- In Part 1, we designed the Serving Layer, a scalable microservice architecture for real-time ranking.
- In Part 2, we dove into the Data Layer, exploring the critical roles of Feature Stores and Vector Databases.
We have all the pieces on the board: a factory floor full of powerful machinery (our serving infrastructure) and a warehouse full of high-quality raw materials (our data stores). But how do we connect them? How do we create an automated, reliable assembly line that can take our raw data, build a new model, and safely deploy it to production with minimal human intervention?
This is the domain of MLOps. It’s the set of practices and tools that brings software engineering discipline to the experimental, often chaotic world of machine learning. A production ranking system requires a robust MLOps backbone to function as a reliable, ever-improving “model factory.”
Training Pipelines & Orchestration
The first step in automating our system is to move beyond running train.py on a laptop or a single VM. A production training process is a multi-step pipeline that needs to be executed reliably and repeatedly. A typical ranking model training pipeline might include:
- Data Extraction: Pulling the latest training data from the Offline Feature Store.
- Data Validation: Checking for data quality issues, unexpected shifts in distribution, etc.
- Model Training: Running the actual training job, often on specialized hardware.
- Model Evaluation: Calculating offline metrics (like NDCG) on a hold-out test set.
- Model Validation: Comparing the new model’s metrics against the currently deployed model.
- Model Registration: If the new model is better, publishing it to a central Model Registry.
Executing these steps manually is slow and error-prone. We need a workflow orchestrator to manage this pipeline.
-
Technology Choices:
- Apache Airflow: The classic, battle-tested choice. It’s great for complex, schedule-based batch jobs but can be heavy for ML-specific workflows.
- Kubeflow Pipelines: A Kubernetes-native solution. It’s excellent if your entire stack is built on Kubernetes, as it allows you to define each step of your pipeline as a container.
- Metaflow: An open-source tool from Netflix that is highly focused on the data scientist’s user experience. It makes it easy to write Python-native workflows that can scale from a laptop to the cloud.
The choice of orchestrator depends on your team’s existing infrastructure and expertise, but the principle is the same: codify your training process into a repeatable, automated pipeline.
Experiment Tracking and Model Registry: The System’s Memory
Machine learning is an experimental science. You will train hundreds of versions of a model, with different hyperparameters, features, and architectures. Without a system of record, this quickly descends into chaos.
- Experiment Tracking: This is the lab notebook of MLOps. For every training run, you log:
- The code version (Git commit hash).
- The dataset version.
- The hyperparameters.
- The resulting evaluation metrics.
- The trained model artifact itself.
- Model Registry: This is a centralized repository that versions your production-ready model artifacts. It provides a source of truth for your serving systems and allows you to easily roll back to a previous version if a deployment goes wrong.
-
Technology Choices:
- MLflow: The most popular open-source choice. It provides a clean UI for tracking experiments and includes a robust Model Registry.
- Weights & Biases (W&B): A commercial platform that offers a highly polished, collaboration-focused experience for experiment tracking.
Using these tools is non-negotiable for any serious ML team. They are the foundation of reproducibility and governance.
CI/CD for ML: Automating the Release Cycle
We now have an automated training pipeline that produces a validated model and registers it in our Model Registry. How does that model get safely deployed to the Kubernetes cluster we designed in Part 1? This is the “last mile” of MLOps: Continuous Integration/Continuous Deployment (CI/CD) for ML.
This pipeline connects your ML artifacts to your production infrastructure.
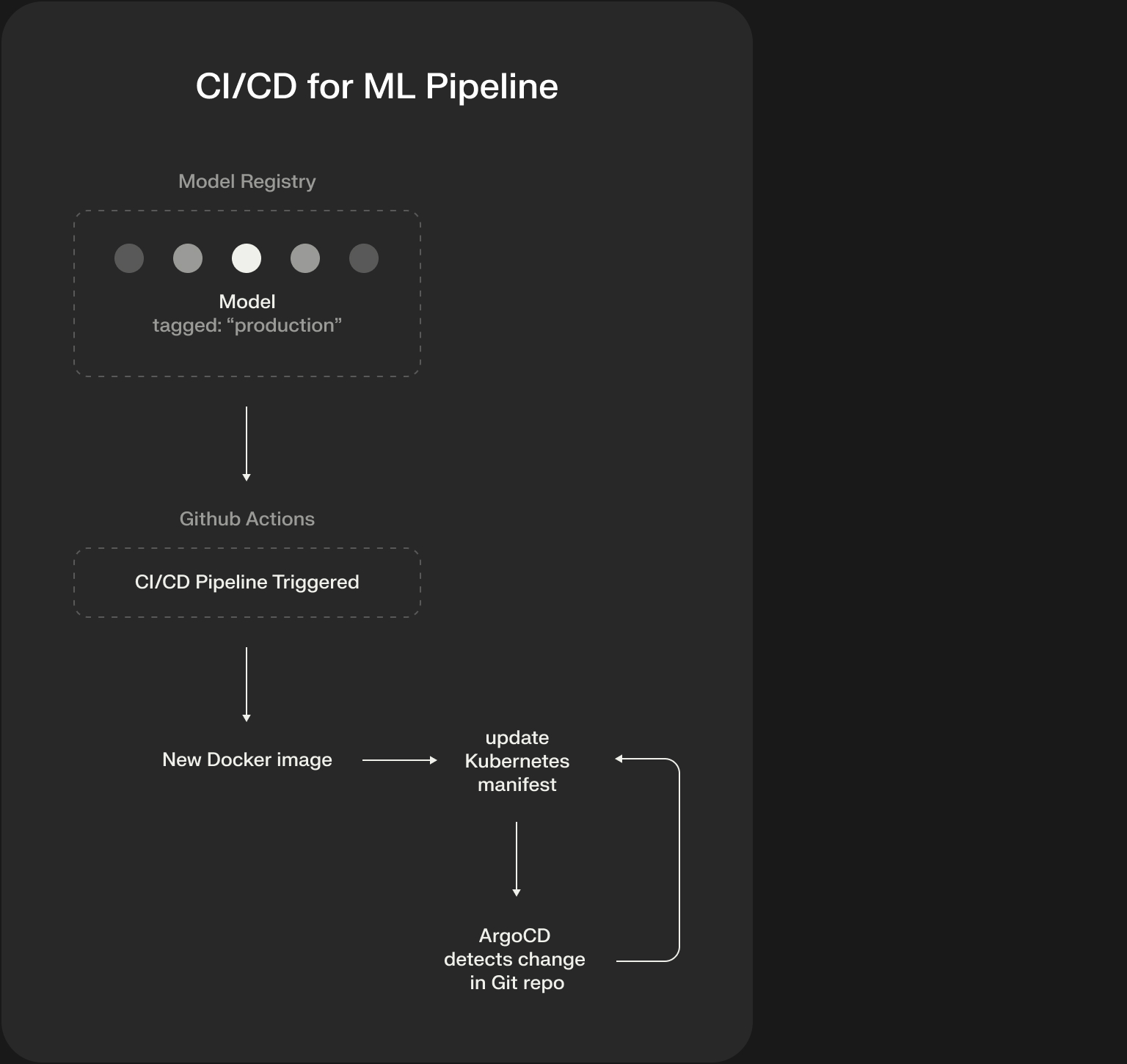
This GitOps approach—where a Git repository is the single source of truth for your production state—is incredibly powerful. It makes your deployments auditable, repeatable, and easy to roll back. Instead of manually running kubectl apply, you simply merge a pull request.
Monitoring: Closing the Loop
Once the new model is deployed, our job isn’t done. We need to monitor its performance to ensure it’s behaving as expected and actually improving the product. This requires a multi-layered monitoring strategy:
- System Monitoring: This is standard infrastructure monitoring. Are the pods healthy? What are the latency (P99), error rates, and CPU/GPU utilization? (Tools: Prometheus, Grafana).
- Data Monitoring: Is the data our live model is receiving consistent with the data it was trained on? This is prediction drift detection. If the distribution of input features changes, the model’s performance will degrade.
- Model and Business Monitoring: Is the new model actually better? This is where we track the online A/B test metrics. We monitor not just the model’s predictions (e.g., average CTR) but, more importantly, the downstream business metrics (e.g., user engagement, conversion rates).
Series Conclusion: The Unseen 90%
We’ve now completed our journey through the infrastructure of a modern ranking system. We designed a scalable serving layer, provisioned it with specialized data stores, and finally, wrapped it in a robust MLOps backbone to automate its lifecycle.
It’s often said that machine learning is 10% models and 90% infrastructure. While that might be an exaggeration, it contains a fundamental truth. The most brilliant model in the world is useless without a reliable, scalable, and maintainable system to power it.
The architecture we’ve outlined—a decoupled microservice serving layer, a specialized data layer with feature and vector stores, and an automated MLOps pipeline—is a powerful and proven blueprint. It’s a system designed not just to serve a single model, but to function as a continuously learning “model factory,” a platform for rapid experimentation and reliable iteration. Building this infrastructure is a significant undertaking, but it’s the foundation upon which all modern, world-class ranking systems are built.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.