Embeddings are the intelligence behind Shaped’s personalized recommendations: dense vector representations of users and items that capture deep behavioral patterns and semantic relationships.
This article explores how teams can move beyond ranked results to directly access and leverage these embeddings via Shaped’s API, enabling use cases like similarity search, advanced analytics, churn prediction, and custom machine learning models.
Instead of building complex embedding pipelines from scratch, Shaped delivers these powerful representations out of the box, letting teams unlock advanced personalization and insight with minimal effort.
Beyond Predictions: Understanding the “Why”
Shaped’s rank, similar_items, and other API endpoints provide powerful, ready-to-use solutions for common search and recommendation tasks. They deliver personalized results based on complex models trained on your data. But what if you need more than just the final ranked list? What if you want to understand the underlying structure the model has learned? What if you need access to the raw intelligence – the building blocks – to power custom analyses, unique recommendation logic, or other machine learning models?
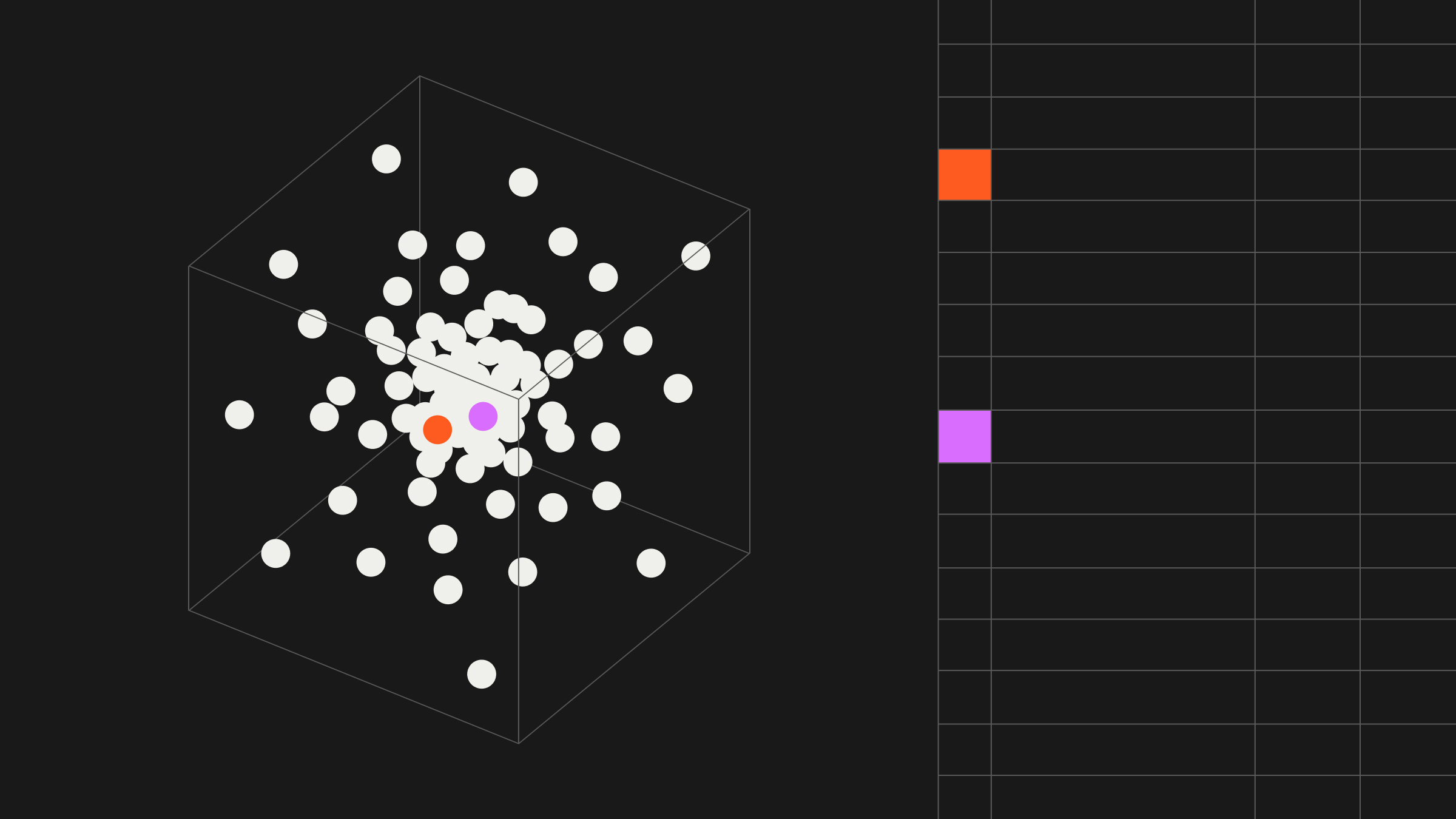
This is where embeddings come in. At their core, modern recommendation models like those used by Shaped learn dense vector representations – embeddings – for every user and item. These embeddings place users and items in a high-dimensional space where proximity indicates similarity. Items frequently bought together end up close; users with similar tastes occupy nearby regions. Accessing these embeddings allows you to “peer inside the black box” and leverage this learned knowledge directly. Building systems to generate high-quality embeddings from scratch, however, is a formidable ML engineering challenge, and quite often the crux of constructing a framework of accurate understanding.
Unlocking Advanced Use Cases with Embeddings
Accessing raw embeddings opens up powerful possibilities:
- Custom Similarity Engines: Calculate cosine similarity (or other distance metrics) between item embeddings to build your own “Similar Items” features with custom logic or filtering not available in the standard similar_items API. Do the same for user embeddings to find “Similar Users.”
- Enhanced Analytics & Visualization:
- Clustering: Apply clustering algorithms (like K-Means) to user embeddings to discover natural user segments based on learned behavior, rather than just demographics.
- Visualization: Use dimensionality reduction techniques (t-SNE, UMAP) on item or user embeddings to create 2D maps visualizing relationships, identifying niches, or understanding market structure.
- Featurization for Downstream ML: This is a key benefit! Use the rich, learned representations captured in Shaped’s embeddings as input features for other machine learning models:
- Churn Prediction: User embeddings often capture behavioral patterns predictive of churn.
- Lifetime Value (LTV) Prediction: Embeddings can encapsulate engagement levels correlated with LTV.
- Cohort Analysis: Analyze how embeddings differ across predefined cohorts or how they evolve over time.
- Targeted Marketing: Use embedding similarity to find users similar to high-value customers for lookalike campaigns.
- Advanced Recommendation Strategies: Implement custom recommendation algorithms (e.g., content-based filtering using item embeddings, complex hybrid approaches) using Shaped’s embeddings as a starting point.
- Model Diagnostics: Inspect embeddings to qualitatively understand what the model has learned about specific items or users.
The Standard Approach: The High Cost of DIY Embeddings
Generating effective user and item embeddings that capture complex relationships requires significant effort:
Step 1: Data Aggregation and Preparation
- Method: Gather vast amounts of user interaction data (clicks, views, purchases, ratings, etc.) and potentially rich user/item metadata (text descriptions, categories, user attributes).
- Implementation: Build robust data pipelines to collect, clean, and process this data from various sources.
- The Challenge: Requires significant data engineering effort and infrastructure to handle large volumes of diverse data reliably.
Step 2: Choosing and Training Embedding Models
- Method: Select appropriate embedding techniques. Options range from classic matrix factorization (ALS, SVD) to more advanced methods like Word2Vec variants (Prod2Vec), graph embeddings, or state-of-the-art deep learning models (using RNNs, Transformers like BERT/GPT on interaction sequences or content).
- Implementation: Requires deep machine learning expertise to choose the right architecture, configure hyperparameters, and implement the training process using frameworks like TensorFlow or PyTorch.
- The Challenge: Model selection and training demands specialized ML skills. Training advanced models also requires substantial computational resources (GPUs) and time.
Step 3: Building Serving Infrastructure
- Method: Once embeddings are generated (often periodically via batch training), they need to be stored and made accessible for downstream tasks.
- Implementation: Requires setting up storage (e.g., databases, vector databases like Pinecone/Weaviate/Milvus for similarity search) and building APIs to retrieve embeddings or perform similarity lookups efficiently.
- The Challenge: Requires managing storage infrastructure, potentially specialized vector databases, and building low-latency serving APIs. Keeping embeddings fresh requires rerunning complex training pipelines regularly and quickly.
Step 4: Integrating Multiple Signals
- Method: The best embeddings often combine signals from user behavior, item content (text, images), and user attributes.
- Implementation: Designing models and pipelines that effectively fuse these different data modalities adds significant complexity to both training and data preparation.
- The Challenge: Advanced modeling techniques and intricate data engineering are needed in order to truly blend different signals into a semantically sensible embedding space.
The Shaped Approach: Embeddings-as-a-Service via API
Shaped eliminates the need for you to undertake the complex process of building embedding generation systems yourself. The same powerful models trained to deliver personalized rankings can also produce high-quality user and item embeddings. Shaped provides simple, dedicated API endpoints to access these learned representations directly.
How Shaped Simplifies Access to Embeddings:
-
Leverage Pre-Trained Intelligence: Access embeddings generated by Shaped’s state-of-the-art models, trained on your specific data (interactions, item metadata, user features).
-
No ML Training Required: Skip the complex model selection, training, hyperparameter tuning, and infrastructure setup associated with DIY embedding generation.
-
Simple API Endpoints: Use straightforward API calls to retrieve embeddings for specific users or items:
- create-user-embedding: Get embeddings for a list of user IDs.
- create-item-embedding: Get embeddings for a list of item IDs.
-
Unified Platform: Generate embeddings from the same models used for your core ranking and recommendation tasks, ensuring consistency.
-
Managed Infrastructure: Shaped handles the storage and retrieval of embeddings via its scalable API infrastructure.
Accessing Embeddings with Shaped: A Conceptual Example
Let’s illustrate how to retrieve embeddings for a specific user and a set of items.
Goal: Get the vector representations for USER_777 and items ITEM_A, ITEM_B.
1. Ensure a Model is Trained: You need an active Shaped model trained on your relevant data (user interactions, item metadata). Let’s assume you have a model named main_discovery_engine.
2. Fetch Embeddings via API:
-
Step A (Identify IDs): Determine the user ID (‘USER_777’) and item IDs ([‘ITEM_A’, ‘ITEM_B’]) you need embeddings for.
-
Step B (Call Shaped APIs):
# embedding_example.js
const shapedClient = new ShapedClient({ apiKey: apiKey });
# Call the createUserEmbedding method
const userEmbeddingResponse = await shapedClient.createUserEmbedding({
modelName: modelName,
userIds: userIdsToFetch
});
console.log(\`Retrieved ${userEmbeddingResponse.embeddings.length} user embedding(s).\`);
# Call the createItemEmbedding method
const itemEmbeddingResponse = await shapedClient.createItemEmbedding({
modelName: modelName,
itemIds: itemIdsToFetch
});
console.log(\`Retrieved ${itemEmbeddingResponse.embeddings.length} item embedding(s).\`);- Output: The APIs return the corresponding embedding vectors for the requested IDs.
Conclusion: Leverage Deeper Intelligence, Effortlessly
Shaped’s core value lies in the sophisticated understanding its models develop about your users, items & their interactions. While standard ranking APIs provide convenient access for common tasks, the create-user-embedding and create-item-embedding endpoints unlock the raw power of this learned intelligence.
Stop wrestling with the complexities of building embedding models from scratch. Leverage Shaped’s Embedding APIs to easily obtain state-of-the-art user and item representations. Power advanced analytics, build custom ML models for tasks like churn prediction, create unique similarity features, and gain deeper insights into your data – all built upon the robust foundation managed by Shaped.
Ready to unlock the full potential of your data with embeddings?
Request a demo of Shaped today to explore the Embedding APIs. Or, start exploring immediately with our free trial sandbox.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.