
If you missed it, check out our favorite papers and talks from Day 1 of RecSys 2022hereand Day 2here.
You Say Factorization Machine, I Say Neural Network – It’s All in the Activation
Authors: Chen Almagor, Yedid Hoshen
Lab: The Hebrew University of Jerusalem
Link: https://dl.acm.org/doi/pdf/10.1145/3523227.3551499
Recommendation models like Wide & Deep, DeepFM have always had an inelegant feel to them as they’re essentially two architectures concatenated together to solve the problems of each other. This work proposes a more elegant formulation that combines these components into a unified architecture.
They introduce FiFa: Fieldwise factorized neural networks. The architecture can represent both modern factorization machines (FM) and ReLU neural networks (DNN) in a general form. Recovering FMs or DNNs then becomes a matter of modifying the activation functions. They then show that an activation function exists which can adaptively learn to select the optimal paradigm for each use case.
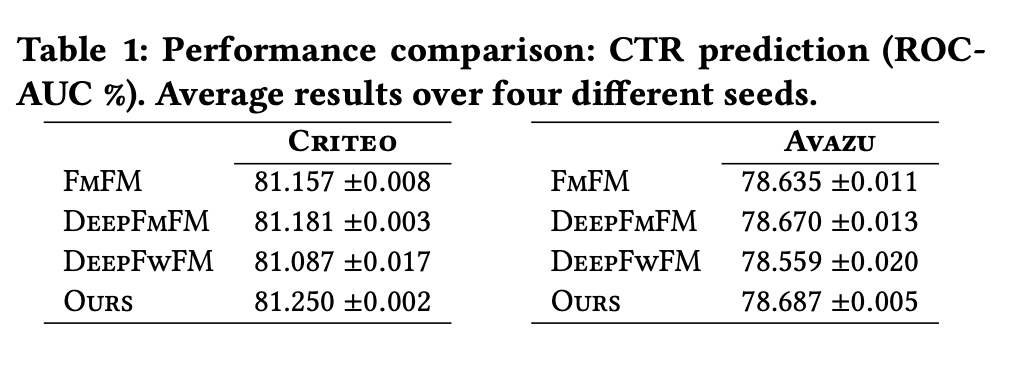
The results show that this improves both FM models, and DeepFM models on the Criteo and Avazu dataset.
Revisiting the Performance of iALS on Item Recommendation Benchmarks
Authors: Steffen Rendle, Li Zhang, Walid Krichene, Yehuda Koren
Link: https://doi.org/10.1145/3523227.3548486
Matrix factorization learned by implicit alternating least squares (iALS) is a popular baseline in recommender system research. It is known to be one of the most computationally efficient and scalable collaborative filtering methods. However, recent studies suggest that its prediction quality is not competitive with the current state-of-the-art, such as autoencoders and other item-based collaborative filtering methods. The authors revisit the well-studied benchmarks where iALS was reported to perform poorly and show that with proper tuning its performance is comparable with state-of-the-art methods.
Results for MovieLens 20M:
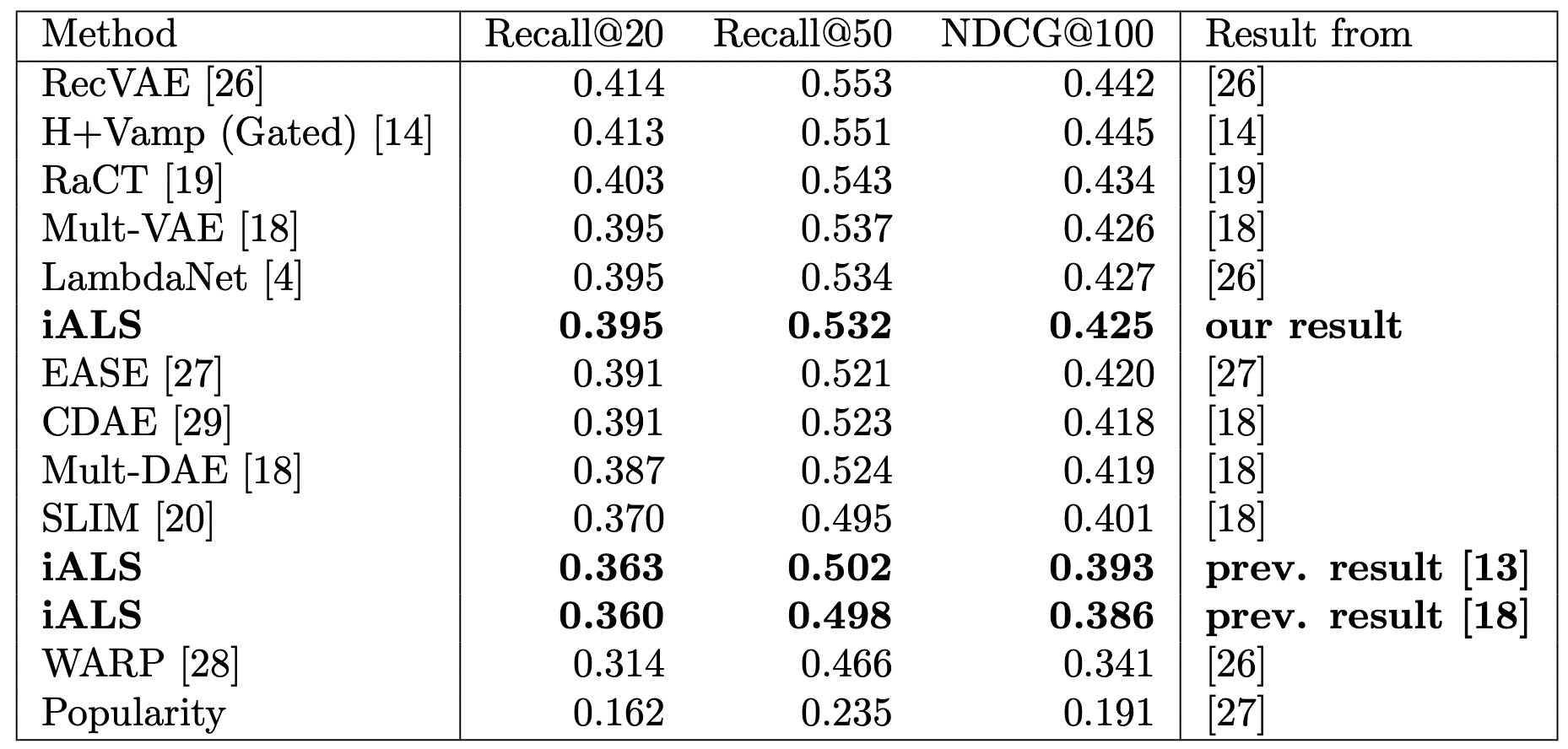
Million Song dataset:
The In order to achieve these results multiple iALS hyperparameters are tuned, they provide recommendations on what values to use:
- Num iterations: How many times it trains on the data, typically converged in 16-20 iterations.
- Embedding dimensions: Controls capacity of the model, if it’s too small it will negatively affect model performance. Training cost scales in d^3.
- Standard deviation: not too sensitive to this parameter, the typical value 1 / sqrt(embedding dimensions)
- Unobserved weight (weight of unobserved value) and regularization weight: Crucial, important to tune carefully, recommend to search on a logarithmic grid to determine the appropriate scale, then do a more refined search.
- Regularization regularization exponent: Reparameterization to decouple lambda and v, their optimal value was frequently 1.
Adversary or Friend? An adversarial Approach to Improving Recommender Systems
Authors: Pannaga Shivaswamy, Dario Garcia-Garcia
Lab: Netflix
Link: https://dl.acm.org/doi/pdf/10.1145/3523227.3546784
Typical recommender systems models are trained to have good average performance across all users or items. In practice, this results in model performance that is good for some users but sub-optimal for many users. This work investigates the use of adversarial models/objectives to solve this in-balance in performance.
They apply what’s called an adversarial reweighted learning (ARL) model to gives more emphasis to dense areas of the feature-space that incur high loss during training and such should correspond to the sub-optimal performing users.
They formulate an ARL loss as follows:
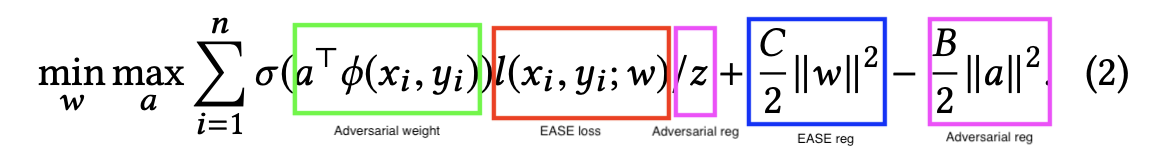
The intuition here is that the adversarial model output weight (green) will be higher when the adversary expects the training loss (red) to be higher. The adversarial model regularization (pink), is both the l2 loss (at the end of the equation) and a normalization of adversary weights such that they sum to one over all examples (the divider of the first term), are critical to ensure it’s possible for the objective to be learnable. Note, EASE is a state-of-the-art collaborative filtering model, and the EASE objective above just refers to the non regularization terms from the Lagrangian objective function.
To optimize this objective they first train SGD on the learner and adversary model jointly. They then go on to propose a rank-loss adversarial model (R-LARM) that better fits the ranking objective by taking the gradient directly on an NDCG loss.
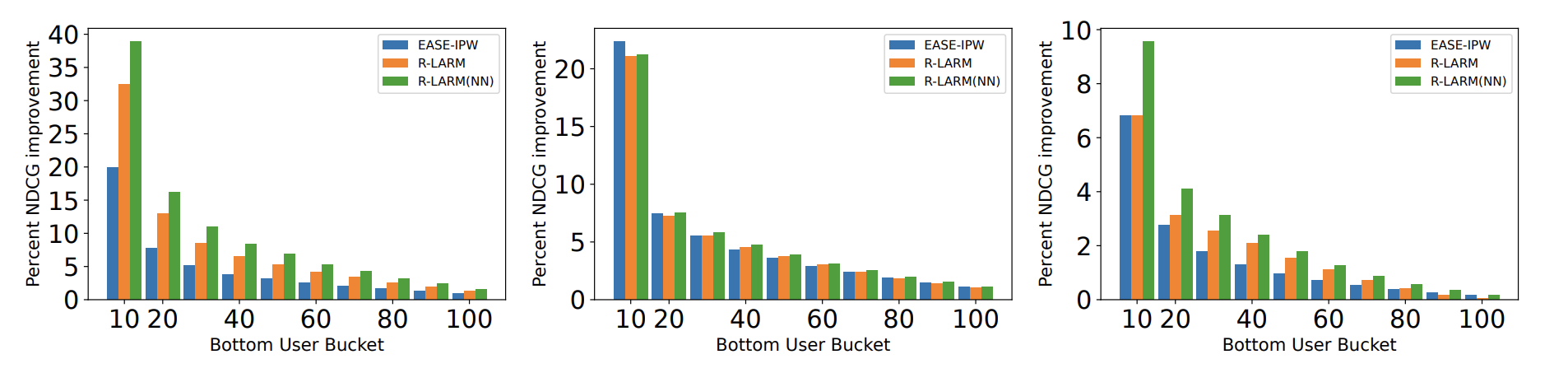
They experiment on the ML20M, Netflix and MSD datasets. The results demonstrate that not only is R-LARM best in aggregate but it also helps for every interaction percentile bucket of users.
Augmenting Netflix Search with In-Session Adapted Recommendations
Authors: Moumita Bhattacharya, Sudarshan Lamkhede
Lab: Netflix
Link: https://arxiv.org/pdf/2206.02254.pdf
Users at Netflix expect personalized feeds across different usage of the app. This work provide a comprehensive view of how multiple recommendation systems complement each other to build these personalized experience. It provides an overview of an end-to-end in-session adaptive recommendations system and discusses their findings when deploying it at scale.
Some of Netflix’s recommendation use-cases are:
- Homepage feed — Collection of different carousels and ranking systems
- Search — Fetch, find, explore across the Netflix catalog given a query
- Pre-query recommendations — Pre-query recommendations. e.g. pre-query: profile → title. They try to predict what the authors want.
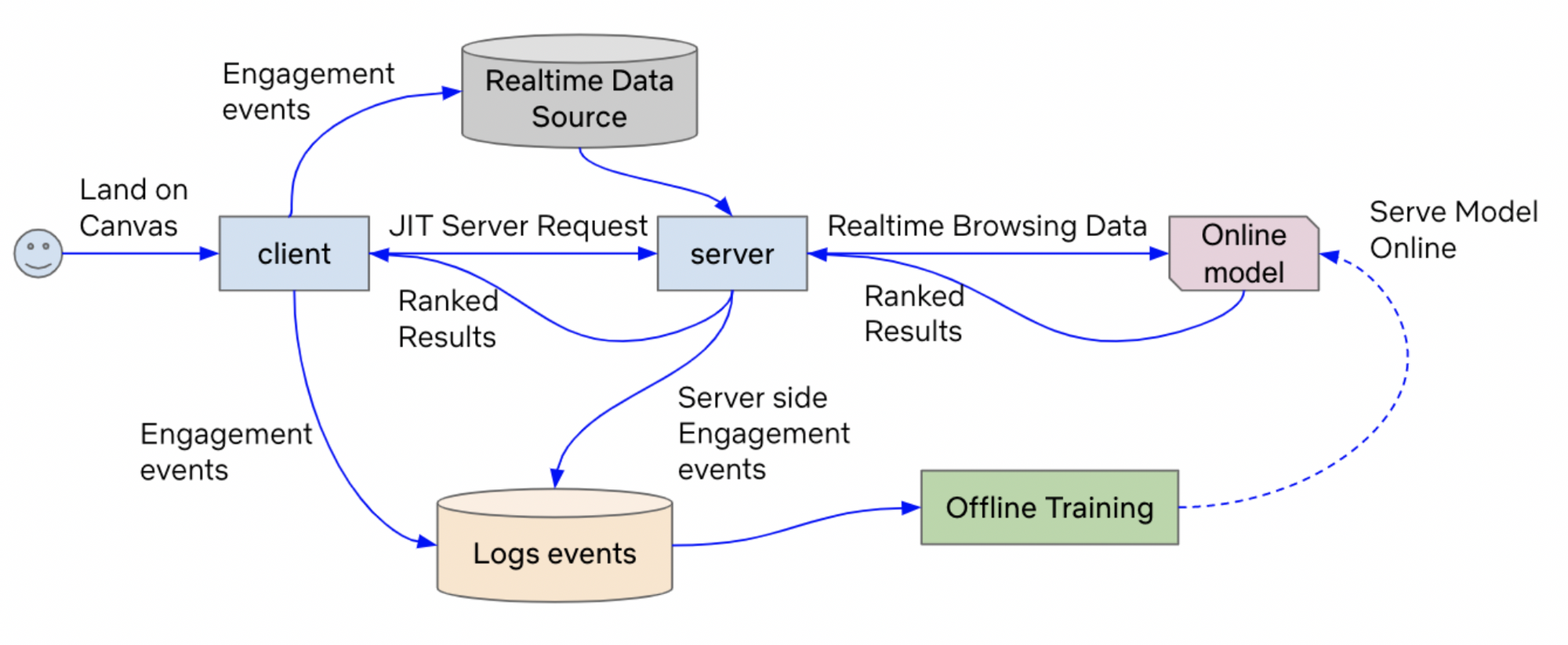
In the system they describe, they store long term preferences as past interactions and short term preferences as current session information. They combine both of these data sources before feeding them to their model.
They highlight the effects of using short term data (session data) as it helps produce fresher recommendations with higher diversity and novelty. It helps them find what the user currently wants even if the user has very few data points in their system, the current session is enough to produce recommendations. All of these benefits help increase overall member satisfaction and reduce the number of abandoned sessions.
An Incremental Learning framework for large-scale CTR prediction
Authors: Petros Katsileros, Nikiforos Mandilaras, Dimitrios Mallis, Vassilis Pitsikalis, Stavros Theodorakis, Gil Chamiel.
Lab: Deeplab, Taboola
Link: https://arxiv.org/pdf/2209.00458.pdf
Authors present an incremental learning framework for CTR prediction through the rapid deployment of fresh models. They achieved this by implementing a warm-start from past-deployed models with a teacher-student paradigm.
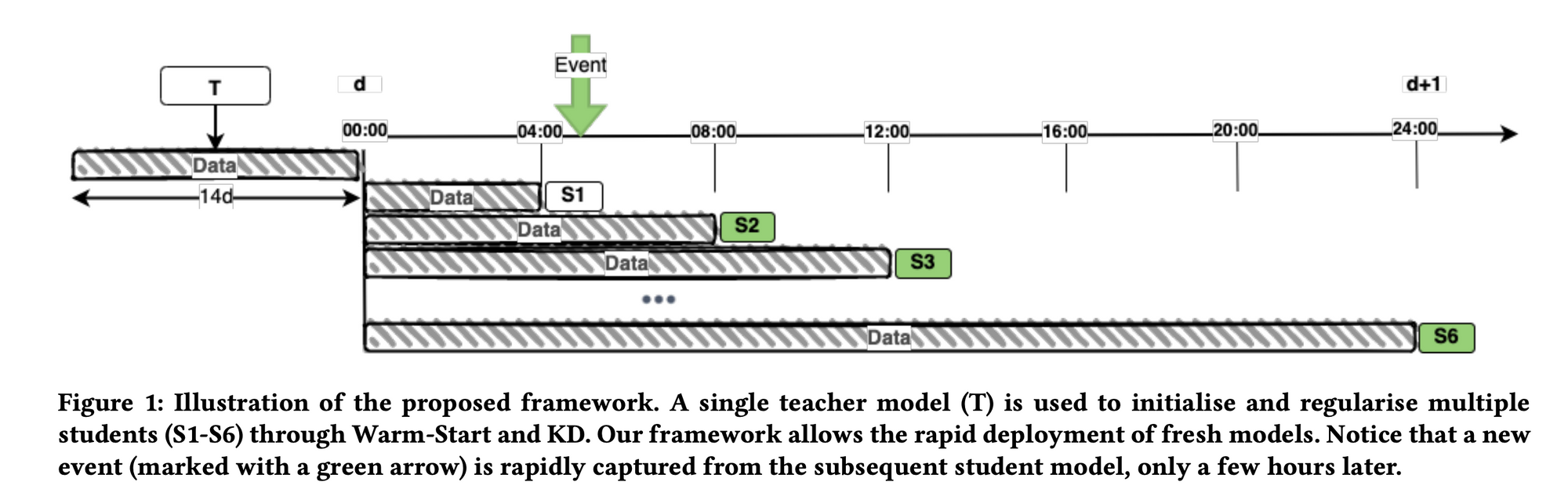
During training, a teacher-student paradigm, where the teacher (trained daily) acts as an implicit regularizer, enables the student to maintain previously acquired knowledge.
Previously training each model from scratch on historical user impressions resulted in long training times, model freshness issues as new trends emerged (that were not captured by historical data), and intensive computing resources.
Thanks for reading. If you found the summary helpful please like and retweet 🙏.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.