
In the previous post we experimented with using LLMs as a recommendation systems. This showed promising results but wasn’t without its challenges. Recently more and more people began exploring the potential of language models as a new way to suggest information. In a recently published paper titled How Can Recommender Systems Benefit from Large Language Models: A Survey a research team attempted to codify and summarize this potential as well as challenges that will arise with running LLMs as recommendation systems. Welcome to another paper digest where we dive deep and summarize the survey, discussing the new exciting potential of LLMs.1 2
Motivation
The explosion of recommendation systems coincides with development of online services and the work to address users overload with information and the need for its higher quality. The common learning objective for a deep learning-based recommender system is to estimate a given user’s preference towards each candidate item, and then arrange a ranked list of items presented to the user. This is true despite the various forms of application tasks (such as top-N recommendation or sequential recommendation).
At the same time large language models (LLM) have demonstrated significant emergent capabilities in the field of natural language processing (NLP), including reasoning and in-context few-shot learning, as well as a vast repository of open-world information compressed in their pretrained model parameters. Even while LLM is achieving tremendous success in a variety of deep learning applications, it is natural to ask the following question: How can recommender systems benefit from large language models for performance enhancements and user experience improvements?
So to address this, this blog will be split into 4 parts:
- In the first one we will talk about where we can integrate the LLMs as there are sensible limitations to inclusion of new models/pipelines. There are places where they make complete sense and there are others where a simpler solution is preferred.
- In the second part we talk about how to integrate LLMs into the existing recsys pipelines. There are multiple modes of inclusion for example you can tune and not tune the LLM on your data, as well as include CRM (conventional recommendation methods) as part of your pipeline.
- We also mention challenges that arise from the industry to apply these new paradigms.
- And discuss potential future directions to improve the inclusion of LLMs into the recommendation systems of the future.
Where to adapt LLMs?
So where can we even adapt the LLMs, we have already talked about the potential they have, but with so many possibilities we need to think about their place in the pipeline. In a figure below we can see how many approaches just in the past 2 years were developed with the goal to integrate large language models as a means to improve existing recsys pipeline. To understand its specifics I will briefly explain what each sector means:
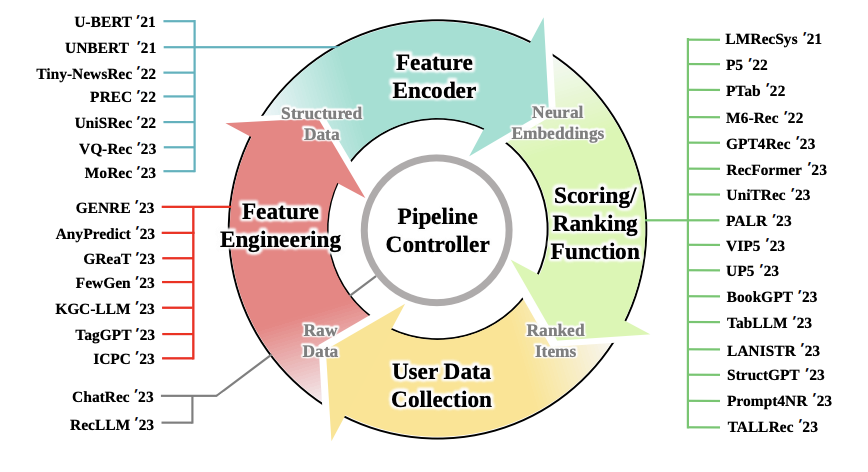
- User data collection is a process which gathers user input from online services by recommending products to users. This feedback might be explicit (ratings) or implicit (click signals).
- Feature engineering is the process of choosing, modifying, enhancing, and changing the unstructured data gathered online (such as one-hot encoding) into structured data.
- In the subsequent stage, the feature encodercreates the neural embeddings for the scoring/ranking functions using the structured data as input. The embedding layer for one-hot encoded categorical features is how it is often formulated.
- Another basic component of recommendation is the scoring/ranking function, in which several machine learning techniques are created to choose the most pertinent items to meet users’ information needs.
- The aforementioned recommendation pipeline’s operations are monitored and managed by a pipeline controller. It can provide fine-grained control over various stages of recommendation (such as matching, ranking, and reranking).
So now that we know what they do let’s talk business and discuss how LLMs can be integrated into those.
LLM for feature engineering
What LLM can do heere is take the original data input and generate additional textual features as a way to augment the data. This approach was demonstrated to work well with tabular data, and was further extended by using the LLMs to align out of domain datasets on the shared task. They can also be used to generate tags and model user interest.
LLM as feature encoder
For conventional recommendation systems the data is usually transformed into one-hot encoding + an embedding layer is added to adopt dense embeddings. With LLMs we can improve the feature encoding process in two ways: we can add better representations for downstream models via the semantic information extracted and applied to the embeddings, achieve better cross-domain recommendations where feature pools might not be shared.
For example UNBERT uses BERT as a way to improve news recommendations via better feature encoding. And ZESREC applies BERT in order to convert item descriptions into a zero-shot representations of a continuous form.
LLM for scoring/ranking
A common approach explored is to use the LLM as a means to rank the items based on their relevance. Many methods use a pipeline where the output of LLM is fed into a projection layer to calculate the score on the regression or classification task. But recently some researchers proposed to instead use the LLM to deliver the score directly. TALLRec for example, uses LLM as a decoder to answer a binary question appended to the prompt, other team used LLM to predict a score in a textual mannerand formatted it with careful prompting.
LLMs can also be successfully used for direct item generation. This would be similar to our approach in the previous blogpost. These approaches also can be hybridized and used in tandem.
LLM as a pipeline controller
This approach largely stems from the notion that LLMs possess emergent properties, that is they can perform tasks that smaller models could not, these can be in context learning and logical reasoning. However, you should be aware that many researches actively dispute the claims that LLMs possess any emergent abilities and imply that these are instead a product of imperfect statistical methods that bias the evaluation, suggesting it may not be a fundamental property of scaling AI models
Some researches even suggested a full frameworkthat utilizes the LLM to manage the dialogue, understand user preferences, arrange ranking stage and simulate user interaction.
You may have noticed that the user data collection piece is missing. It is true, not a lot of work has been done to explore the LLM’s potential in this domain. LLMs here can be used to filter biased, hateful data and select best representations, or find meaningful, relevant information from a sea of input. They can be used in surveys as customer experience collectors and many more.
How to adapt LLMs?
Now that we know where we can include the models into our pipeline let’s talk about how we can do so.
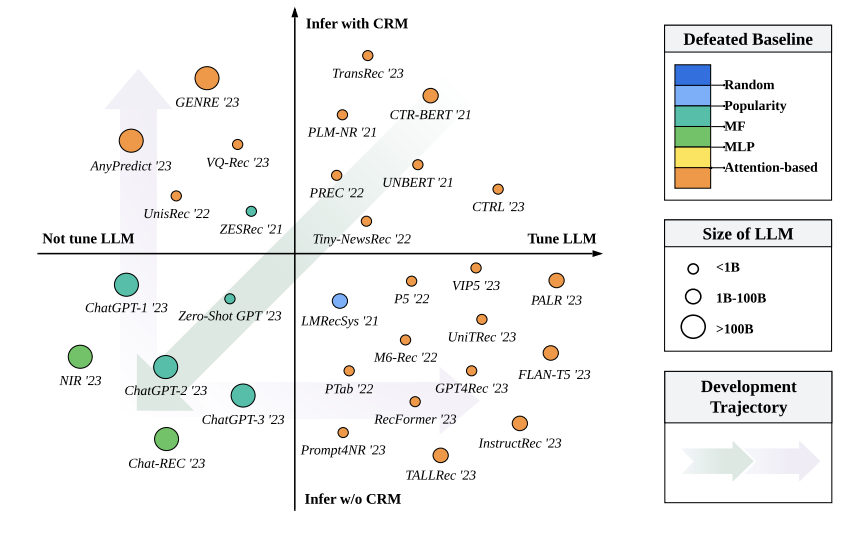
Generally we can have 4 cases. From the diagram above we can see how the current approaches are distributed given the choice of tuning and not tuning the LLM during training phase (this includes using efficient methods like adapters and LoRA), and whether to use CRM as a recsys engine or not. By quadrants (in the figure models approaches by performance):
- Here we can see the approaches that both utilize LLM tuning and CRM inference. What is notable here is the model size. Approaches here use LLMs as feature encoders for semantic representations, this allows for lightweight setup but the key abilities of larger models (reasoning, instruction following) remain unexplored.
- Inferring with CRM but not tuning the LLM utilizes different abilities of LLMs (reasoning, richer semantic information) and a layer of CRM to either prerank items before inserting information into LLM or as a layer for LLM output.
- These approaches investigate zero-shot performance of LLMs and here they are all largely reliant on bigger LLM sizes and the idea behind it being that larger models have better latent space. This being said these approaches lag behind in performance and efficiency compared to light-weight CRM tuned on training data, indicating the importance of domain knowledge
- These approaches are similar to 1 in a way that they use lighter model sizes but they also go beyond the simple econder paradigm and use LLMs in greater capacity in the recsys pipeline.
Collaborative knowledge
From the diagram above we can observe the performance difference between groups in 3 and 1,2,4, indicating that while 3 had the largest model sizes, the task of recommending items requires specialized domain knowledge. Therefore finetuning indeed increases the performance. Which means you can either tune the LLM during training and inject in-domain collaborative knowledge, or during inference inject this information via CRM from a model centric perspective.
Reranking hard samples
Although as demonstrated, larger models with zero-shot performance do not work as well in a context of a recsys. Researchers found that they are surprisingly good at reranking hard samples. They introduce the filter-then-rerank paradigm, which uses a pre-ranking function from conventional recommender systems to pre-filter simpler negative items (e.g., matching or pre-ranking stage in industrial applications) and creates a set of candidates with more difficult samples for LLM to rerank. This should improve LLM’s listwise reranking efficiency, particularly for APIs that resemble ChatGPT. This discovery is useful in industrial settings, where we may want LLM only handle hard samples and leave other samples to light-weight models to reduce computational expenses.
Does size matter?
It is difficult to tell. Given finetuning on the domain data, all models large and small give comparatively good performance. As there is no unified recsys benchmark to measure the performance of larger and smaller models and their relative success, this question is still up for evaluation. I would argue that depending on your application and where in the pipeline you want to include the LLM you should select different model size.
Challenges from the industry
But this is still all in an academic setting, there are serious specific engineering challenges that come from the industry that I want to mention here. First istraining efficiency. Recall the articles about training cost of the GPT-3 and 4, and you can already start to get a headache about the cost of repeated finetuning of your LLM for a recommendation data pool that is constantly shifting and expanding. So you have expanding data volume + update model frequency (day-level, hour- level, minute-level) + underlying LLM size = trouble. To address this parameter-efficient methods are recommended for finetuning. The benefit to using larger model sizes lies in producing more generalized and reliable output via just a handful of supervisions. Researchers suggest adopting the long-short update strategy, when we leverage LLM for feature engineering and feature encoder. This cuts down the training data volume and relaxes the update frequency for LLM (e.g.week-level) while maintaining full training data and high update frequency for CRM. This way LLM can give the CRM aligned domain knowledge and CRM can be used as a frequently updated adapter for the LLM.
Second important part is inference latency, something I have dealt with myself in the past.Recommendation systems are usually real-time services and applications that are extremely time sensitive, where all stages (matching, ranking, etc.) should be done in tens of milliseconds. LLMs famously possess large inference time, so this creates a problem. To address this we recommend using caching and precomputing, whichhas proven to be effective, hence you can cache dense embeddings produces by an LLM. Another good strategy is reduction in model size for final inference via techniques like distillation and quantization, this introduces a bit of tradeoff between model size and performance so a balance has to be found. In other ways LLMs can be used for feature engineering which does not bring extra burden of computation to the inference phase.
Third is a challenge of dealing with long-text inputs. For LLMs we need to often use prompts and given that a lot of user data is collected the general industry recsys requires longer user history. But LLMs don’t perform well with large textual inputs. This can be partially because the original training corpus contained shorter inputs and the distribution of in-domain text is different from the original training data. Additionally, using larger text sizes can induce memory inefficiency and break the limits of context window causing LLM to forget information and produce inferior output.
In the same categoryID indexing should be mentioned. Recall that large amounts of data for recsys possess no semantic information. Here approaches are divided into 2 camps. One completely abandons non-semantic IDs and instead focuses on building interfaces using natural language alone, this seems to improve cross-domain performance and generalization. However, other choose to potentially sacrifice these gains in favor of im domain performance, by introducing new embedding methods that account for IDs like P5. Or cluster related IDs together, or attach semantic information to them.
The last but not least important considerationsarefairness and bias. An underlying bias of LLMs is an active research area. Further finetuning and the foundation model choice have to account for bias in the data to make recommendations fair and appropriate. Careful design considerations need to be made to address impact of sensitive attributes (gender, race) and focus model on historical user data, possibly with filtering and designed prompting.
Conclusions and the future
In this post we covered the landscape of current LLM approaches in recsys. This area of research is very fresh and no doubt in the coming years we will see new developments addressing challenges and potential mentioned in this blogpost. For takeaway the 2 great directions for the future of LLM in recsys can be:
- A unified benchmark which is of urgent importance and need in order to provide convincing evaluation metric to allow fine grained comparison among existing approaches and it is expensive to reproduce many experimental results of recsys with LLMs
- A custom large foundation model tailored for recommendation domains, which can take over the entire recommendation pipeline, enabling new levels of automation in recsys.
References
1 For more reading or if you are curious please visit this great repository that hosts the papers about recys LLMs and stay tuned for more from our blog
2 Images are sourced from the paper
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.