These experiences aren’t just “nice to have” for consumers; they are critical for business survival. At companies like Meta, we saw experiments comparing AI-driven ranking against chronological feeds deliver staggering impact, in some cases up to an 800% increase in engagement. That isn’t just a better user experience; it is a product-changing impact. Features, and sometimes entire startups, live or die based on this kind of lift.
The Path Through the Noise
Despite having a clear vision for the future, the exact path to get there wasn’t straight. There are infinite ranking and discovery use-cases, from website optimization to email marketing. Where do you start?
Relevance is valuable everywhere, but it is existential for some. For example, an e-commerce store with 20 product SKUs doesn’t need a complex engine; a user can scroll through that inventory in seconds. But for a store with 10,000 items, algorithmically surfacing the right product is the difference between a purchase and a bounce.
To find our wedge, we spoke to hundreds of customers. By 2022, the industry had shifted. We saw a massive spike in demand for “For You” feed infrastructure, driven by the rapid rise of TikTok, and a persistent need for robust e-commerce recommendations. Because the “For You” pattern was relatively new, the infrastructure patterns hadn’t solidified yet, so it was the perfect place for us to start.
We launched Shaped 1.0 focused on these areas, and the results were undeniable. We saw customers achieve 120% increases in engagement and 10% lifts in conversion. We knew we were on the right track.
The “Frankenstein” Problem
Since then, we’ve slowly tackled more verticals: email optimization, marketing alerts, “What to watch next,” and cart cross-sells. Last year, we naturally expanded into Search.
Historically, the industry treated Search and Recommendations as separate disciplines. You had Elastic/OpenSearch for keyword retrieval, and a separate Python stack or Vector DB for recommendations. But recently, we’ve seen a “Technical Convergence.” A ranking engine that understands user intent improves Search, and a search engine with semantic understanding of content improves Recommendations.
Maintaining two separate stacks for what is essentially the same math (ranking) is inefficient and costly. Given that almost every company with a ranking problem also has a search problem, extending Shaped into a unified retrieval platform was the logical next step.
By early 2025, we had explored the entire search space of discovery use-cases. But we hit a wall: API Complexity.
To achieve our vision of making all digital surfaces intelligent, integration needs to be effortless. Whether a company sees a 5% lift or an 800% lift, the friction to find out must be near zero.
We had added so many use-cases that our API had become a “Frankenstein’s Monster.” Yes, the value was there. Yes, our solutions engineering team could get you set up. But the API was patched together based on years of differing customer requirements. It wasn’t declarative. It was a collection of implicit configurations where, if one thing was off, the errors were opaque. We realized that our implicit, YAML-first interface was holding us back from being a true self-serve product.
The Shift to Agents & LLMs
Simultaneously, the developer experience shifted beneath our feet. Personally, I’ve gone from coding 90% of the time to having LLMs write 90% of my code. Furthermore, our customers began asking for Agent Retrieval (RAG).
The relevance engine that powers today’s search is the context engine that will power tomorrow’s AI agents. To support this, we needed an API that wasn’t just easy for humans to read, but easy for LLMs to understand. LLMs need concise, declarative documentation.
The goal became clear: Launch a new, declarative API purpose-built for the AI era, using the same powerful Shaped engine but configured in an explicit, transparent way.
We call thisShaped 2.0, and we are excited to announce it today.
What is Shaped 2.0?
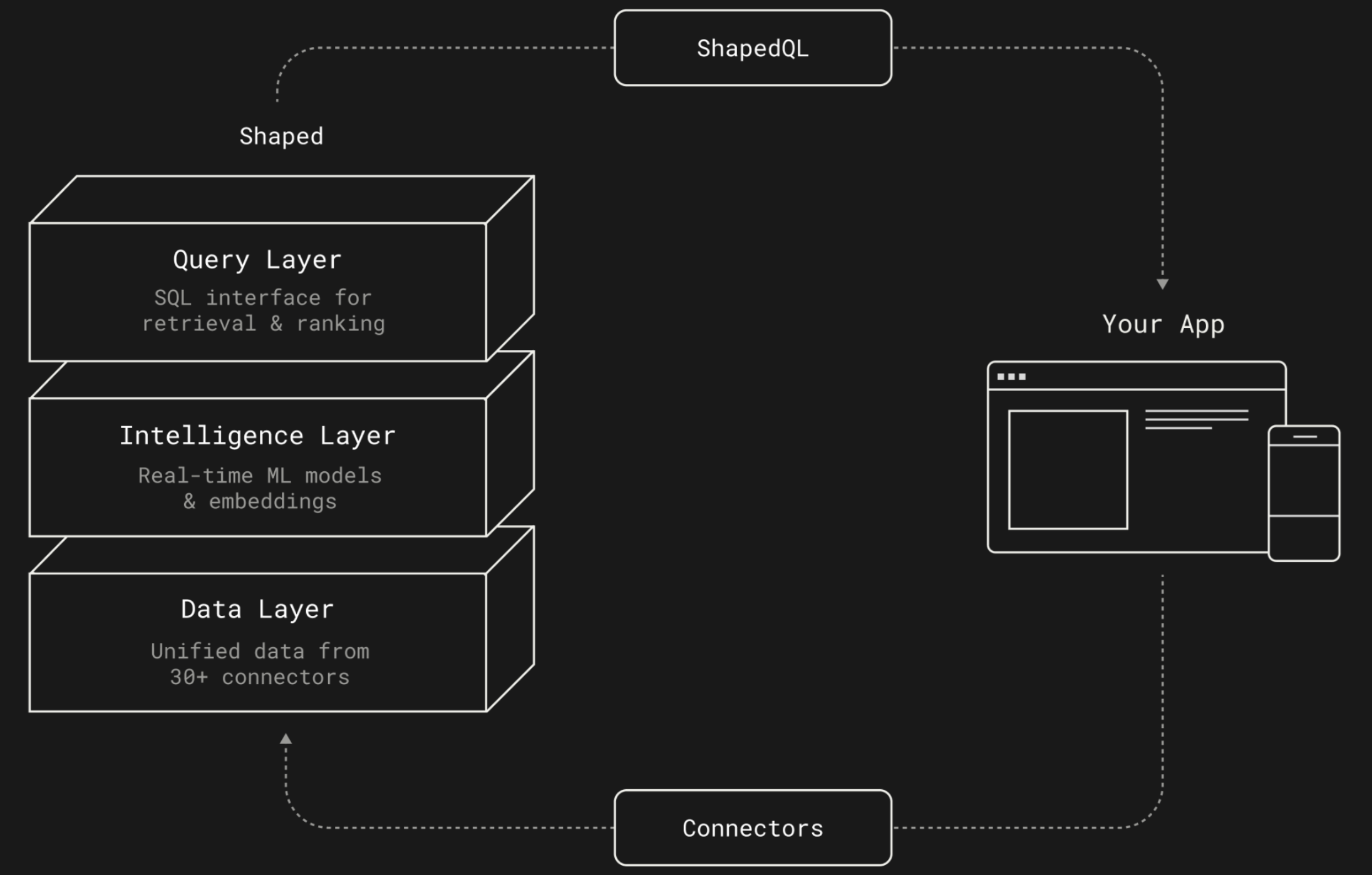
You can think of Shaped 2.0 less like a recommendation tool and more like a Database for Relevance.
In the past, building a state-of-the-art system meant stitching together multiple components:
- Vector Databases (e.g., Pinecone/Milvus): Great for retrieval, but they lack the complex ranking logic needed for business goals.
- Search Engines (e.g., Elastic/OpenSearch): Great for keywords, but they struggle with semantic understanding and personalization.
- Feature Stores (e.g., Redis): Needed to store real-time user signals.
Shaped 2.0 collapses this stack.
You insert your source of truth — user catalog, candidate catalog (products/content), and interaction events. Shaped indexes that data into semantic vector representations, computes statistical cross-features, and prepares it for downstream machine learning models.
On top of this, we provide a SQL query interface that allows you to declaratively describe exactly how you want to retrieve data for search, recommendations, or RAG.
Shaped 2.0 is built on three layers:
1. The Query Layer
This layer provides serverless, low-latency (<50ms) endpoints powered by ShapedQL, a SQL-like language for composing multi-stage ranking pipelines. A standard pipeline looks like this:
- Retrieve: Source candidates (e.g., via BM25 or Vector Search).
- Filter: Apply business rules (e.g., exclude “already seen” items).
- Score: Rank using ML models.
- Reorder: Optimize for diversity or exploration.
Here is an example of Hybrid Search in ShapedQL. We combine semantic vectors, keyword search, and a robust reranker:
| 1 | SELECT title, description |
| 2 | FROM |
| 3 | semantic_search(“$param.query”), |
| 4 | keyword_search(“$param.query”) |
| 5 | ORDER BY |
| 6 | colbert_v2(item, “$param.query”) + |
| 7 | click_through_rate_model(user, item) |
This language is expressive enough to map search, ranking, and agent retrieval tasks to a single syntax.
2. The Intelligence Layer
This layer defines how data is encoded, indexed, and trained. It handles the heavy lifting of machine learning operations.
For the hybrid search example above, the configuration might look like this:
| 1 | # hybrid-search-engine.yaml |
| 2 | data: |
| 3 | item_table: posts |
| 4 | interaction_table: click_events |
| 5 | index: |
| 6 | embeddings: |
| 7 | - type: hugging_face |
| 8 | model_name: answerdotai/ModernBERT-base |
| 9 | item_fields: |
| 10 | - description |
| 11 | - title |
| 12 | training: |
| 13 | schedule: @hourly |
| 14 | models: |
| 15 | - policy_type: lightgbm |
| 16 | name: click_model |
| 17 | events: |
| 18 | - clicks |
This declarative approach allows for “Product GitOps”, every change to your relevance logic can be tracked, reviewed, and deployed safely.
3. The Data Layer
Garbage in, garbage out. We’ve seen every messy data stack imaginable, so we built the Data Layer to handle the chaos.
Shaped connects to 30+ sources (Snowflake, Postgres, Shopify, Kafka, etc.). But ingestion isn’t enough. We provide SQL and AI Enrichment Transforms, materialized views that clean and unify your data. You can use AI enrichments to impute missing tags or normalize descriptions, ensuring your models have a 360-degree view of your users and catalog.
To get started, jump over to the Shaped console, connect your datasets, and register your transforms. Check it out here.
Get Started Today
Shaped 2.0 is ready for use today. To match our new declarative interface, we’ve introduced a transparent pricing model based strictly on your usage: data volume, training compute, and serverless requests. You can start small, prove the value, and scale seamlessly.
We are also fully SOC 2 compliant and enterprise-ready. You can go to production knowing your data is secure and that our infrastructure is built to handle fault tolerance and massive scale automatically.
Sign up today at console.shaped.ai/register, or get in touch if you’d like a personalized demo.
The Future
Building Shaped has been an incredibly enlightening and humbling experience. The last decade is littered with the graveyard of recommendation startups. Most failed because they were either too vertical (stuck in Shopify apps) or too abstract (trying to solve everything without solving anything).
We tried to walk the line: iteratively scoping down, proving value, and expanding only when ready. That strategy, combined with the tailwinds of AI, has allowed us to reach this point.
The Age of Agents
What does the future hold? We believe relevance is moving beyond human scrolling. We are entering the era of Agent Retrieval.
While humans will always enjoy browsing, a new user is entering the chat: the AI Agent. In the near future, websites won’t just be visual interfaces for humans; they will be databases that Agents query to make decisions for their users. If your relevance engine cannot effectively serve these agents, you become invisible.
We envision Shaped 2.0 as the unified engine that serves both: the discovery experiences humans love today, and the semantic retrieval APIs that AI agents will require tomorrow.
Try Shaped 2.0 for free here, Watch the tutorial below.
Want a live walkthrough of this feature?
Book time with the team and we'll show you exactly how it works.