
But an engine is useless without fuel. The highest-performing engine in the world will sputter and fail if it’s fed low-quality data, or if the fuel can’t be delivered fast enough. In a ranking system, that fuel is data, and the delivery systems are a set of highly specialized data stores.
Standard databases like Postgres or MySQL are not designed for the unique demands of high-throughput, low-latency machine learning inference. A production ranking system relies on a specialized data layer. In this post, we’ll deconstruct the two most critical components of this layer: the Feature Store and the Vector Database.
The Feature Store Deep Dive
The scoring models we discussed in our “Anatomy” series rely on a rich set of features to make their predictions. The engineering challenge is that these features are needed in two very different contexts:
- Offline Training: We need access to massive, historical datasets of all features to train our models. This requires high-throughput access to terabytes of data.
- Online Inference: We need to fetch the exact same features for a given user and a set of candidates in real-time, with a latency budget of a few milliseconds.
This dual requirement creates the most insidious problem in production ML: online/offline skew. If the way you compute a feature for training (e.g., a daily batch job in Spark) is even slightly different from how you compute it for serving (e.g., a real-time lookup in a Python service), your model’s performance will degrade silently and catastrophically.
A Feature Store is a centralized platform designed to solve this exact problem.
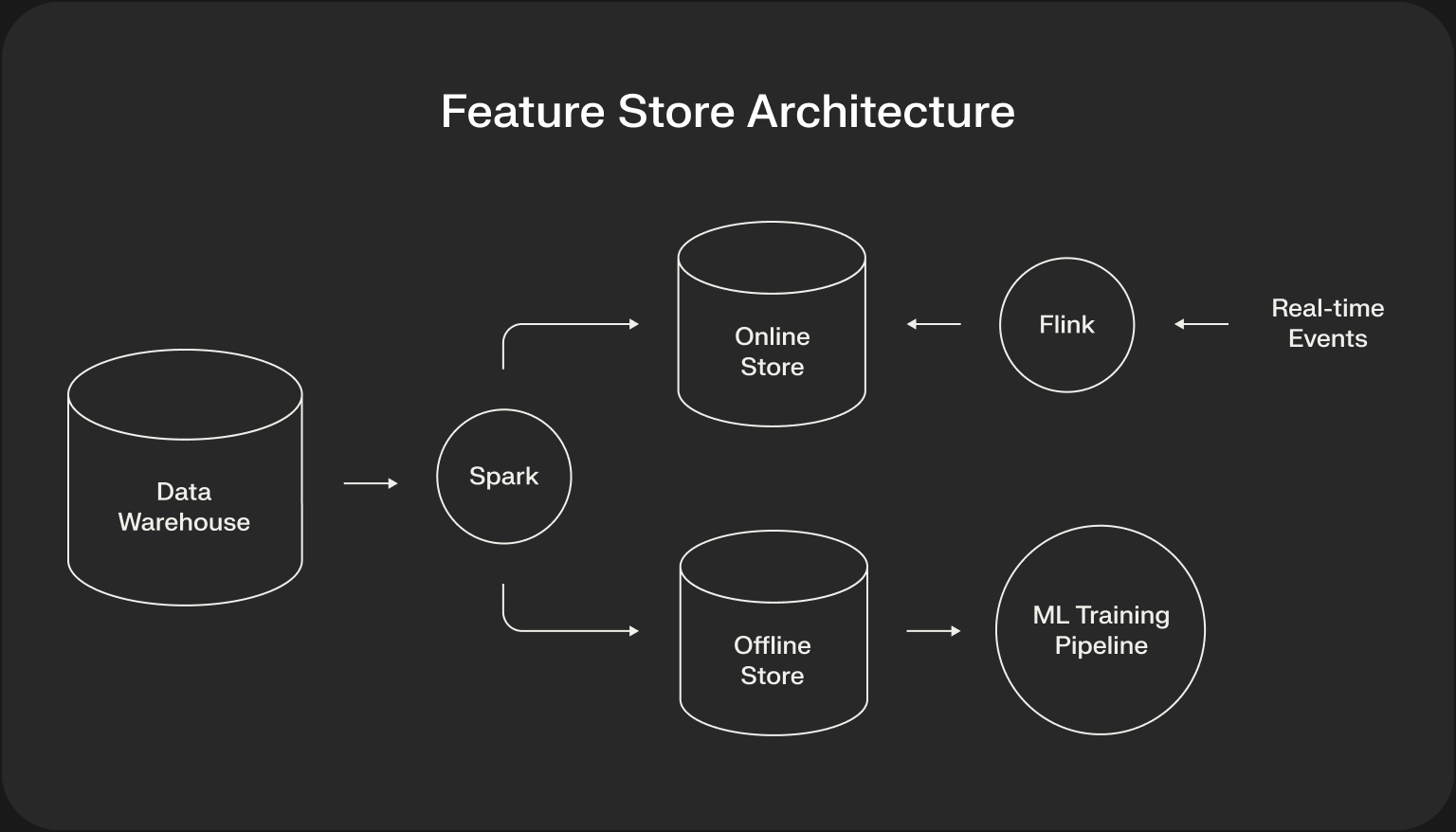
The Feature Store Architecture
The core architectural pattern of a feature store is a dual-database design that provides two interfaces to the same underlying feature data:
- The Offline Store: A high-throughput data store (e.g., a data warehouse like BigQuery or a data lake like S3 with Delta Lake). This is the source of truth for historical feature data used in model training.
- The Online Store: A low-latency, key-value data store (e.g., Redis, DynamoDB). This store holds the most recent feature values for every user and item, optimized for fast lookups at inference time.
A feature store provides an abstraction layer that ensures that the same feature generation logic populates both stores, eliminating skew by design.
Technology Choices & Trade-offs
- The DIY Approach (e.g., using Redis and Airflow):
- Pros: Maximum control, leverages existing infrastructure, and can be cheaper to start.
- Cons: This is a trap for many teams. You are now responsible for building and maintaining the complex data pipelines that keep the online and offline stores consistent. This includes handling backfills, point-in-time correctness for training data, and monitoring for data quality issues. This “hidden” engineering cost is massive.
- Managed Feature Store Platforms (Tecton, Chalk, or open-source Feast):
- Pros: They solve the online/offline skew problem as their primary value proposition. They provide a declarative framework for defining features, and the platform handles the underlying data engineering (dual writes, backfills, etc.). This drastically accelerates ML development.
- Cons: Higher direct cost (for commercial platforms), potential for vendor lock-in, and it introduces a new, complex piece of infrastructure that the team must learn and manage.
Decision Framework: If your team is small, your feature set is simple, and you have strong data engineering discipline, a well-managed Redis cluster and a robust set of Airflow DAGs might suffice. If you have multiple teams building models, a complex and rapidly evolving feature set, and a high reliability requirement, a managed platform will almost certainly pay for itself in engineering hours saved and production incidents avoided.
The Vector Database Deep Dive
The second critical component of our data layer is the Vector Database. Its purpose is to solve a single, difficult problem: finding the most similar vectors to a given query vector from a corpus of millions or billions, in milliseconds. This is known as Approximate Nearest Neighbor (ANN) search.
A vector database is crucial for both semantic search (finding documents that are semantically similar to a query) and embedding-based recommendations (finding items similar to a user’s interest vector).
Technology Choices & Trade-offs
The vector database space is evolving rapidly. The options can be broken down into a few categories:
- Libraries (FAISS, ScaNN):
- Pros: These are the engines of vector search, created by Meta and Google respectively. They are open-source and offer unparalleled performance and control. You can tune every aspect of the index (quantization, number of probes, etc.) to meet your exact latency/recall trade-off.
- Cons: It’s just a library. You have to build the entire car around the engine: the serving API, the infrastructure for building and periodically swapping massive indexes, and the logic for scaling it.
- Managed Vector Databases (Pinecone, Weaviate, etc.):
- Pros: A fully managed, turn-key solution. They provide a simple API, handle scaling and index management automatically, and often include crucial features like metadata filtering. This dramatically reduces time-to-market.
- Cons: Can be expensive at scale, performance can sometimes be a “black box” where you have less control over the underlying index parameters, and you are dependent on the vendor’s roadmap.
- The New Wave (LanceDB, In-process DBs):
- Pros: A new, serverless paradigm. They often use a zero-copy data format (like Apache Arrow) and run in-process with your application, avoiding network hops. This can be much cheaper and simpler for analytics and certain serving workloads.
- Cons: This is a newer approach. While maturing quickly, it may not have all the production-hardening or the same ecosystem maturity as the managed services for all use cases.
A Critical Detail: Pre- vs. Post-Filtering
One of the most important practical considerations when choosing a vector database is how it handles metadata filtering. Imagine you want to find “semantically similar articles” but only from the “tech” category and published in the “last 7 days.”
- Post-filtering: The system first performs the ANN search over the entire vector index to get the top 1000 candidates, and then filters those 1000 results by your metadata criteria. This is inefficient, as much of the search work is wasted on items that will be filtered out.
- Pre-filtering (or filtered search): The system uses the metadata filters to constrain the search space before or during the ANN search. This is vastly more efficient but is a much harder engineering problem for the database to solve.
Support for efficient pre-filtering is a key differentiator between vector database solutions and should be a top consideration in any evaluation.
Conclusion
A modern ranking system is a data-intensive application that runs on a foundation of specialized data infrastructure. The Feature Store solves the critical online/offline skew problem, enabling reliable feature engineering. The Vector Database provides the sub-linear time scaling needed for high-performance semantic retrieval. Choosing the right tools for these jobs—and understanding the trade-offs between building and buying—is a key architectural decision.
We’ve designed our serving engine and fueled it with high-performance data stores. But how do we connect the two? How do we automate the process of training models on our offline data and safely deploying them to our online services?
In our next and final post in this series, we will explore the MLOps Backbone that makes this all possible.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.