
This series is for the engineers, ML practitioners, and architects tasked with bringing these complex systems to life. We will focus on the infrastructure, technologies, and engineering trade-offs required to deploy a high-performance ranking system in production. We’ll start where the user request begins: the online serving layer.
The 200ms Challenge
Whether it’s returning the top 10 blue links for a search query or populating a personalized “For You” feed, modern ranking systems face the same core challenge: sift through a massive corpus, execute a multi-stage ranking pipeline, and return a perfectly ranked list in under 200 milliseconds at the 99th percentile.
This is not a modeling problem; it’s an infrastructure and systems design problem. A monolithic service that tries to do everything—fetch candidates, hydrate features, and run models—will inevitably fail. It creates coupled scaling concerns: the part of your code that calls a vector database has very different performance characteristics from the part that runs a Transformer model on a GPU. To solve this, we must adopt a decoupled, purpose-built microservice architecture.
A Scalable Microservice Architecture for Ranking
A robust ranking system is an ensemble of specialized services, each optimized for a specific part of the pipeline and capable of scaling independently.
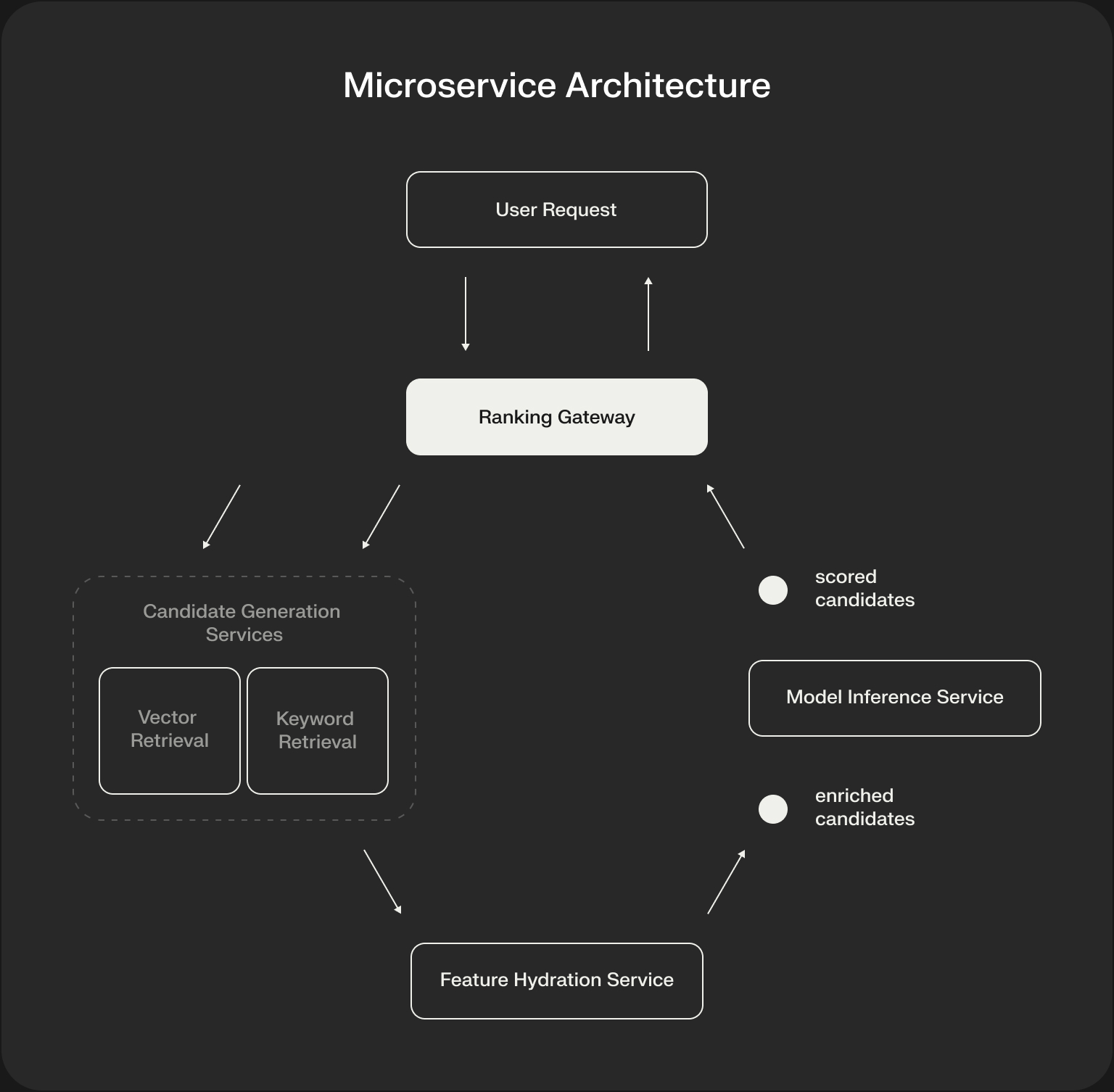
Let’s break down the role of each component:
- Ranking Gateway Service: This is the public-facing entry point and the orchestrator of the entire process. It takes the initial request (e.g., a search query or a user ID for recommendations), enforces timeouts, and manages the fan-out/fan-in logic of calling the downstream services in the correct sequence.
- Candidate Generation Services: Instead of one service, it’s best practice to have multiple, specialized services for each retrieval strategy (e.g., a vector-retrieval-service that talks to the vector DB, a keyword-retrieval-service using Elasticsearch). This allows you to scale your most expensive retrieval methods independently.
- Feature Hydration Service: A critical but often overlooked service. Its sole job is to take a list of candidate IDs and enrich them with the feature data needed for the scoring model. It acts as a performance-caching and abstraction layer in front of your feature store, batching lookups and simplifying the interface for the Gateway.
- Model Inference Service: This is a highly optimized service dedicated to running the scoring/ranking models. It’s responsible for managing hardware accelerators (like GPUs), handling model versioning, and running inference on batched inputs for maximum throughput.
Orchestration and Scaling with Kubernetes
This microservice architecture maps cleanly onto Kubernetes, but effective scaling requires choosing the right strategy for the right service.
Each service becomes a Kubernetes Deployment exposed via a Service. The real nuance lies in the autoscaling policies.
Autoscaling Policies: A Deep Dive
- Horizontal Pod Autoscaler (HPA): The standard autoscaler in Kubernetes. It scales pods based on observed metrics like CPU and Memory utilization.
- Pros: Simple, built-in, and effective for purely compute-bound workloads.
- Cons: It’s a lagging indicator. It scales up only after the existing pods are already under high load, which can lead to latency spikes during sudden traffic increases.
- Kubernetes Event-driven Autoscaling (KEDA): A more powerful, open-source alternative that scales based on external metrics. For serving systems, the most important metric is requests per second (RPS) or a related metric from a message queue.
- Pros: It’s a leading indicator. It scales proactively based on incoming demand, allowing for much more responsive and stable performance under variable load.
- Cons: Requires installing and managing the KEDA operator.
Here’s a decision framework for our ranking system:

The Hardware Question: Matching Compute to the Workload
Running this entire pipeline on a single type of machine is incredibly inefficient. Each service has a different performance profile and requires different hardware to operate optimally.
- Candidate Generation & Feature Hydration: These services are typically CPU-bound. Their work involves network calls, data serialization/deserialization, and simple business logic. Heavy-duty, standard CPU-based nodes are the most cost-effective choice.
- Feature Store (The Dependency): While not a service we build, the online feature store it relies on is Memory-bound. Its performance is dictated by how much of the feature data can be kept in RAM for low-latency access. This service should run on high-memory instances.
- Model Inference: This is where specialized hardware provides a massive return on investment. For complex ranking models like Transformers or large DLRMs, running batched inference on GPUs can provide a 10-100x throughput increase over CPUs. This is often the key to meeting a strict latency budget. Deploying these models using a dedicated inference server like NVIDIA’s Triton Inference Server or TorchServe is best practice, as they handle batching, model versioning, and hardware optimization automatically.
Conclusion
The online serving layer of a modern ranking system is a high-performance, distributed system in its own right. It’s a decoupled architecture of specialized microservices, each with its own scaling policies and hardware profile, orchestrated to deliver a single, coherent response within hundreds of milliseconds. We’ve designed the engine of our ranking system.
But what fuel does this engine run on? The performance of our models and the speed of our services are entirely dependent on the underlying data layer. In our next post, we will dive deep into the specialized databases that power this entire system: the Feature Store and the Vector Database.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.