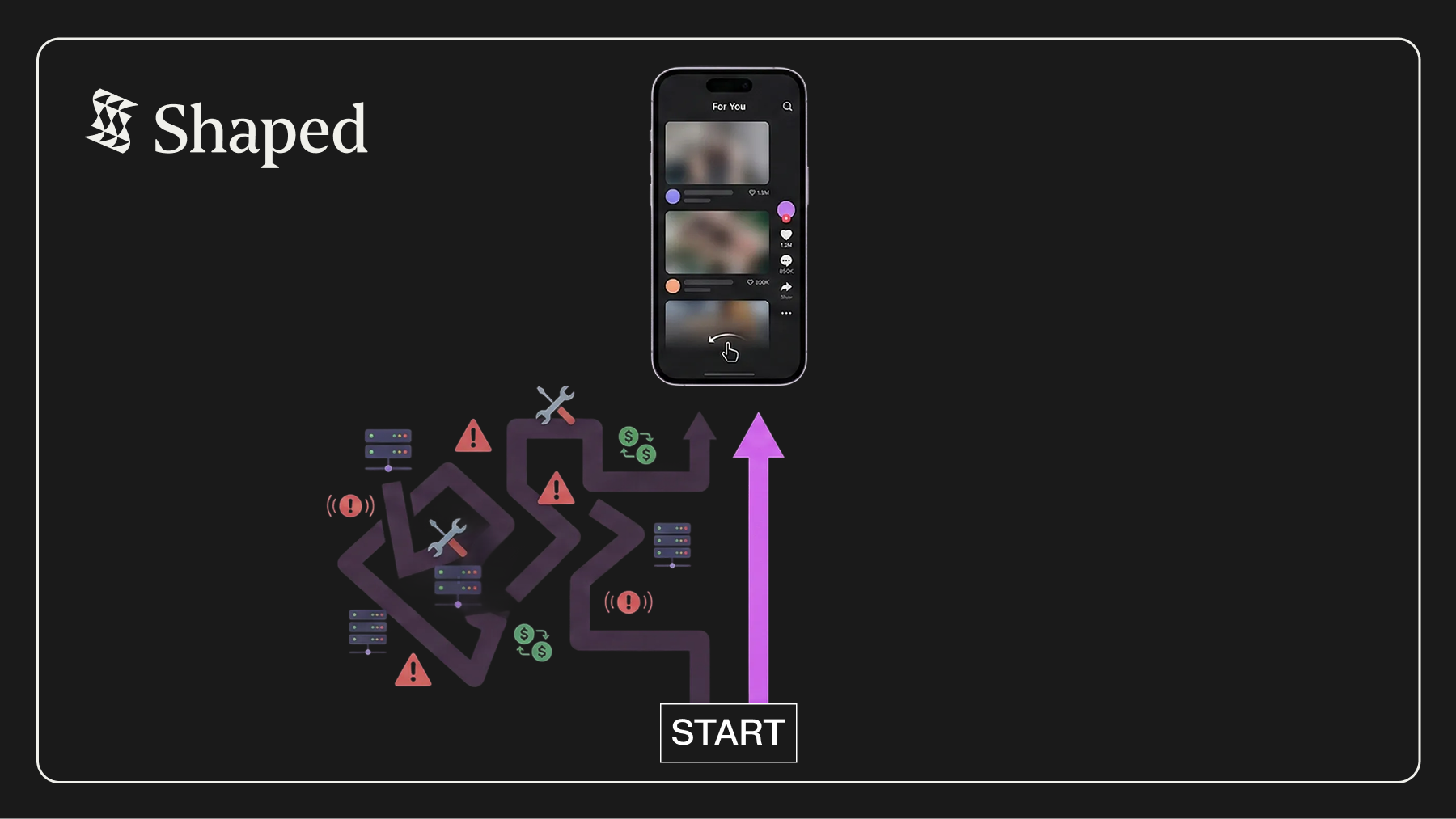
Building Sequential Recommendation Systems: The 6-Month DIY Detour
Here’s what actually happens when you decide to build TikTok-style sequential recommendations in-house:
Month 1: The Streaming Pipeline That Never Works
You set up Kafka for event streaming. Then you discover Kafka doesn’t do stateful aggregation, so you add Flink. Flink needs checkpointing, so you configure S3. Your first “video_view” event arrives. Flink crashes. You spend a week debugging state serialization errors.
Someone changes the event schema in the iOS app. Your pipeline breaks silently. You don’t notice for three days because monitoring wasn’t set up yet.
Month 2-3: The SASRec Training Saga
You find a SASRec implementation on GitHub. It’s in PyTorch 1.8. Your infrastructure is on 2.0. You spend two weeks porting it. Training starts. Your AWS bill jumps by $8,000 for GPU instances.
The model trains for 48 hours. Accuracy is terrible. You realize the hyperparameters were tuned for MovieLens, not your data. You start tuning. Each experiment takes 2 days. Your PM asks “when will it be ready?” You say “soon” for the fourth time.
The model finally works. Now you need to serve it.
Month 4: The Inference Infrastructure That’s Never Fast Enough
You deploy the model to a Flask endpoint. Latency: 2 seconds. Unacceptable. You switch to TorchServe. Better, but still 400ms. You add Redis for feature caching. Latency drops to 150ms—but now Redis is out of sync with Postgres and users see stale recommendations.
You need an ANN index for fast vector search. Faiss? HNSW? You spend a week benchmarking. You pick Faiss. Building the index takes 6 hours. Updating it in production without downtime? That’s a separate project.
You finally ship. Engagement goes up 8%. Victory!
Month 5-6: The Maintenance Treadmill
Two weeks later, engagement drops back to baseline. The model is stale—it’s still trained on data from 6 weeks ago. You need automated retraining. That means:
- Airflow DAGs to schedule training jobs
- Blue-green deployment for models
- Model versioning and rollback infrastructure
- Monitoring for model drift
Your team of three is now spending 60% of their time on infrastructure maintenance instead of improving the algorithm. Your PM wants to add filters (“don’t show videos in languages the user doesn’t speak”). That requires rebuilding the entire serving layer.
Six months in, you have a working system. But you’re now the permanent on-call owner of a fragile, expensive pipeline.
There’s a better way.
What if you could get the same sequential recommendation capability TikTok uses—but ship it today instead of next quarter? What if the infrastructure just… worked, without becoming your team’s full-time job?
How Shaped’s Managed Sequential Recommendation Infrastructure Saves Months
Shaped is a real-time retrieval database built specifically for this problem. Instead of stitching together Kafka, Flink, Redis, GPU clusters, and vector databases, you get a single unified system that handles the entire sequential recommendation pipeline.
What Shaped does for you automatically:
- **Real-time event ingestion:**Stream data via Segment, Kafka, or API—ingested within 30 seconds, no Flink required
- **GPU-managed training:**SASRec and BERT4Rec as declarative YAML configs—Shaped provisions GPUs, tunes hyperparameters, and retrains automatically
- **Low-latency inference:**Built-in feature serving, vector indexes, and ANN search—no Redis, no manual optimization
- **Zero-downtime deployment:**Model updates, versioning, and rollbacks handled automatically—no Airflow DAGs
You configure what you want (“train SASRec on video watch sequences”), and Shaped handles how it runs in production. No infrastructure to maintain, no on-call rotation, no debugging at 2am.
Here’s how to build a TikTok-style feed:
Step 1: Connect Your Real-Time Event Stream
For in-session reactivity, your retrieval engine needs to see events as they happen. Shaped supports streaming connectors (Segment, Kafka, Kinesis) that ingest data within 30 seconds, or you can use the Table Insert API for direct integration.
# stream_events.sh
# Stream events via API
$ curl -X POST "https://api.shaped.ai/v2/tables/video_events/table_insert" \
-H "x-api-key: YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"user_id": "u123",
"item_id": "v987",
"event_type": "watch_complete",
"timestamp": "2024-03-20T10:00:05Z"
}'Step 2: AI Enrichment (Materialize Content Understanding)
Sequential models perform better when they understand what is in the videos, not just raw IDs. Shaped’s AI Views use LLMs to materialize semantic descriptions from metadata, tags, or transcripts—creating a bridge between content and behavior that helps solve cold-start problems for new videos.
# ai_view.json
// Create an AI View in the Shaped Console
{
"name": "enriched_videos",
"view_type": "AI_ENRICHMENT",
"source_table": "video_catalog",
"source_columns": ["title", "tags", "transcript_snippet"],
"enriched_output_columns": ["semantic_vibe"],
"prompt": "Analyze the tags and transcript. What is the hyper-specific niche and mood of this video? Create a concise summary for a sequential discovery engine."
}Step 3: Define the Sequential Engine
This is the core of the “For You” algorithm. Configure a SASRec policy in your Engine YAML. Shaped automatically provisions GPUs, trains the Transformer on your sequence data, and prepares the vector index. Upload via CLI or configure in the Dashboard.
# engine.yaml
# engine.yaml
name: tiktok_style_feed
data:
item_table:
name: "enriched_videos"
type: table
interaction_table:
name: "video_events"
type: table
training:
models:
- name: sequential_transformer
policy_type: sasrec # Self-Attentive Sequential Recommendation
max_seq_length: 50 # Model the last 50 interactions
hidden_size: 64
n_heads: 2
n_layers: 2
index:
embeddings:
- name: video_embeddings
encoder:
type: trained_model
model_ref: sequential_transformerStep 4: Query with ShapedQL
When the user swipes, your app calls Shaped. Using ShapedQL, you retrieve the next video in the sequence while applying a hard filter to ensure you never show videos the user has already watched.
# feed_query.sql
SELECT *
FROM similarity(
embedding_ref='video_embeddings',
encoder='interaction_pooling',
-- Uses recent real-time sequence
input_user_id='$user_id',
limit=50
)
-- Hard filter: Never show watched videos
WHERE prebuilt('exclude_seen', input_user_id='$user_id')
-- Blend sequential prediction with trending content
ORDER BY score(
expression='0.8 * sequential_transformer + 0.2 * _derived_popular_rank'
)
LIMIT 1Why This Approach Wins
Compare what you’d build yourself vs. what Shaped provides:
DIY Approach
- Set up Kafka, Flink/Spark Streaming, and Redis
- Train SASRec from scratch (PyTorch, GPU management, hyperparameter tuning)
- Build model serving infrastructure with sub-100ms latency
- Maintain ANN indexes (Faiss/HNSW) as your catalog grows
- Handle retraining, deployment, and monitoring
Timeline: 3-6 months
Shaped Approach
- Connect data via streaming connector or API (30 seconds to ingest)
- Configure SASRec in YAML (automatic GPU provisioning and training)
- Query via ShapedQL (built-in low-latency serving and ANN search)
- Zero infrastructure management (Shaped handles retraining, scaling, monitoring)
Timeline: Less than a day
What You Gain
By using Shaped for sequential recommendations, you achieve:
- **In-Session Reactivity:**Streaming connectors ingest events within 30 seconds; the feed adapts as user interests shift mid-session
- **Zero MLOps Overhead:**No need to manage Transformer training infrastructure, GPU allocation, or real-time feature stores
- **Deterministic Business Rules:**Combine sequential modeling with hard constraints (“Only show videos from the user’s region”) using standard SQL WHERE clauses—eliminating hallucinations on business logic. (Learn more about building deterministic agents with hard filters)
- **Production-Ready from Day One:**Built-in autoscaling, monitoring, and retraining—no operational burden
The Bottom Line
Stop building static feeds for dynamic users. Sequential recommendation isn’t just for TikTok—it’s for any product where user intent evolves within a session: e-commerce, content discovery, job search, dating apps. It also solves the positional bias problem that plagues traditional retrieval systems by understanding the order of user interactions.
The difference is infrastructure. You can spend months building and maintaining streaming pipelines, GPU training clusters, and real-time feature stores—or you can configure SASRec in a YAML file and ship today.
Shaped gives you TikTok-grade sequential modeling without TikTok-grade infrastructure complexity.
Who needs this? Any product where user intent evolves within a session: short-form video apps, e-commerce (“people who bought X then bought Y”), job search (understanding evolving job preferences), dating apps (learning taste from swipes), news feeds, music discovery.
The question isn’t whether sequential recommendations work—TikTok proved they do. The question is whether you want to spend 6 months building the infrastructure, or ship the feature today.
When Building In-House Might Make Sense
Shaped isn’t for everyone. You might want to build your own sequential recommendation infrastructure if:
- You have a dedicated ML research team that thrives on experimenting with cutting-edge architectures, without tight deadlines
- You need to implement research papers before they’re productionized (and have the expertise to do so)
- Your scale is so massive that custom hardware optimization becomes necessary (think Netflix/YouTube level)
For the other 95% of companies? Shaped gets you 90% of the results with 5% of the effort. That’s the trade-off worth making.
Frequently Asked Questions
How long does it take to build a sequential recommendation system?
Traditional DIY approaches take 3-6 months for infrastructure setup, model training, and deployment. With Shaped’s managed infrastructure, you can deploy SASRec or BERT4Rec models in under a day.
What is SASRec?
SASRec (Self-Attentive Sequential Recommendation) is a Transformer-based model that predicts the next item a user will interact with based on their recent behavior sequence. It powers TikTok-style feeds that adapt in real-time to user preferences.
Do I need a data science team to use sequential recommendations?
No. Shaped provides SASRec and BERT4Rec as managed policies with automatic hyperparameter tuning and GPU provisioning. You configure what you want via YAML; Shaped handles the ML complexity, training, and deployment automatically.
How much does it cost to run sequential recommendations at scale?
DIY infrastructure typically costs $5-15k/month in GPU instances, storage, and streaming infrastructure (Kafka, Flink, Redis). Shaped’s usage-based pricing starts with $300 in free credits.
**Ready to build a reactive feed?**
Sign up for Shaped and get $300 in free credits. See how sequential Transformers transform user engagement. Visit console.shaped.ai/register to get started.
Want us to walk you through it?
Book a 30-min session with an engineer who can apply this to your specific stack.