But here’s the thing: these same laws hold in domains other than language. In fact, some of the most consequential applications of scaling laws today are invisible to the end-user. They’re running under the hood of your credit card payments, your Netflix home screen, and your ride-share app’s matching system.
And unlike LLMs, the interface is not text – it’s embeddings.
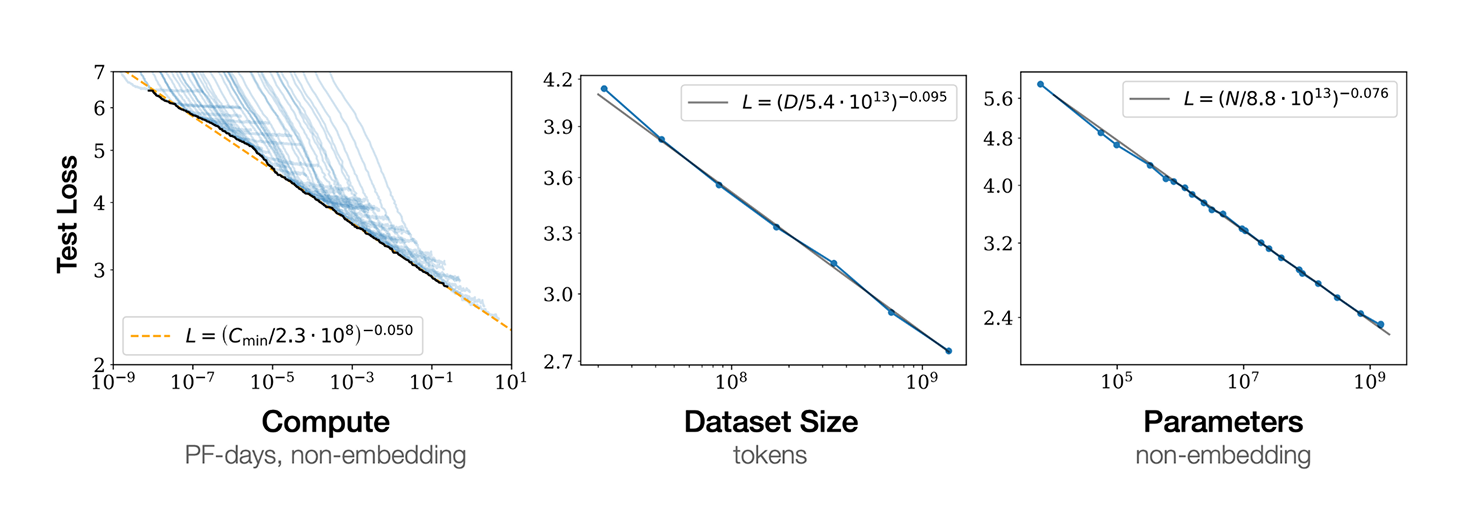 Scaling Laws for Neural Language Models (https://arxiv.org/pdf/2001.08361, 2020)
Scaling Laws for Neural Language Models (https://arxiv.org/pdf/2001.08361, 2020)
1. The Three Eras of Machine Learning
To fully grasp this shift, it’s helpful to see it as the third major era of machine learning:
-
ML 0.0: Pre-Deep Learning. This was the era of hand-crafted features, logistic regression, SVMs, and gradient boosting. Systems were powerful but brittle, requiring expert domain knowledge for every new problem.
-
ML 1.0: Deep Learning & Task-Specific Models. With the rise of deep learning, we saw CNNs for vision, RNNs for sequences, and matrix factorization for recommendations. Each team trained bespoke models for narrow tasks. This led to huge progress, but organizationally, models fragmented into silos.
-
ML 2.0: Foundation Models & Scaling Laws. This is the current era, driven by the realization that scaling data, compute, and parameters yields smooth, predictable gains. Instead of bespoke models, organizations unify around large, general-purpose models—with embeddings as the universal interface.
Most of the hype has focused on ML 2.0 in language. But the same playbook is now being applied with world-changing results in nearly every other domain.
2. Scaling Laws in the Wild: Beyond NLP
Let’s go through some examples i’ve seen that demonstrate how different companies are making the most of scaling laws in real, production scenarios:
Stripe: Transactions as a Language
Stripe’s Payments Foundation Model reimagines payment transactions as a sequence modeling problem. By scaling training across billions of transactions, they discovered the same power-law improvements seen in NLP — fraud detection, risk modeling, and personalization all improved with scale. Payments Foundation Mode Launch.
.png)
Pinterest: One Embedding to Rule Them All
Pinterest published how they shifted from maintaining dozens of task-specific embeddings (for ads, search, recommendations, etc.) to a single universal embedding trained on massive multi-task data. The payoff: operational simplicity and transfer learning across use-cases.Shaped blog write-up
Etsy: Industrial-Scale Embedding Unification
Etsy researchers showed how unifying their embedding space across different verticals and tasks unlocked reuse, reduced duplication, and improved generalization. Theirpaper is one of the clearest technical deep dives into making this work in production.
Meta: Generative Recommenders and Scaling Laws
Meta researchers explored generative recommenders, finding that — much like LLMs — recommendation quality followed predictable scaling laws as they increased data, compute, and model size. Eugene Yan asked the right question: “Is this the ChatGPT moment for recommendation systems?”Shaped blog write-up
Netflix: A Foundation Model for Recommendations
Netflix built a foundation model that unified multiple recommendation tasks — from “because you watched…” to homepage personalization. Scaling across heterogeneous behavioral data didn’t just improve accuracy, it reduced the need for task-specific models.Netflix Tech Blog
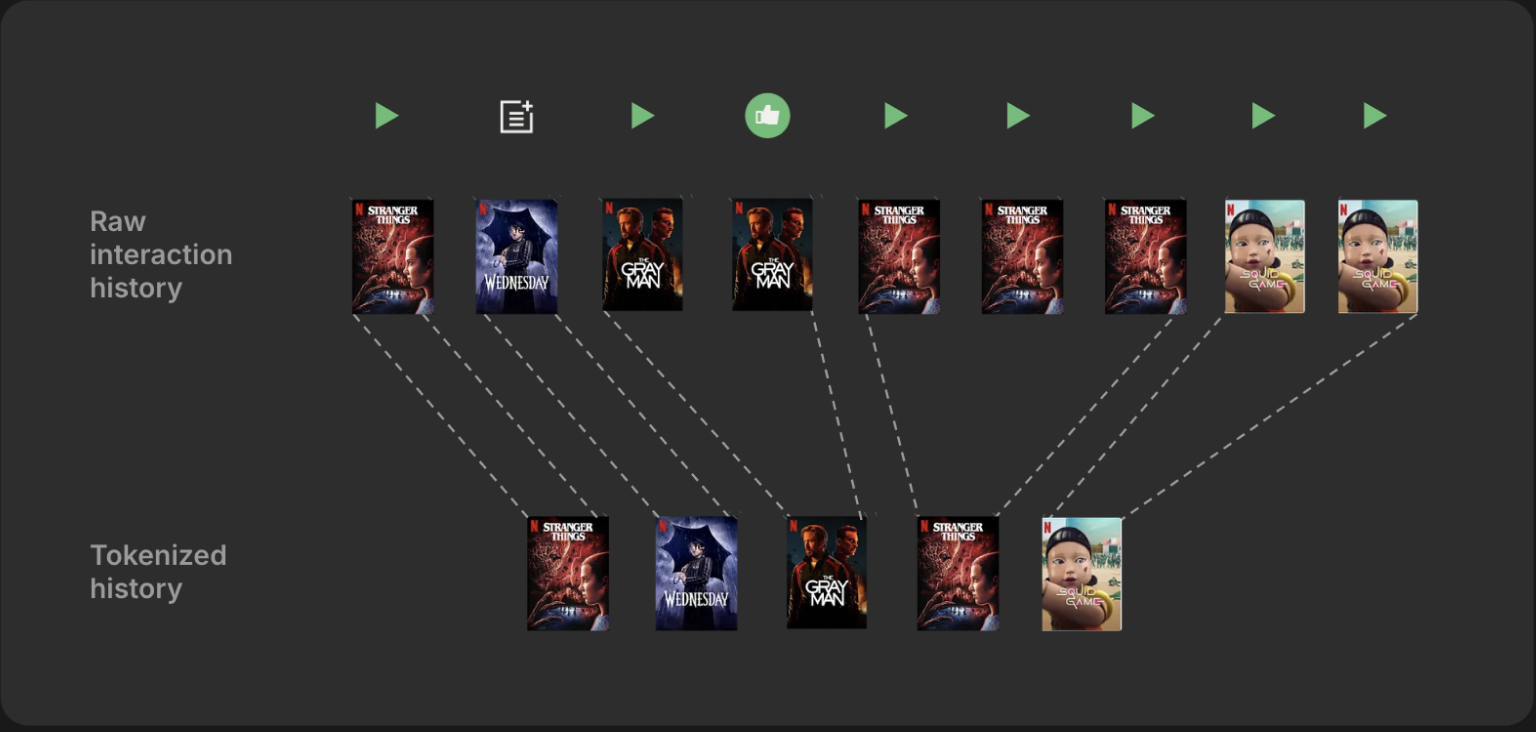
3. How These Systems Work: A Deep Dive into Netflix
Let’s examine Netflix’s architecture in more technical depth (Netflix TechBlog, 2025).
Tokenization of Behavior
Events (watch, browse, pause, trailer view) are tokenized. A token includes all the metadata about a title and the interaction, e.g.
- Title Genre
- Title release location
- Title release date
- Event duration (e.g. watch event)
- Event device type
- Event timestamp
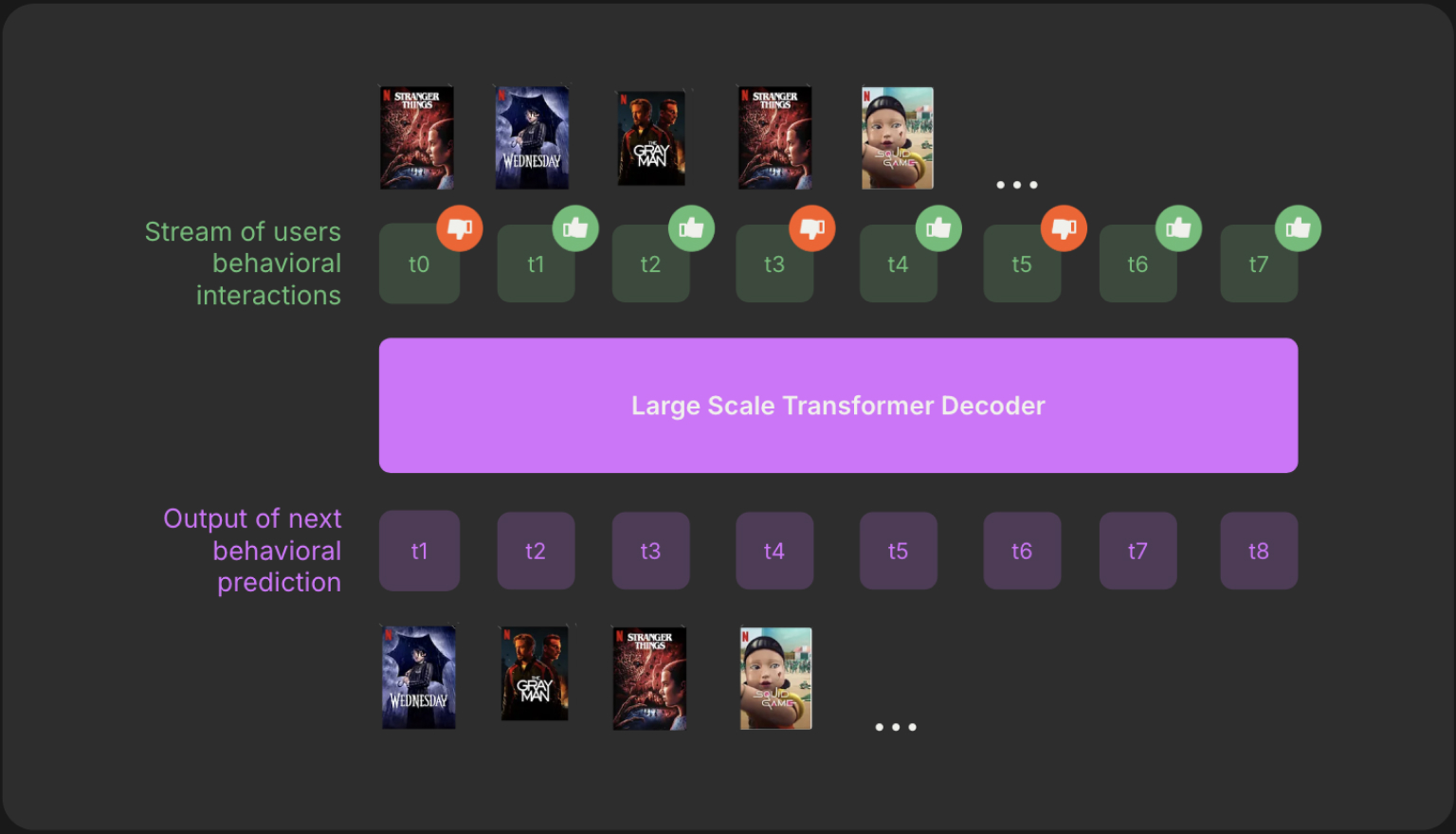
Features are embedded and fused with learnable title embeddings which is passed into a transformer decoder architecture.
Training Strategies
-
Sparse attention reduces complexity of attention from O(n²) to near O(n log n).
-
Sliding-window sampling during training ensures coverage of long user histories.
-
KV caching makes inference fast: at serving time, only the most recent interactions are incrementally encoded, avoiding full-sequence recomputation.
-
**Multi-Objective Training.**The model predicts multiple targets:
-
Next-n item prediction - they predict the next n tokens so that the model doesn’t focus too much on each individual prediction.
-
Genre prediction (auxiliary classification) - they predict different fields within the token rather than just the token itself. This helps with overfitting to older titles.
Cold Start Solutions
New items (e.g. a movie trailer released yesterday) don’t have interaction history. Netflix embeds metadata—genre, cast, synopsis text—into the same space, and adaptively blends metadata embeddings with ID embeddings.
Embedding Stability Across Retrains
Each retrain shifts embeddings slightly. Without correction, downstream models break (e.g. ANN indices become invalid). Netflix applies an orthogonal transformation to map new embeddings onto the old basis, preserving relative geometry.
Scaling Laws Validation
Empirically, Netflix reports that increasing model size, data volume, and context length yields predictable improvements following power-law behavior—mirroring Kaplan et al. (2020) but in the domain of recommendations.
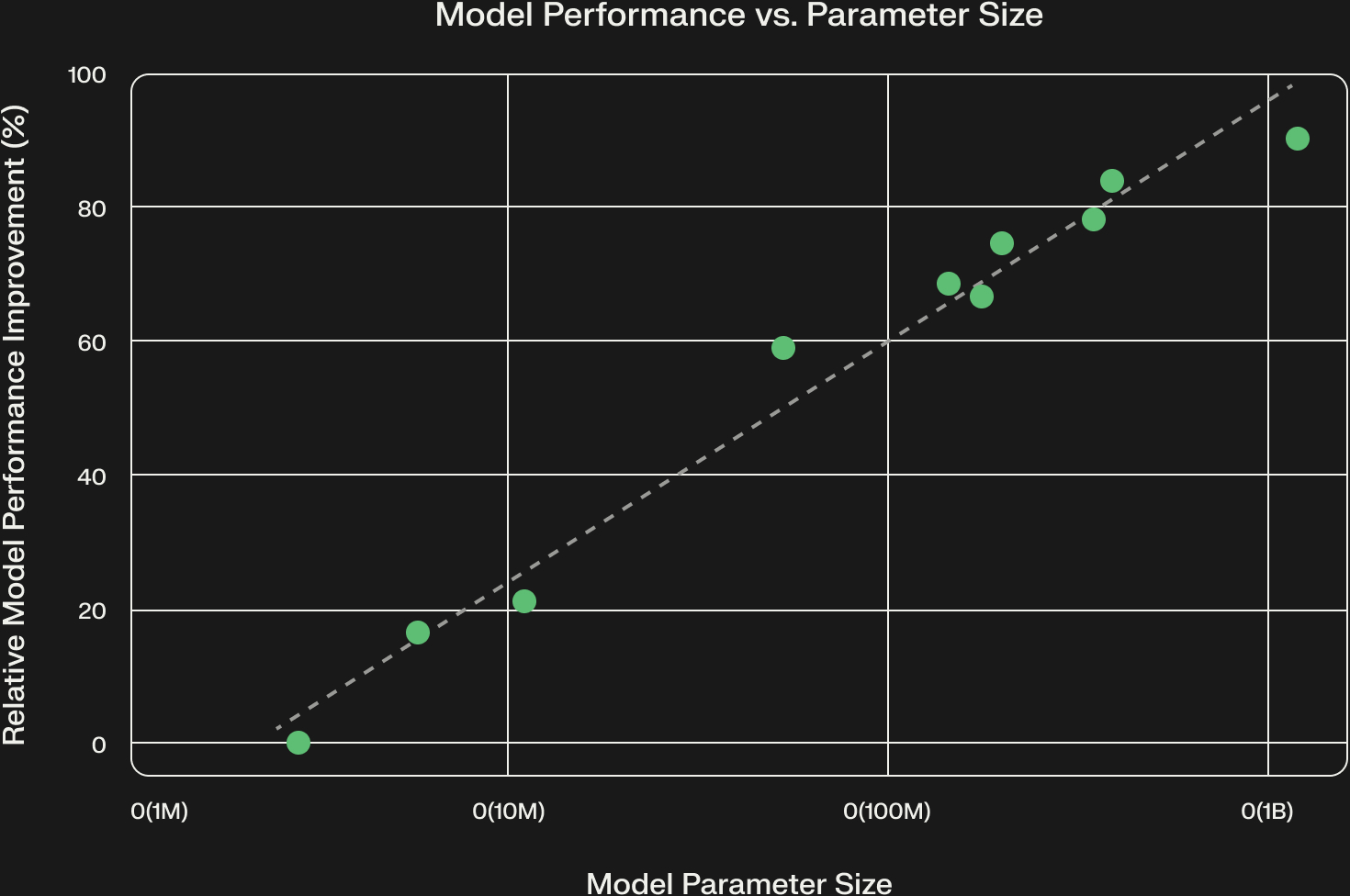
This is a case study in how scaling laws aren’t abstract curiosities—they are engineering guides. If you know your recsys model obeys a power law, you can forecast the return on investment of doubling your training data or compute budget.
4. Why Scaling Laws Matter for Production ML
So why are scaling laws so valuable outside of NLP? There are several main reasons:
- **Better results for end-users and businesses:**Bigger, more general-purpose models consistently outperform fragmented task-specific models. More accurate recommendations, better fraud detection, smarter personalization. This means better experiences for end-users and better outcomes for the business.
- **Unification and organizational leverage:**Maintaining a zoo of domain-specific models is expensive and brittle. A single foundation model reduces operational overhead and allows teams to focus on high-value improvements instead of plumbing.
- The predictability of scaling laws: The final piece of the puzzle is the reliable return on investment. Meta’s research confirmed that recommendation quality follows predictable power-law curves. This is the proof that investing in more data and larger models isn’t a gamble; it’s a measurable engineering roadmap.
This is the essence of ML 2.0: models scale, embeddings unify, and organizations consolidate around shared infrastructure.
5. Embeddings as the Currency of Production ML
In research, we often evaluate models on headline metrics: perplexity for language models, AUC for fraud detection, NDCG for recommendations. But in production, the real asset is not just the metric—it’s the embedding space the model creates.
Think of an embedding as a high-dimensional map. In an ideal space:
- Users cluster by latent taste vectors.
- Items cluster by shared properties (genre, format, price, demographic appeal).
- Temporal dynamics are encoded as trajectories across the space.
This space is incredibly versatile. At Netflix, the same embedding can drive:
- Retrieval: approximate nearest neighbor (ANN) search over embeddings to generate candidate recommendations.
- Ranking: use embeddings as input features to a downstream ranker optimized for engagement.
- Search: match user queries to content in the same vector space, reducing the gap between lexical and semantic search.
At Stripe, embeddings serve as a universal representation of “trust signals.” A merchant risk model and a fraud model are different tasks, but they both consume the same embedding vector—because the embedding already encodes patterns of suspicious behavior.
This shift—from model outputs to embeddings as the reusable currency—changes how ML teams operate. Instead of proliferating dozens of specialized models, teams invest in curating a single, stable embedding space, and then build thin adapters or heads for downstream tasks.
6. Convergence of Search and Recommendation
Traditionally, information retrieval (IR) and recommendation systems (RecSys) have been separate disciplines:
- IR/Search: user provides a query; the system finds the most relevant items.
- RecSys: system proactively suggests items a user may want.
But under the hood, both boil down to matching in embedding space.
- In search: encode the query and documents into the same space; compute similarity.
- In recsys: encode the user state (sequence of interactions) and items into the same space; compute similarity.
As embeddings become the unifying medium, the boundary between the two dissolves. Netflix has noted explicitly that their foundation model improves both search and recommendation, since both rely on the same representation of users and items. Similarly, e-commerce companies like Amazon and Shopify have moved toward joint architectures where the only difference between “search” and “recommend” is whether the query vector comes from user text or user behavior.
This convergence matters because it simplifies infrastructure: one model, one embedding store, many applications. It also suggests that future ML teams will organize around embedding-first design rather than siloed IR and RecSys functions.
8. Where This Is Going: ML 2.0 and Beyond
So what does this mean for the future of ML organizations?
- From silos to platforms: Instead of every product team training its own models, organizations unify around shared embeddings and foundation models.
- From models to representations: Embeddings become the core interface — reusable, composable, extensible.
- From narrow optimization to scaling roadmaps: Just as NLP teams track scaling curves, recommendation and search teams will plan capacity around predictable scaling laws.
If ML 0.0 was hand-crafted features, and ML 1.0 was deep learning task models, then ML 2.0 is the age of foundation models and unified embeddings. And just like with LLMs, the organizations that internalize scaling laws will have a compounding advantage.
9. Shaped’s Role in the ML 2.0 Transition
At Shaped, we’re building for this world. Our platform helps companies:
- Train domain-specific transformers on their behavioral data.
- Unify embeddings across search and recommendation so teams stop maintaining fragmented models.
- Deploy scalable infra patterns (sparse attention, ANN indexing, embedding stability transforms).
- Accelerate the ML 2.0 shift by reducing the engineering overhead of foundation model adoption.
We believe the future of applied ML is not 1,000 disconnected models—it’s a handful of shared embeddings, scaled by predictable laws, reused everywhere.
10. Conclusion: The Quiet Revolution
The splashiest scaling-law stories come from GPT-5 and Gemini. But the more profound transformation may be happening behind the scenes—inside the embedding spaces of companies like Netflix, Stripe, and Meta.
These are not just models; they are infrastructure shifts. They unify search and recommendation. They let embeddings become the universal currency of ML. They turn scaling laws into a practical playbook for production AI.
And as more organizations adopt this approach, we’ll see a new generation of ML orgs—leaner, faster, and more scalable—built not on 100 fragmented models, but on a few powerful foundation embeddings.
11. Further Reading & References
- Kaplan et al., Scaling Laws for Neural Language Models, (2020)
- Henighan et al., Scaling Laws for Autoregressive Generative Modeling, (2020)
- Netflix Tech Blog: A Foundation Model for Personalized Recommendation (2024)
- Stripe: Payments Foundation Model (2023)
- Pinterest: One Embedding to Rule Them All (Shaped blog, 2025)
- Agarwel etl al., OmniSearchSage (2024)
- Etsy: Unifying Embeddings for Large-Scale E-commerce (2023)
- Jiaqi et al. Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations. (2024)
- Meta: Generative Recommenders and Scaling Laws (Shaped blog, 2023)
- Eugene Yan, Scaling Laws for Recommender Systems & Search (2023)
- LessWrong: New Scaling Laws for Large Language Models. (2022)
- AIML: Beyond Bigger Models: The Evolution of Language Model Scaling Laws. (2024)
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.