedding-0.6B and MultilingualE5-Large-Instruct.
The content of an agent trajectory
Each trajectory can be long and messy, with a dump of the agent’s “thoughts” plus all results and metadata. A full agent trajectory can look like this:
| Step | Phase | What happens |
|---|---|---|
| 1 | THINK | The agent generates reasoning based on the query, expanding the input context and articulating what it should search for |
| 2 | SEARCH | The agent retrieves a set of results |
| 3 | POST-SEARCH THOUGHT | The agent decides which result to browse |
| 4 | BROWSE | The agent reads one result in full |
| 5 | POST-BROWSE THOUGHT | The agent synthesizes a response from the gathered data, and decides whether to search and browse again |
| 6 | FURTHER THINK/SEARCH/BROWSE STEPS | Agent may do steps 2–5 multiple times |
| 7 | ANSWER | The agent synthesizes a response from the previous actions |
The full trajectory could span thousands of tokens, but only three numbers get used for training.
What agent trajectories tell us about relevance
Browsing is a necessary condition for relevance
Similar to human search, browsing a document is a natural positive signal. If an agent chooses to browse a document, it’s likely that it is relevant to the query. Searches without browsing are less likely to result in correct answers.
Unbrowsed documents are reliable negatives, unlike unclicked human results
A surprising insight is that when an agent does not browse a document, the negative signal is stronger than the equivalent in human search. When a human skips a result, it might be because it was irrelevant – or they merely didn’t scroll deep enough.
Agents don’t have this problem: the agent actively considers every result and decides which is worth reading in full. You know result 25 and result 2 were both considered equally. If an agent skips a result, it’s because it was skipped on purpose.
Post-browse reasoning tells you how much a document actually matters
After reading each document, the agent generates a reasoning trace. That trace length predicts how useful a document was: results that contain relevant information trigger longer reasoning than irrelevant ones.
The 38% improvement is accuracy and cost
The authors tested the framework across two benchmarks: InfoSeek-Eval and BrowseComp-Plus. Their agents used reasoning models ranging from 4B to 358B parameters:
| Metric | Improvement |
|---|---|
| Success rate | Up to +38% relative |
| Evidence recall | Up to +38% relative |
| Steps to solution | Up to -30% |
30% fewer steps to find an answer mean less tokens and faster results
For agent companies, the step reduction matters as much as the accuracy gains. By reducing the number of steps an agent needs to reach a correct answer, you reduce token cost and improve user experience in one shot.
You can’t just throw everything into a prompt and hope for the best
Even when using huge foundation models like MiniMax-M2.1, or deep research models like Tongyi 30B, LRAT improved success rate by at least 10%. This is a reliable signal that you cannot compensate for bad retrieval with a good model.
Conclusion: how to incorporate these findings into your agent
What’s great about these findings is that you likely have the basic architecture in your agent stack. Every time your agent runs, it generates a trajectory: which documents are retrieved, which it used, and how much it reasoned. That’s your training data.
To take advantage of this, start logging three three things: query-document pairs from each search, whether the document was browsed, and the length of an agent’s reasoning. Once you have enough data, you can tune an embedding model on the results.
Want to implement this in Shaped?
The beeFormer model policy fine-tunes a text embedding model on interactions. Start by syncing your documents and agent trajectories to Shaped.
Then create an engine with the beeFormer policy to tune an embedding model on these trajectories.
Once trained, your agent can use the beeFormer embedding to retrieve the most relevant documents for a user’s query, given the success of previous queries.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.