Quick Answer: What Are Multi-Objective AI Agents?
Multi-objective AI agents rank results using multiple business criteria (profit, stock, quality, user preference) instead of just semantic similarity. This is done via value model expressions—SQL-like formulas that blend behavioral ML models with business attributes in a single query.
Key Takeaways:
- Traditional RAG = semantic similarity only (~42% precision@5)
- Multi-objective ranking = similarity + business logic (~68% precision@5)
- Value models = declarative expressions like 0.4 * taste_model + 0.3 * item.margin
- Update weights in seconds via console (not code deployments)
- Production latency: 50-100ms vs 250-500ms (traditional stack)
- Best for: marketplaces, e-commerce, travel, any revenue-impacting recommendations
The $40,000 Recommendation Mistake
Your AI shopping assistant just suggested wireless headphones to a customer. Perfect semantic match. Great reviews. In stock at $89.99.
One problem: The customer bought the exact same pair yesterday.
When they return it (again), your marketplace eats the $12 shipping cost. Again. Multiply by 1,000 frustrated users per month, add processing overhead, and you’ve burned $40,000 on an agent that’s semantically brilliant but business-blind.
This isn’t hypothetical. It’s happening right now in production systems that rank purely by similarity.
The pattern shows up everywhere:
- Travel agents recommending sold-out hotels with terrible margins
- Food delivery apps surfacing restaurants 45 minutes away (users want 15 min max)
- B2B marketplaces promoting out-of-stock inventory
- E-commerce sites ranking by relevance while ignoring return rates
The root cause? These agents optimize for one objective: semantic similarity. They ignore the 5-10 other factors that actually drive business outcomes.
The Traditional Multi-Stage Pipeline
To fix this, most teams build a complex application-layer pipeline:
Step 1: Candidate Retrieval
# candidate_retrieval.py
# Fetch 100 candidates from vector DB
results = pinecone.query(
vector=embed("wireless headphones under $100"),
top_k=100
)
candidate_ids = [r.id for r in results]Step 2: Metadata Enrichment
# metadata_enrichment.py
# Separate query to get business attributes
product_data = postgres.execute("""
SELECT id, profit_margin, stock_count, return_rate, price
FROM products
WHERE id IN (?, ?, ...)
""", candidate_ids)Step 3: The “Math Problem”
# custom_scoring.py
# How do you combine these disparate values?
def custom_score(item):
# Cosine similarity (0-1) + Profit margin ($0-$50) + Return rate (0-40%)?
semantic_score = item.similarity # 0.85
margin = item.profit_margin # $12.50
return_rate = item.return_rate # 15%
# ??? This is the problem
return 0.6 * semantic_score + 0.3 * (margin / 50) - 0.1 * (return_rate / 40)Step 4: Re-rank and Pray
# rerank.py
# Sort by custom score
ranked = sorted(candidates, key=custom_score, reverse=True)
# Pass top 5 to LLM
context = ranked[:5]The Reality Check
Problems with this approach:
| Issue | Impact |
|---|---|
| Multiple network hops | 200-400ms latency (fetch vectors → query DB → app logic) |
| Manual normalization | You’re guessing at how to combine $12.50 with 0.85 similarity |
| Brittle | Changing weights requires code deployment |
| Not real-time | Can’t adapt as catalog/prices change |
| Doesn’t scale | Falls apart with 100K+ items or real-time inventory |
Alternative: Value Models in the Retrieval Layer
Instead of managing scoring logic in application code, declare it as a value model expression in your query. The retrieval database handles normalization, multi-objective ranking, and real-time updates.
Architecture Comparison
(similarity)
(attributes)
(scoring math)
• Similarity
• Attributes
• Value Model Scoring
Implementation Guide: Multi-Objective Restaurant Agent
Let’s build a restaurant recommendation agent that balances:
- Relevance: Semantic match to user query
- User Affinity: Personalized taste from behavioral history
- Profitability: Restaurant profit margin
- Quality: Extracted “gourmet score” from reviews
Step 1: Connect Your Data Sources
Define your data tables using YAML schemas:
# restaurant_catalog_schema.yaml
name: restaurant_catalog
schema_type: POSTGRES
connection_config:
host: db.gourmet-market.com
database: production
table: menu_items# user_orders_schema.yaml
name: user_orders
schema_type: CUSTOM
column_schema:
user_id: String
item_id: String
created_at: DateTime
label: Int32 # 1 for order completed, 0 for abandonedCreate tables via CLI:
# terminal
$ shaped create-table --file restaurant_catalog_schema.yaml
$ shaped create-table --file user_orders_schema.yamlStep 2: AI Enrichment (Extract Business Signals)
Sometimes objectives aren’t explicit columns—they’re buried in unstructured text. Use AI Views to materialize a “gourmet score” from customer reviews:
# gourmet_score_view.yaml
name: enriched_restaurants
view_type: AI
source_table: restaurant_catalog
prompt: |
Analyze the customer reviews for this restaurant.
On a scale of 0-1, how "authentic" or "gourmet" is this establishment?
Return only a decimal number (e.g., 0.85).
output_columns:
- name: item_id
type: String
- name: gourmet_score
type: Float64Create the view:
# terminal
$ shaped create-view --file gourmet_score_view.yamlStep 3: Define the Engine
Configure an engine that:
- Indexes semantic embeddings for text search
- Trains a collaborative filtering model on user orders
- Makes both available for value model expressions
# restaurant_engine.yaml
name: gourmet_agent_engine
data:
item_table:
name: enriched_restaurants
type: table
user_table:
name: users
type: table
interaction_table:
name: user_orders
type: table
index:
embeddings:
- name: dish_embeddings
encoder:
type: hugging_face
model_name: sentence-transformers/all-MiniLM-L6-v2
source_column: description
training:
models:
- name: taste_model
policy_type: elsa # Collaborative filteringDeploy the engine:
# terminal
$ shaped create-engine --file restaurant_engine.yaml
$ shaped list-enginesWait for status ACTIVE
Step 4: Multi-Objective Queries with Value Models
Now query using ShapedQL with a value model expression that balances all objectives:
# multi_objective_query.sql
-- Multi-objective restaurant ranking
SELECT
item_id,
name,
cuisine,
price_tier
FROM text_search(
mode = 'vector',
text_embedding_ref = 'dish_embeddings',
input_text_query = $query,
limit = 100
)
WHERE
-- Hard business constraints
stock_status = 'AVAILABLE'
AND price_tier <= $max_price_tier
ORDER BY score(
-- Value model: blend behavioral, business, quality
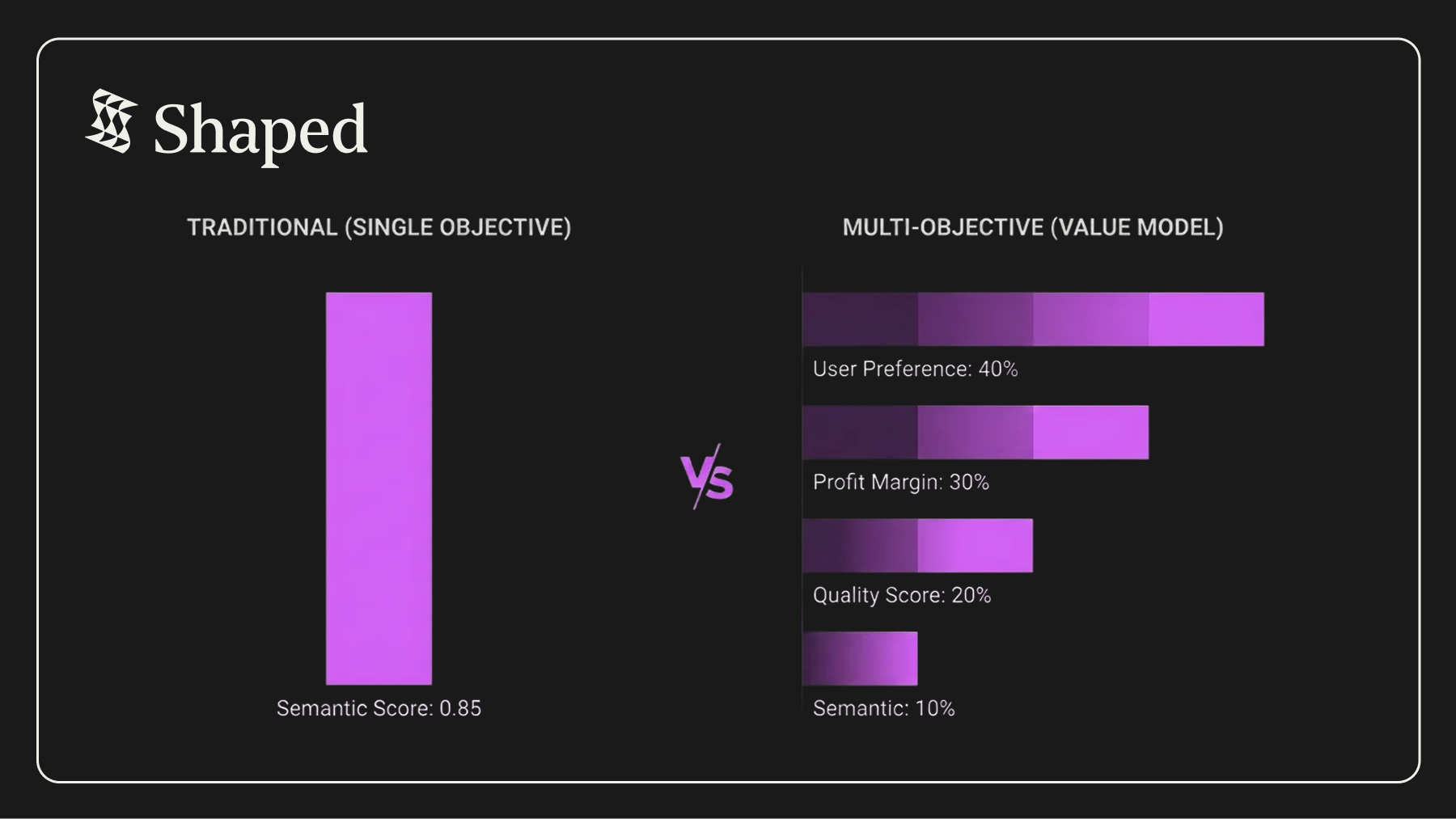
expression = '0.4 * taste_model + 0.3 * item.margin + 0.2 * item.gourmet_score + 0.1 * retrieval.score',
input_user_id = $user_id
)
LIMIT 5What this expression does:
- 0.4 * taste_model: 40% weight on learned user preference from order history
- 0.3 * item.margin: 30% weight on profit margin (business objective)
- 0.2 * item.gourmet_score: 20% weight on quality from AI enrichment
- 0.1 * retrieval.score: 10% weight on semantic relevance to query
Execute via CLI:
# terminal
$ shaped query \
--engine-name gourmet_agent_engine \
--query "SELECT * FROM text_search(mode='vector', text_embedding_ref='dish_embeddings', input_text_query=\$query, limit=100) WHERE stock_status='AVAILABLE' ORDER BY score(expression='0.4 * taste_model + 0.3 * item.margin + 0.2 * item.gourmet_score + 0.1 * retrieval.score', input_user_id=\$user_id) LIMIT 5" \
--parameters '{"query": "spicy handmade pasta", "user_id": "user_123"}'Or via REST API:
# terminal
$ curl https://api.shaped.ai/v2/engines/gourmet_agent_engine/query \
-X POST \
-H "x-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"query": "SELECT * FROM text_search(...) WHERE ... ORDER BY score(...) LIMIT 5",
"parameters": {"query": "spicy handmade pasta", "user_id": "user_123"}
}'Step 5: Integration with Your Agent
Pipe the multi-objective ranked results into your agent logic:
# agent-integration.ts
// TypeScript integration example
async function getRestaurantRecommendations(
userQuery: string,
userId: string
) {
const response = await fetch(
'https://api.shaped.ai/v2/engines/gourmet_agent_engine/query',
{
method: 'POST',
headers: {
'Content-Type': 'application/json',
'x-api-key': process.env.SHAPED_API_KEY!
},
body: JSON.stringify({
query: `SELECT * FROM text_search(...) ...`,
parameters: { query: userQuery, user_id: userId },
return_metadata: true
})
}
);
const data = await response.json();
return data.results;
}
// Use in your agent tool
const recommendations = await getRestaurantRecommendations(
"spicy handmade pasta",
"user_123"
);
// Pass to LLM with guaranteed business constraints
const completion = await anthropic.messages.create({
model: "claude-sonnet-4-5-20250929",
messages: [{
role: "user",
content: `Based on these recommendations: ${JSON.stringify(recommendations)} ...`
}]
});Unpopular Opinion: Semantic Search is Overrated in Production
The ML community obsesses over embedding models. BERT vs BGE vs E5. Fine-tuning vs zero-shot. Cosine vs dot product similarity. Entire papers written about 2% improvements in retrieval metrics.
Meanwhile, in production systems that drive actual revenue: semantic similarity matters ~10-20% of the time.
The other 80%? Business logic nobody talks about at ML conferences:
- Stock status (is this even available?)
- Profit margins (will this make or lose money?)
- Return rates (support nightmare indicator)
- User purchase history (already bought this)
- Geographic constraints (45-min delivery radius)
- Supplier relationships (prioritize partners)
- Seasonal inventory pressure (clear old stock)
Here’s the uncomfortable truth: You can have the world’s best embeddings—perfectly fine-tuned on your domain, optimized retrieval, reranked with cross-encoders—and still lose money if your agent recommends out-of-stock items with 2% margins to users who already own them.
The Semantic-Only Trap
This happens because:
- Academic benchmarks don’t measure business outcomes. NDCG@10 and MRR tell you nothing about profit, conversion, or retention.
- Rerankers are trained on linguistic datasets (MS MARCO, Natural Questions), not commercial datasets (clicks, purchases, returns).
- Embeddings capture “aboutness,” not “goodness.” A product description can be semantically perfect while the product itself is garbage.
Value models let you encode this reality. They’re not sexy. They won’t get you published at NeurIPS. But they’ll keep your business running while your competitors obsess over decimal points in cosine similarity.
When Semantic Search IS The Right Tool
To be clear: semantic search is phenomenal for:
- ✅ Knowledge bases / documentation
- ✅ Research paper retrieval
- ✅ Content discovery without commercial constraints
- ✅ Cold-start (no behavioral data yet)
But for revenue-driving recommendations? Semantic similarity is one input among many, not the optimization target.
Advanced: Dynamic Weight Tuning
The power of value models: change business priorities without redeploying code.
Scenario 1: “Margin Week” Promotion
# margin_week.sql
-- Temporarily boost margin importance
ORDER BY score(
expression = '0.3 * taste_model + 0.5 * item.margin + 0.1 * item.gourmet_score + 0.1 * retrieval.score',
input_user_id = $user_id
)Scenario 2: New User (No Behavioral History)
# new_user_fallback.sql
-- Fall back to quality + semantic relevance
ORDER BY score(
expression = '0.6 * item.gourmet_score + 0.4 * retrieval.score',
input_user_id = $user_id
)Scenario 3: Clearance Mode
# clearance_mode.sql
-- Prioritize low-stock, high-margin items
ORDER BY score(
expression = '0.5 * item.margin + 0.3 * (1.0 / (item.stock_count + 1)) + 0.2 * taste_model',
input_user_id = $user_id
)Update these expressions in real-time via the Shaped Console or API—no code deployment required.
Common Value Model Patterns
Pattern 1: Ensemble Multiple Models
# ensemble_models.sql
-- Blend click prediction with conversion prediction
ORDER BY score(
expression = '0.7 * click_through_rate + 0.3 * conversion_rate',
input_user_id = $user_id
)Pattern 2: Boost Fresh Content
# boost_fresh_content.sql
-- Time decay: prefer recently published items
ORDER BY score(
expression = 'taste_model * exp(-0.0001 * (now_seconds() - item.published_at))',
input_user_id = $user_id
)Pattern 3: Location-Based Ranking
# location_ranking.sql
-- Penalize distance, reward local businesses
ORDER BY score(
expression = 'taste_model - 0.1 * distance(user.location, item.location)',
input_user_id = $user_id
)Pattern 4: Diversity-Aware Scoring
# diversity_scoring.sql
-- Combine with REORDER for category diversity
ORDER BY score(
expression = '0.6 * taste_model + 0.4 * item.margin'
)
REORDER BY diversity(diversity_lookback_window=50)Performance Benchmarks
Based on production deployments optimizing for 2-3 objectives:
| Metric | Application-Layer Ranking | Value Model (Shaped) |
|---|---|---|
| Query Latency | 250-500ms (3-4 network hops) | 50-100ms (single query) |
| Ranking Accuracy | Manual tuning, hard to optimize | ML-optimized, A/B testable |
| Weight Updates | Code deployment (hours) | Console update (seconds) |
| Real-Time Adaptation | Batch updates (minutes-hours) | Streaming updates (<30s) |
| Complexity | 150+ lines of scoring logic | 1 SQL expression |
When Do You Need Multi-Objective Ranking?
Use Multi-Objective Value Models When:
- ✅ You’re building a marketplace (need to balance user preference with business metrics)
- ✅ You have real-time inventory or pricing
- ✅ Recommendations impact revenue (e-commerce, travel, food delivery)
- ✅ Multiple stakeholders care about ranking (users, suppliers, business)
- ✅ You need A/B test different objective weights
Stick with Simple Semantic Search When:
- ✅ Pure knowledge retrieval (docs, FAQs, support articles)
- ✅ No commercial constraints (open research, education)
- ✅ Static catalog with no business metrics
- ✅ Prototype/MVP stage
Common Pitfalls
- Over-weighting semantic similarity: In production, retrieval.score often needs just 10-20% weight. User behavior and business metrics matter more.
- Forgetting normalization: If one feature ranges 0-1 and another 0-1000, the expression will be dominated by the larger range. Use Shaped’s built-in normalization or manually scale.
- Ignoring cold-start: New users have no taste_model score. Always include a fallback like item.gourmet_score or retrieval.score.
- Not A/B testing weights: Different weight combinations drive different business outcomes. Test 0.6 * taste + 0.4 * margin vs 0.4 * taste + 0.6 * margin.
- Static expressions in dynamic markets: Update your value model expressions as business priorities shift (holidays, clearance, new supplier partnerships).
FAQ: Multi-Objective Agents
Q: Can I use value models without training a behavioral model? A: Yes! You can use expressions with just item attributes and retrieval scores: ORDER BY score(expression=‘0.7 * item.margin + 0.3 * retrieval.score’). Behavioral models like taste_model are optional.
Q: How do I know what weights to use? A: Start with business intuition (e.g., 50% user preference, 30% margin, 20% quality), then A/B test. Measure business metrics (revenue, conversion) not just ranking metrics (NDCG, precision).
Q: Can I reference item attributes from joined tables? A: Yes, as long as the data is in your item_table or accessible via views. Use SQL views to join data before it reaches the engine.
Q: What if my objectives conflict (high quality = low margin)? A: That’s the point of multi-objective optimization! The value model finds the pareto-optimal trade-off based on your weights. Adjust weights to reflect business priorities.
Q: Does this work for text search and recommendations? A: Yes, value models work with any retriever: text_search(), similarity(), column_order(). The scoring stage is universal.
Real-World Use Cases
E-Commerce: “Amazon-style” Ranking
# ecommerce_ranking.sql
-- Balance user preference, conversion likelihood, and profit margin
ORDER BY score(
expression = '0.4 * predicted_ctr + 0.3 * conversion_rate + 0.3 * item.margin',
input_user_id = $user_id
)Travel: Inventory-Aware Recommendations
# travel_ranking.sql
-- Promote available, profitable hotels near user's location
ORDER BY score(
expression = '0.5 * taste_model + 0.3 * item.margin + 0.2 * (1.0 / (distance + 1))',
input_user_id = $user_id
)
WHERE availability = trueContent Platforms: Engagement + Freshness
# content_ranking.sql
-- Boost recent content with high predicted engagement
ORDER BY score(
expression = '0.6 * predicted_watch_time + 0.4 * exp(-0.0001 * (now_seconds() - item.published_at))',
input_user_id = $user_id
)Next Steps
- Audit your current ranking logic: Map out where you’re currently handling multi-objective scoring (probably scattered across application code)
- Identify your objectives: List all the factors that should influence ranking (user preference, business metrics, constraints)
- Instrument your data: Ensure item attributes are available in your retrieval database
- Start simple: Begin with a 2-objective value model, then add complexity
- A/B test everything: Different weight combinations drive different outcomes—measure what matters
Next Steps: Build Your First Multi-Objective Agent
Quick Start Path (< 30 minutes)
If you want to experiment today:
- ⬇️ Clone the starter patterns from this article
- Copy the YAML schemas (tables, views, engine)
- Copy the ShapedQL query with value model expression
- Adapt to your domain (replace restaurants with products/content/hotels)
📊 Run a benchmark - Compare approaches:
# benchmark.py
# Semantic-only baseline
results_semantic = query(order_by="retrieval.score")
# Multi-objective
results_multi = query(
order_by="0.4 * model + 0.3 * margin + 0.3 * retrieval.score"
)
# Measure: Which drives more clicks? More revenue?Measure: Which drives more clicks? More revenue?
- 🎛️ Tune weights interactively
- Start with equal weights: 0.33 * model + 0.33 * margin + 0.34 * score
- Shift 10% at a time based on business priority
- Watch metrics (conversion, revenue per user, margin)
- 🚀 A/B test in production
- 80% traffic on semantic-only (control)
- 20% traffic on multi-objective (test)
- Run for 1 week, measure business KPIs
Production Deployment Checklist
Before you ship multi-objective ranking to 100% of users:
Data Preparation:
□ Audit current ranking logic (where does scoring happen now?)
□ Identify all objectives that should influence ranking
□ Verify item attributes are accessible in retrieval layer
□ Set up real-time data pipeline (if using streaming events)
□ Define fallback behavior (cold-start, missing attributes)
Model Training:
□ Collect interaction data (clicks, purchases, time-on-page)
□ Train behavioral model (if using collaborative filtering)
□ Validate model metrics (precision@k, NDCG, coverage)
□ Test cold-start scenarios (new users, new items)
Value Model Tuning:
□ Define initial weights based on business priorities
□ Run offline evaluation on historical data
□ A/B test multiple weight configurations
□ Monitor ranking distribution (are results too homogeneous?)
□ Set up alerts (sudden drops in diversity, coverage)
Business Guardrails:
□ Hard constraints in WHERE clause (stock, price, location)
□ Exclusion rules (duplicate prevention, user-specific filters)
□ Compliance checks (region restrictions, age gates)
□ Rate limiting (prevent gaming the system)
Monitoring & Iteration:
□ Track business metrics (conversion, revenue, margin)
□ Monitor ranking quality (diversity, coverage, personalization)
□ Log value model scores for debugging
□ Set up dashboards for weight impact analysis
□ Plan quarterly weight reviews (business priorities shift)
Common First-Week Questions
Q: Our behavioral model isn’t trained yet. Can we still use value models? A: Yes! Start with item attributes only: ORDER BY score(expression=‘0.6 * item.margin + 0.4 * retrieval.score’). Add behavioral models later.
Q: How do we choose initial weights? A: Ask your PM: “If you had to rank 100 items manually, what would you prioritize?” Convert their answer to weights. Then test.
Q: What if objectives conflict (high quality = low margin)? A: That’s the point! The value model finds the optimal tradeoff. Your weights encode how you resolve conflicts.
Q: Can we update weights without retraining models? A: Yes—that’s the whole benefit. Change the expression, instant update. No retraining, no redeployment.
Getting Help
- Shaped Documentation:docs.shaped.ai
- Free Trial:$300 credits, no credit card
- Community: Shaped slack community (link in docs)
- Book a demo
Conclusion: From Semantic Search to Business-Aware Retrieval
The future of AI agents isn’t just better embeddings or smarter LLMs—it’s ranking systems that understand your business.
By moving multi-objective logic from fragile application code into declarative value model expressions, you build agents that:
- Adapt in real-time to inventory and pricing changes
- Respect hard business constraints (stock, location, compliance)
- Balance competing objectives mathematically (not heuristically)
- Update ranking priorities without code deployment
- Scale to millions of items with <100ms latency
Stop building agents that only understand words. Build agents that optimize for outcomes.
Want to try Shaped with your own data?Sign up for a free trial with $300 credits here.
Additional Resources:
- Shaped Value Model Expression Reference
- Multi-Stage Ranking Architecture (Shaped Blog)
- ShapedQL Complete Reference
- Production Ranking Systems (Google Research)
About This Guide: This article reflects production patterns observed across e-commerce, travel, and marketplace platforms implementing multi-objective ranking systems in 2026. Code examples are verified against Shaped’s documentation and represent current best practices.
Want us to walk you through it?
Book a 30-min session with an engineer who can apply this to your specific stack.