Shaped makes building recommender systems like this easy for developers because it packages a complex and performant recommender system into three simple layers:
- A data layer to store your data or connect to a real-time source
- An ML layer that indexes on your data and supports the latest recommender models and architectures
- An API layer to interface with client applications and power real-time recommendations
In this article, I will show you how I used Shaped to build a movie recommendation system.Click here to check out my final demo application.
.jpg)
Upload your datasets
Any machine learning system is only as good as the data it is trained on.
For data, I started with a public dataset called movielens that is well-known in the machine learning industry. It contains 100,000 ratings of 9000 movies, ranging from the early 1900s to 2018.
My suggestion system will be built with two data sources from movielens:
-
Movies: a catalog of 9000 movies
-
Ratings: a list of user-generated ratings
The first step was to load this data into Shaped. This was a relatively easy process; movielens data is very clean so the only step was convert the data files to jsonl format.
Shaped also supports automated import from systems like Postgres, MySQL, S3, Apache, and more.
Enriching my dataset with semantic information
To give my model more to work with, I wrote a small Python script to get metadata from the IMDb API. This enrichment step is crucial to enable semantic search on my dataset.
I added columns for description, cast, writers, etc, so my model can respond to searches like - “Movies written by Paul Thomas Anderson”.
# script.py
# Load movies from JSONL file
movies = []
with open('movies.jsonl', 'r') as f:
for line in f:
movies.append(json.loads(line))
# Process each movie with API enrichment
for i, movie in enumerate(movies):
imdb_id = movie.get('imdbId')
try:
response = requests.get(url, headers=headers, timeout=30)
result = response.json()
# Extract and process movie data
directors = result.get("directors", [])
directors_string = ','.join([d.get('fullName', '') for d in directors])
writers = result.get("writers", [])
writers_string = ','.join([x.get('fullName', '') for x in writers])
cast = result.get("cast", [])
cast_string = ','.join([x.get('fullName', '') for x in cast])
# Update movie with enriched data
movies[i].update({
"description": result.get("description"),
"interests": result.get("interests"),
"release_date": result.get("releaseDate"),
"directors": directors_string,
"cast": cast_string,
"writers": writers_string,
})
# Save enriched movies to JSONL file
with open('enriched_movies.jsonl', 'w') as f:
for movie in movies:
f.write(json.dumps(movie) + '\n')The full enrichment script is in /model/scripts/enrich-movies.py
Defining my model
After my data was loaded, it was time to configure my model. Shaped makes it very easy to set up your first model: just upload a YAML file.
There are three config components to know: connectors, fetch, and model.
-
connectors: Defines which datasets to connect to my model.
-
fetch: to define the SQL that Shaped will use to get my training data. For this model, I configured an items table (movies) and an events table (user behaviour like ratings and clicks).
-
model: Declare how the model will actually score and rank items. It exposes two important fields:
- policy_config: Define the ranking algorithm and how the model learns
- inference_config: Tweak how your model serves results at runtime (inputs, retrieval methods, diversity, etc)
I’ll save the details for another blog post, but here’s the full model config for your reference: model.yaml
Building the frontend
Since I’m creating this demo from scratch, I spent some time building a Next.js app to showcase the model.
I built some generic components to start:
- Carousel to show a category of movies
- Search bar
- Card when you click on a movie that shows further details
- Similar movies
I also wrote some logic to track which items a user clicks on. These are sent back to Shaped as new events in the “events” dataset.
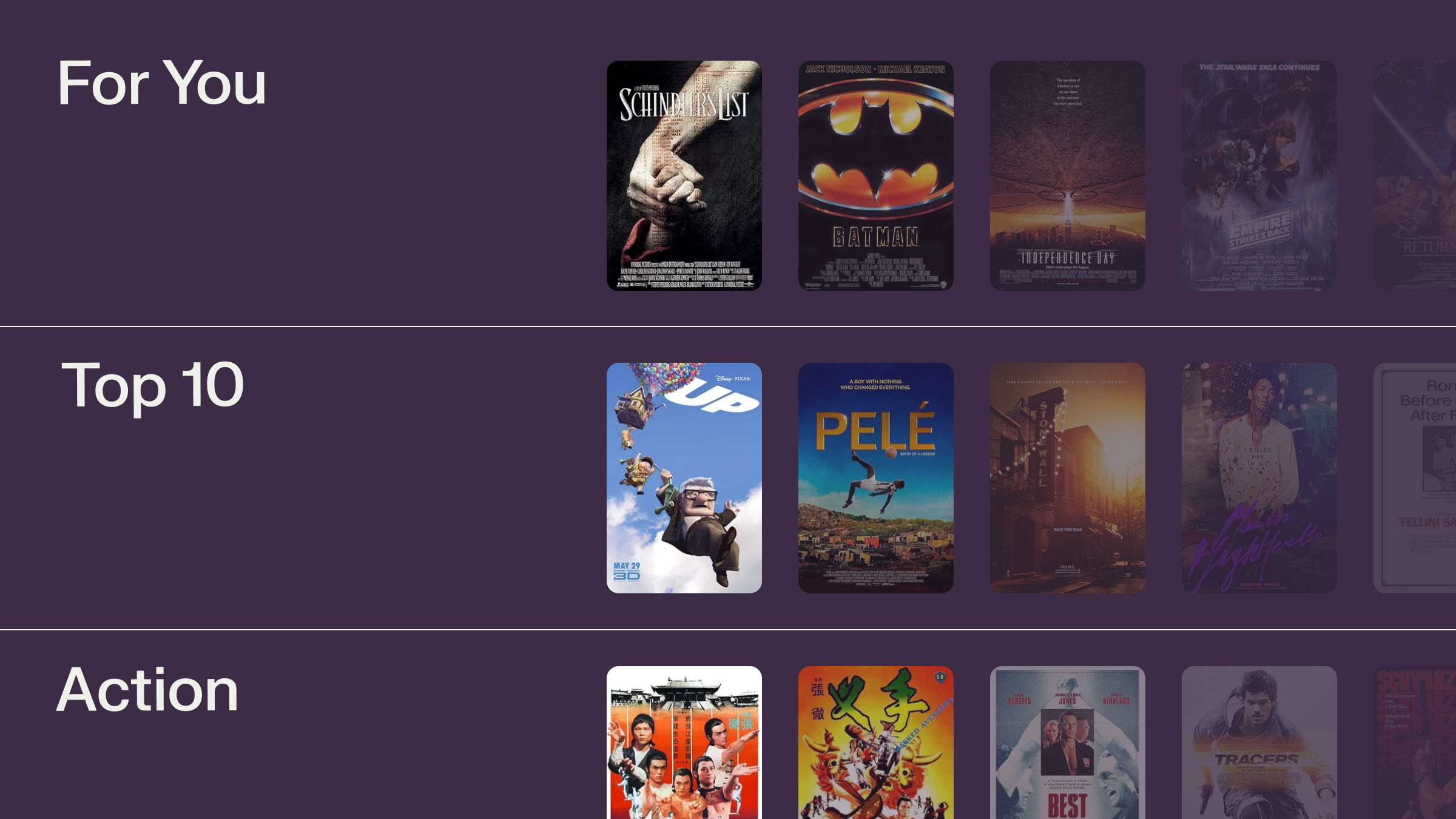
Here’s what the first version looked like, with dummy data:
Wiring my model to the Shaped API
After building my frontend and training my model, it was time to wire my app to the Shaped API.
The benefit of using Shaped is its single-model versatility**. A single model can serve multiple use cases across my app.** I don’t have to train a recommendation model, a separate semantic search one, and then a third similarity model.
As you’ll see, the same model will be used to get personalized recommendations, run semantic search, and get trending movies, similar movies that other people liked, and recommendations in a specific category.
This dramatically reduces complexity and ensures consistent ranking logic across my application.
Feature 1: Personalized “For you” carousel
The topmost carousel should show a personalized “For you” feed of movies that the user may like. To do this, we call the Shaped /rank endpoint, which returns a personalized list of rankings based on user IDs, interactions, a text query, and anything else you want to pass it.
For this carousel, we want rankings that are:
- Conditioned on the current user’s unique ID
- Conditioned on any recent interactions that the model may not have been trained on, but do not return these items
- Include item metadata (title, genre, etc) to save a trip to the server
- Include some less-relevant items to prompt exploration
The final call to the /rank endpoint looks like this. Notice we include interactions, user_id, and an exploration_factor to adjust the flavour of our results set:
# foryou.js
const forYouMovies = await fetch("/models/movie_recs/rank", {
method: "POST",
headers: {
"Content-Type": "application/json",
"x-api-key": token,
},
body: JSON.stringify({
return_metadata: true,
limit: 20,
user_id: userId,
interactions: stringInteractions,
config: {
filter_interaction_iids: true,
exploration_factor: 0.2,
},
}),
});
return (
<MovieList movies={forYouMovies} />
)Feature 2: Semantic search using the same model
As mentioned before, we’ve trained this ranking model and get semantic search for free. In this case, we use the /retrieve endpoint with a text query. This returns a set of relevant results with no personalization. This is important because a search should be agnostic to a user’s preferences.
# MovieList.js
const getMovies = async (searchQuery) => {
try {
const response = await fetch("/models/movie_recs/retrieve", {
method: "POST", headers,
body: JSON.stringify({
return_metadata: true,
explain: true,
text_query: searchQuery,
config: {
exploration_factor: 0,
diversity_factor: 0,
diversity_attributes: [],
limit: 50
}
}),
});
const searchResults = await response.json();
setMovies(searchResults?.data?.metadata || []);
} catch (error) { ... }
};
const handleInputChange = (event) => {
const searchQuery = event.target.value;
setQuery(searchQuery);
getMovies(searchQuery);
};
return (
<div>
<Input
value={query}
onChange={handleInputChange}
placeholder="Search for movies..."
/>
<MovieList movies={movies} />
</div>
);Feature 3: Powering a “People also liked…” section
We can pass the model a movie ID and it will show us similar movies. To do this, we call the /similar_items endpoint with an item_id parameter. This returns the movies that are most similar to the selected one.
# SimilarMovies.js
const similarMovies = await fetch("/models/movie_recs/similar_items", {
method: "POST",
headers,
body: JSON.stringify({ item_id: item_id }),
});
return (
<MovieList movies={similarMovies} />
)Feature 4: Adding genre filters
Again we can support a new use case with our same model. I can add carousels for a specific genre, with personalized recommendations based on the user’s activity. I use a similar API call as the first example, but filtered for only a specific genre. For this, I use the /rank endpoint with a filter_predicate attribute:
# GenreFilter.js
const actionMovies = await fetch("/models/movie_recs/rank", {
method: "POST", headers,
body: JSON.stringify({
filter_predicate: `array_has_any(genres, ['Action'])`,
user_id: userId,
interactions: stringInteractions,
limit: 20,
return_metadata: true,
}),
});
return (
<MovieList movies={actionMovies} />
)Feature 5: Adding real-time interactions
Finally, we can make our model better over time by inserting the interactions back to our events table, using /datasets/{name}/insert:
# InteractionTracking.js
const trackClick = () => {
await fetch("/datasets/events_table/insert", {
method: "POST",headers,
body: JSON.stringify({
data: [
{
event_value: payload.event_value,
movieId: payload.movieId,
timestamp: payload.timestamp,
userId: payload.userId
}
]
}),
})
};
return (
<button type="button" onClick={trackClick} className="text-left w-full"> <MovieCard />
</button> )Conclusion
I built a real-time, production-ready movie recommendation system without deep machine learning expertise.
Shaped abstracts the complex training and deployment pipeline, allowing me to go from raw data to a fully functional application quickly. I powered personalized ranking, semantic search, and item similarity using a single model and without touching any infrastructure.
The full code for this project (including data and model config) is available on GitHub.