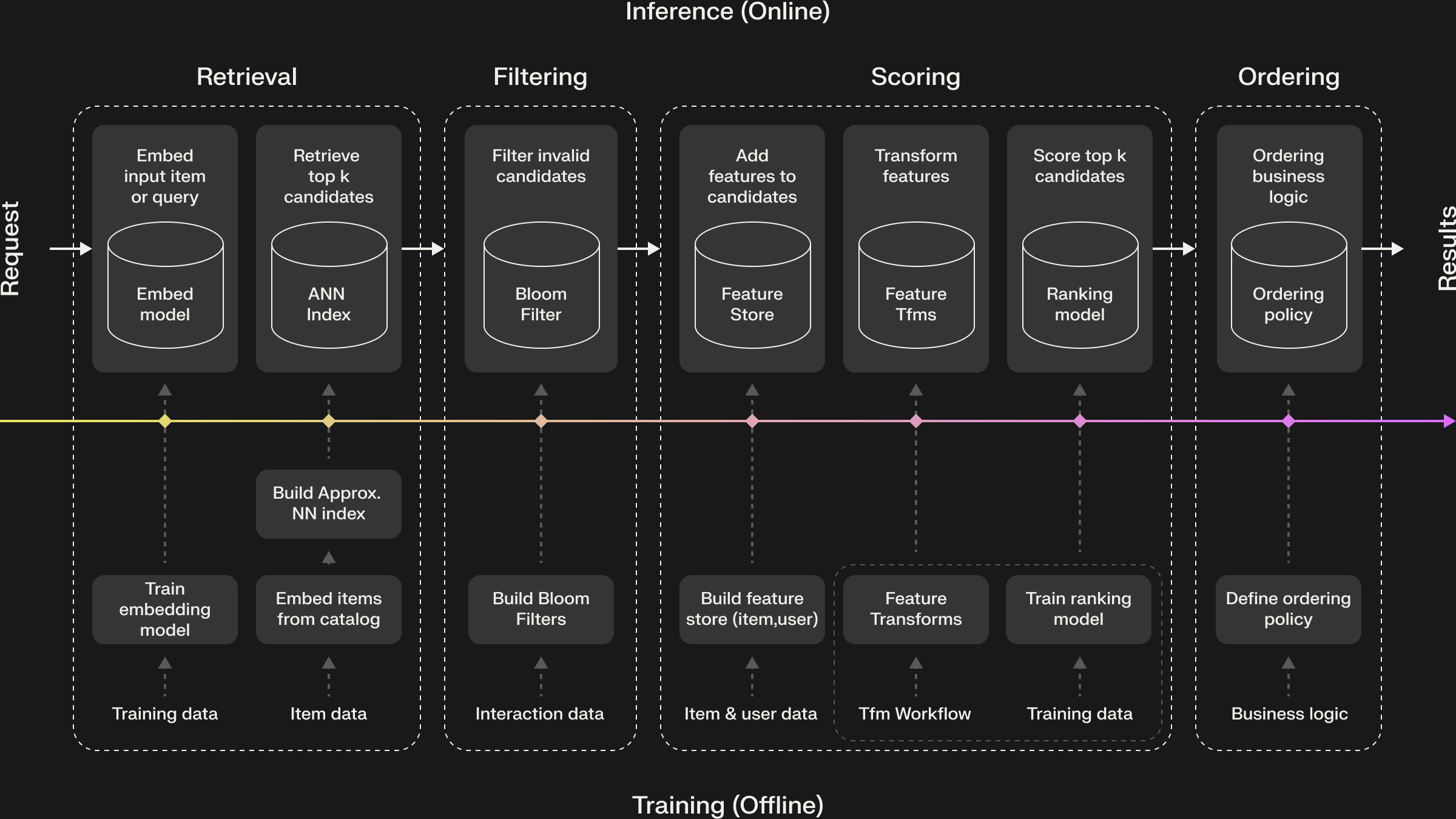
A Brief History of a Convergent Design
This multi-stage architecture is not new. It’s a powerful design pattern that has evolved over the last decade as item corpora grew from thousands to billions, and user expectations for latency shrank to almost zero. The core ideas have been refined and shared by engineering teams across the industry.
Much of the public understanding of this framework was shaped by a few seminal blog posts and papers that are still worth reading today:
- Eugene Yan’s System Design for Discovery provided one of the clearest early overviews of the multi-stage funnel for a broad technical audience.
- NVIDIA’s Recommender Systems, Not Just Recommender Models articulated the distinction between the model and the full system, emphasizing the engineering scaffolding required.
- The YouTube Recommendation Paper (2016) was one of the first deep dives into a production two-stage system, separating candidate generation (retrieval) from ranking.
More recently, this thinking has continued to evolve. Experts like the author of the Amatria blog, drawing on deep experience from Netflix, have pushed the community to move beyond the rigid funnel analogy. The Recsys Architectures post reframes the system as a more flexible set of interacting components, which aligns much more closely with the reality of modern production systems. Our series will adopt this more nuanced, component-based view.
 RecSys architectural blueprint from Amatria from 2023.
RecSys architectural blueprint from Amatria from 2023.
The “Perfect Scorer” Thought Experiment: Why This Architecture is Necessary
To understand why this blueprint is ubiquitous, it’s useful to start with a thought experiment.
Imagine you had a perfect function, perfect_score(user, item, context). This function is the oracle; it computes a multi-objective score that perfectly blends relevance, predicted user engagement, long-term user delight, business value, and alignment with platform goals.
If you could run this function on every item in your catalog for every user request, your job would be done. You would simply sort(by=‘perfect_score’, descending=True) and return the top results.
The problem is, this function would be infinitely complex and computationally expensive. Running it across a million-item catalog would take days. Our P99 latency target is 200 milliseconds. The entire architecture of a modern recommender system is an exercise in approximating the output of this perfect, impossible function within our latency and cost budgets.
The Core Engineering Trade-off
This brings us to the fundamental engineering challenge: a constant balancing act between three competing forces.
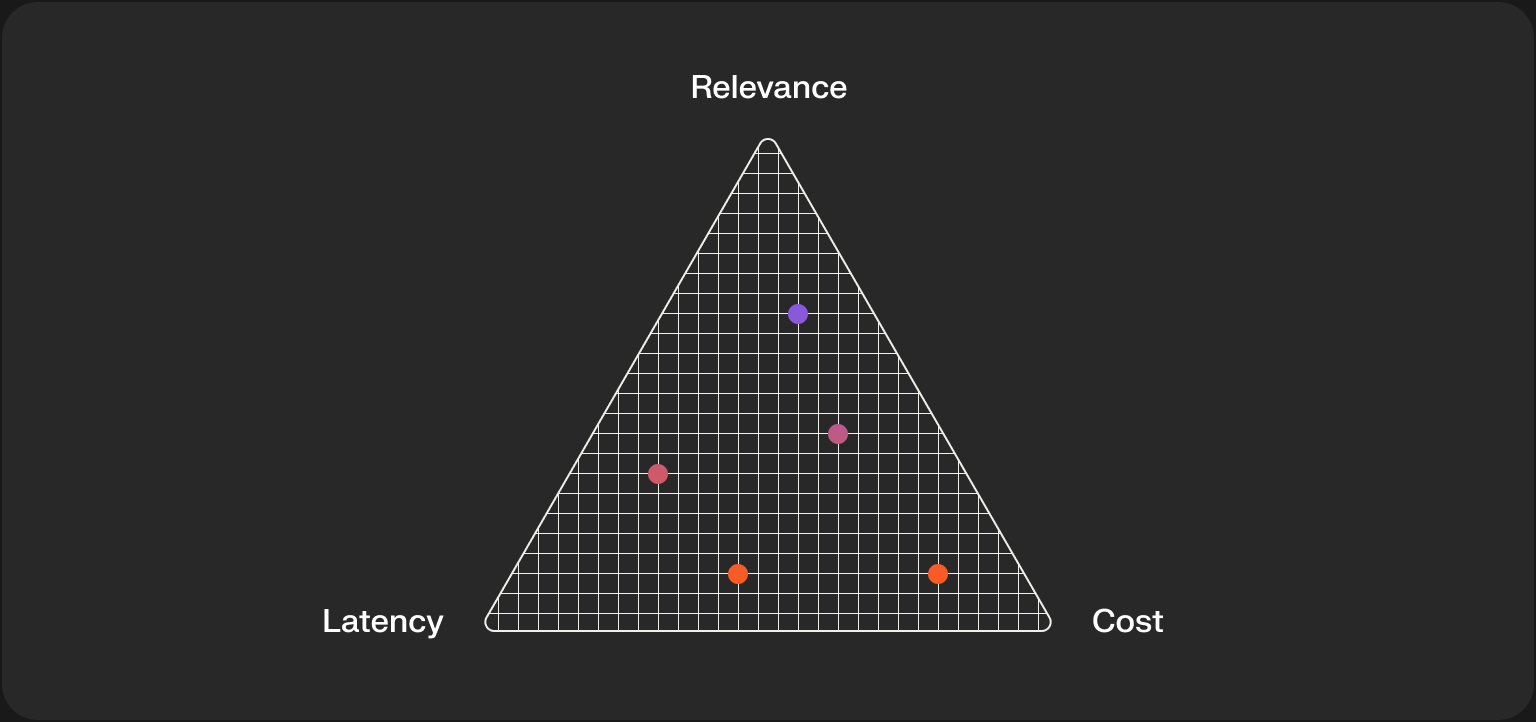
You cannot maximize all three. Pushing for maximum relevance with a huge, complex model will inevitably increase latency and cost. Aggressively optimizing for low latency with a simple model will harm relevance. The multi-stage architecture is a system designed to find an optimal point within this triangle, applying the right amount of computational power at the right stage.
Production Reality: A Linearization of a DAG
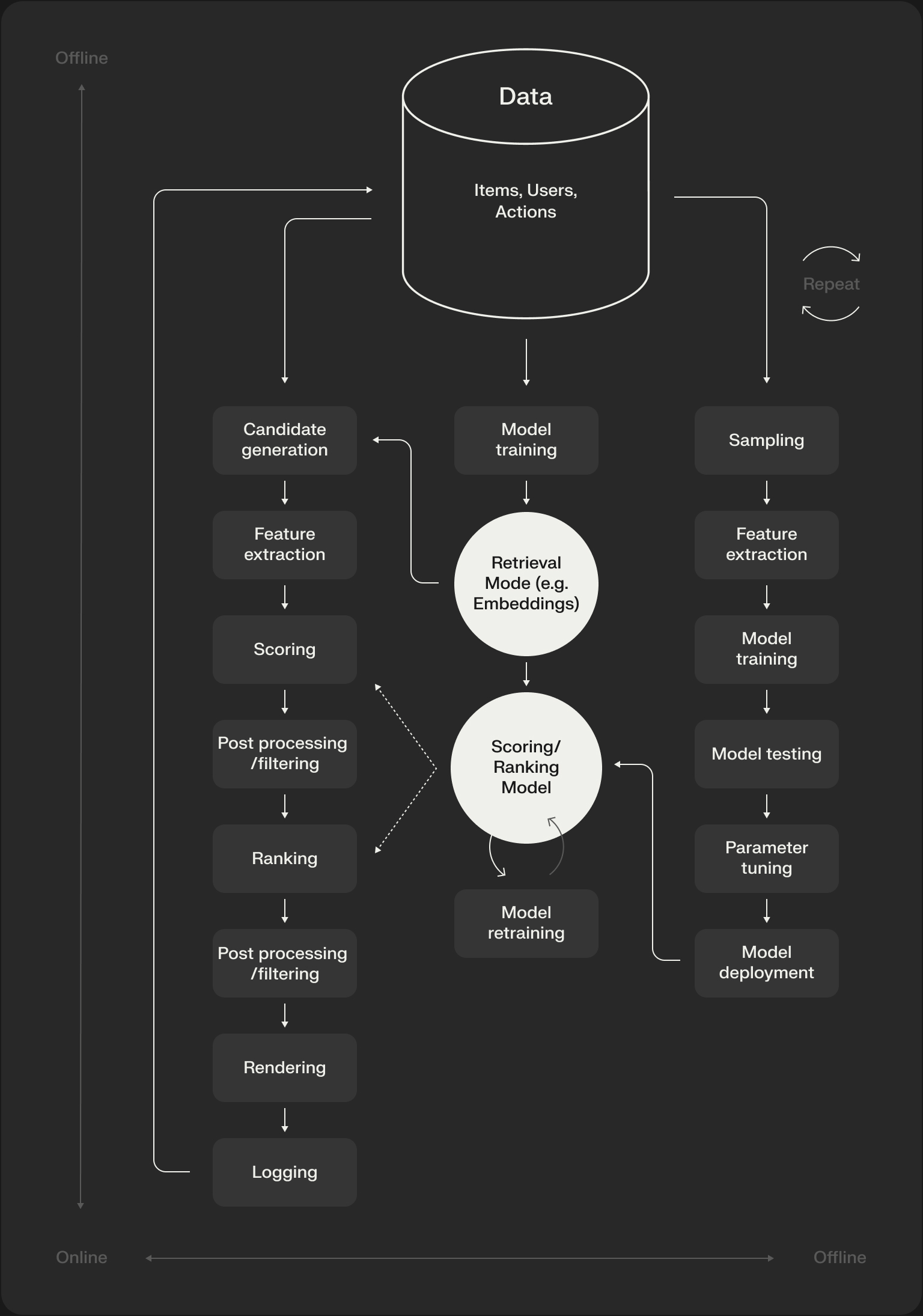
The linear “funnel” model—Retrieval -> Filtering -> Scoring -> Ordering—is a useful teaching tool, but it’s a simplification. Production systems are rarely a simple, linear pipe. They are better described as a Directed Acyclic Graph (DAG) of components.
In a real system:
- Multiple candidate sources run in parallel. A vector search for semantic similarity might run alongside a collaborative filtering model for related items and a heuristic for “new and trending” content.
- Specialized rankers might operate on different candidate sets. A dedicated cold-start model might score new items, while a separate model scores ads, each using different features and objectives.
- Filtering logic is applied at multiple points: before retrieval to constrain the search space, and after scoring to enforce business rules.
The funnel we often talk about is simply a linearization of the most common path through this more complex DAG for a single request. Understanding this distinction is key to building and debugging real-world systems. As you can see, assembling, orchestrating, and maintaining this complex DAG of components is a significant, undifferentiated engineering effort. Getting it right is the difference between a system that scales and one that collapses under its own complexity.
.jpg)
Common Architectural Traps
Building this architecture in practice reveals several common pitfalls. Avoiding these is often more important than choosing the perfect model.
- The “Hero Retriever” Anti-Pattern: A common mistake is to put all effort into a single, powerful retriever, usually vector search. While essential, relying on one source creates blind spots. A vector model is bad at discovering new, popular items (the “cold-start problem”) and can easily get stuck in feedback loops. Production systems are always ensembles, blending semantic search with collaborative filtering and simple “most popular” heuristics for robustness.
- Treating Filtering as an Afterthought: Another trap is applying all your filters at the very end. The most expensive operation in retrieval is the candidate generation itself. By applying hard constraints before retrieval (e.g., filtering for ‘in-stock’ products or ‘restaurants open now’), you can shrink the search space by orders of magnitude, drastically reducing cost and latency. Filtering isn’t a single step; it’s a continuous process.
- The Offline/Online Skew: The most insidious failures happen when the features available during offline training don’t perfectly match the features available at online inference time. This can lead to models that perform brilliantly in notebooks but fail silently in production. We’ll cover this in depth later, but the core architectural takeaway is that your feature pipelines must be designed with serving in mind from day one.
Our Roadmap: Deconstructing the System
To analyze this architecture, we will follow the logical flow of this linearized funnel. This series will dedicate a post to each of the key stages:
- The Retrieval Stage: This first stage is a multi-step process in itself. We will cover how to efficiently query multiple candidate sources, apply pre-filtering to reduce the search space, and use post-filtering to clean the candidate set before the next stage.
- The Scoring Stage: Here, we’ll take the ~1000 candidates from retrieval and use powerful but more expensive models to generate precise pointwise predictions. We will cover classic DLRM architectures and the modern shift toward Transformer-based sequential models.
- The Ordering Stage: This is the final, listwise step where we transform a list of scored items into a polished page. We will discuss blending candidates from different sources, enforcing diversity, and applying the final layer of business logic and page construction rules.
- The Feedback Loop: In the final post, we’ll cover the data and evaluation engine that powers the entire system—how user interactions are logged and processed to train the next generation of models, and how we measure success through offline and online testing.
Conclusion
The multi-stage ranking architecture isn’t just a “best practice”, it’s an elegant and necessary engineering solution to the fundamental trade-offs between relevance, latency, and cost. By breaking a seemingly intractable problem into a series of manageable approximations, it allows us to serve highly relevant recommendations at massive scale.
In our next post, we’ll get our hands dirty with The Retrieval Stage. We’ll move beyond the basics and look at how to build a production-ready ensemble of retrievers. I’ll share some Python code for a simple but powerful collaborative filtering model and discuss the practicalities of choosing and deploying an ANN index for vector search. We’ll cover the specific trade-offs between recall, latency, and cost that drive real-world design decisions.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.