Quick Answer: Why Your Agent Is Slow and Expensive
The defining problem of production agents isn’t model intelligence. It’s context window management. Attention cost scales quadratically with input length, doubling your context doesn’t double your cost, it quadruples it. Every extra chunk you stuff into the prompt makes everything slower, more expensive, and paradoxically, less accurate.
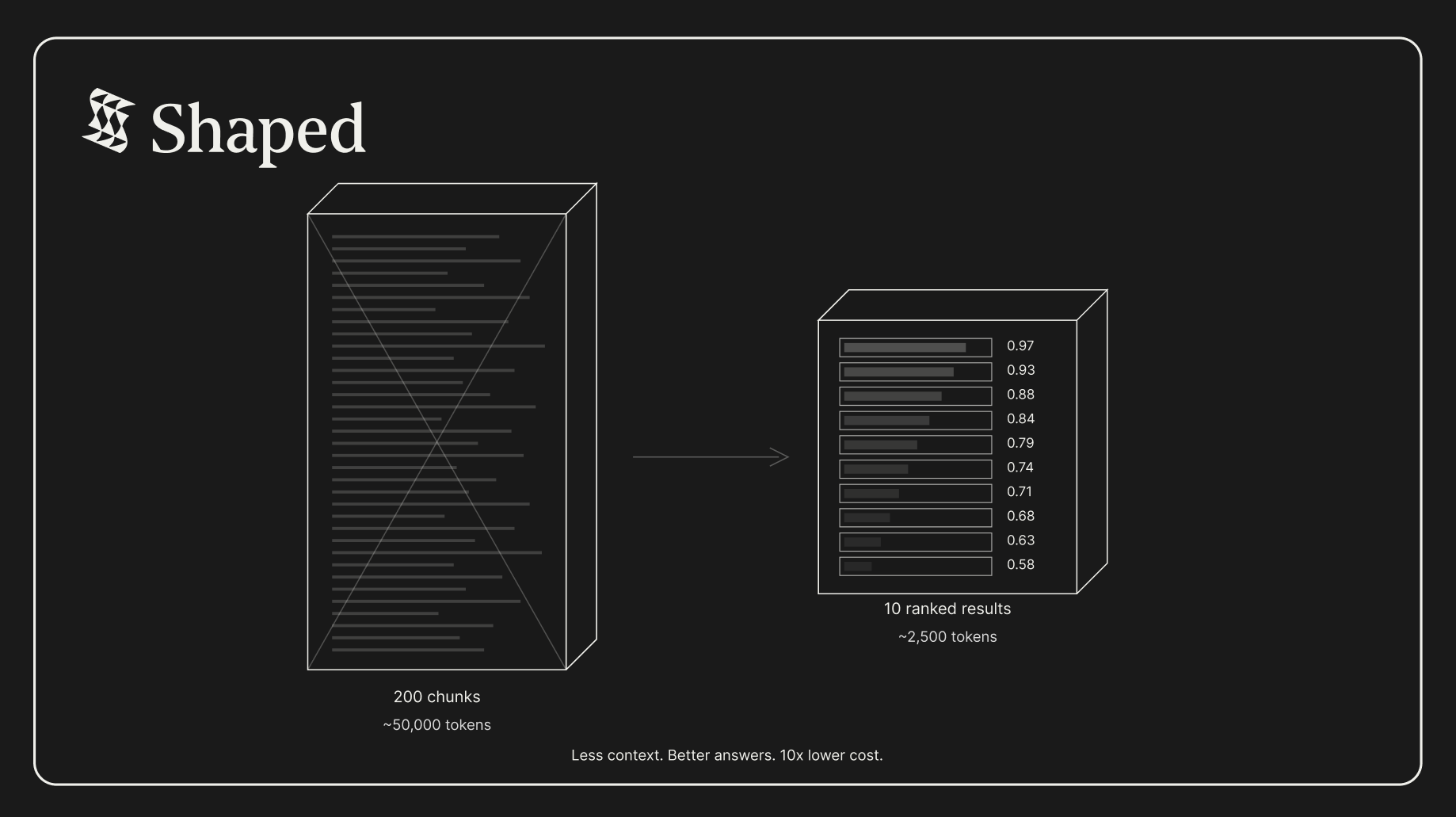
The fix isn’t a bigger context window. It’s a smarter one. Instead of passing 200 unranked chunks to your LLM, you pass 10 ranked results, selected by ML models trained on your data. Less context. Better answers. Lower cost.
Key Takeaways:
- Attention is quadratic, 2x the context tokens = 4x the compute cost. This is the fundamental constraint, and no model architecture change is fixing it soon.
- Stuffing the context window degrades quality, LLMs struggle with irrelevant context. More ≠ better. Research consistently shows that retrieval precision matters more than recall for downstream task performance.
- Cosine similarity is not ranking, vector search returns “similar” results. Trained ranking models return useful results. These are different things.
- Real-time signals matter more than model depth, for retrieval, the scaling law isn’t about parameter count. It’s about data freshness. What a user interacted with 30 seconds ago matters more than a 10% better embedding model.
- Multi-retriever pipelines solve it, fan out to vector search, lexical search, collaborative filtering, and trending simultaneously. Score with ML ensembles. Return the top 10 from 10,000 candidates. One API call. Under 50ms.
Time to read: 18 minutes | Includes: 5 code examples, 2 architecture diagrams, 1 comparison table
Table of Contents
- The Quadratic Wall
- Why Stuffing Doesn’t Scale
- The Retrieval Scaling Law
- Part 1: The Naive Approach, Stuff Everything
- Part 2: The Shaped Way, Rank Everything
- Real-Time Behavioral Signals: The Missing Dimension
- Comparison Table
- FAQ
The Quadratic Wall
Here’s the math that governs every production agent deployment.
The self-attention mechanism in transformers computes attention scores between every pair of tokens in the input. For an input of length n, this requires O(n²) operations. In practice:
| Context Tokens | Relative Compute Cost | Relative Latency |
|---|---|---|
| 1,000 | 1x | ~200ms |
| 4,000 | 16x | ~800ms |
| 16,000 | 256x | ~3.2s |
| 64,000 | 4,096x | ~12s+ |
| 128,000 | 16,384x | ~30s+ |
These numbers are approximate and vary by model architecture, but the relationship holds: doubling the context quadruples the cost.
This isn’t a temporary limitation. It’s fundamental to how attention works. There are ongoing research efforts to reduce this (linear attention, sparse attention, ring attention), but in production today, with Claude, GPT-4, Gemini, you’re paying the quadratic tax on every token you pass in.
This means every irrelevant chunk in your context window is actively harmful. It:
- Costs more compute, you’re paying quadratic cost for information the model doesn’t need
- Increases latency, time-to-first-token scales with input length
- Degrades quality, research on “lost in the middle” shows LLMs struggle to use information buried in long contexts
- Reduces throughput, longer contexts mean fewer concurrent requests per GPU
The implication is counterintuitive: the best way to improve your agent is to give it less context, not more. But it has to be the right less.
Why Stuffing Doesn’t Scale
The default architecture for most RAG pipelines today looks like this:
(top-k=200, cosine similarity)
into system prompt
This works in demos. It breaks in production. Here’s why.
Problem 1: Same results for every user
Vector search returns chunks by semantic similarity to the query. It doesn’t know who’s asking. A junior developer and a CTO asking the same question get the same 200 chunks, even though they need completely different levels of detail, different documents, and different context.
Problem 2: No learned relevance
Cosine similarity measures distance in embedding space. It does not measure usefulness. A chunk can be semantically similar to the query and completely unhelpful for the task. There’s no feedback loop, the system never learns which retrieved chunks actually led to good answers.
Problem 3: Retrieval and reranking are separate systems
To improve on raw vector search, teams bolt on a reranker (Cohere, Jina, a cross-encoder). Now you have:
- A vector database (Pinecone, Weaviate, Qdrant)
- A reranker API
- Custom filtering logic
- Maybe a BM25 index for keyword matching
- Maybe a feature store for user context
- Glue code to stitch it all together
Each system has its own latency, its own failure mode, its own deployment. The “simple” RAG pipeline is now five services deep.
Problem 4: No diversity control
Vector search returns the most similar results. Similar results are often redundant. If your top 10 chunks are all from the same document section, you’ve wasted 9 context slots on near-duplicate information. The LLM gets one perspective repeated 10 times instead of 10 diverse perspectives.
The enterprise reality
These problems compound at enterprise scale. We’ve spoken with engineering leaders at Fortune 500 companies who describe the same pattern: they deployed agents internally, usage exploded, and now they’re staring at inference bills that are growing faster than the value the agents provide.
The bottleneck isn’t the model. It’s what goes into the context window. Every enterprise deploying hundreds of AI workflows is discovering the same thing: context window management is the #1 infrastructure problem.
The Retrieval Scaling Law
In classic NLP and computer vision, scaling laws are about parameters. Bigger model = better performance. This is the Chinchilla/Kaplan framing that’s driven the race to trillion-parameter models.
But for retrieval, and for production agents that depend on retrieval, the scaling law is different. It’s about data freshness and ranking quality, not model depth.
Consider two retrieval systems:
System A: State-of-the-art embedding model (1B parameters), cosine similarity, batch-updated index, no personalization.
System B: Good embedding model (110M parameters), trained ranking model (LightGBM) on interaction data, real-time streaming index, per-user scoring.
System B wins. Every time. In every production deployment we’ve seen.
Why? Because the ranking model has learned what’s useful from actual user behavior. It knows that when user X asks about “authentication,” they usually need the API reference, not the conceptual overview. It knows that a document updated 2 hours ago is more relevant than one updated 6 months ago for this particular query. It knows that chunks from the “troubleshooting” section have a 3x higher helpfulness rate than chunks from “introduction.”
The embedding model doesn’t know any of this. It just measures semantic distance.
The retrieval scaling law: performance scales with signal freshness and ranking sophistication, not embedding model size.
This is the insight that separates production retrieval systems from demo RAG pipelines. Google figured this out 20 years ago for web search, raw text similarity was never enough. You need PageRank, click-through models, freshness signals, personalization. The same applies to agent context, except the data is bespoke to each company, not constant across the internet. Which makes it harder.
Part 1: The Naive Approach, Stuff Everything
Here’s what the standard RAG pipeline looks like in production code. We’ll walk through exactly why it breaks.
Architecture
(OpenAI API)
(Pinecone)
generates answer
into prompt
Implementation
# naive_rag.py
import openai
import pinecone
import anthropic
# Step 1: Embed the query
def get_embedding(text: str) -> list[float]:
response = openai.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
# Step 2: Retrieve top-k from vector DB
def retrieve_chunks(query: str, top_k: int = 200) -> list[dict]:
embedding = get_embedding(query)
results = pinecone_index.query(
vector=embedding,
top_k=top_k,
include_metadata=True
)
return [
{
"content": match.metadata["content"],
"source": match.metadata["source"],
"score": match.score # cosine similarity — NOT relevance
}
for match in results.matches
]
# Step 3: Stuff everything into the prompt
def answer_question(query: str) -> str:
chunks = retrieve_chunks(query, top_k=200)
# Concatenate all chunks into one massive context block
context = "\n\n---\n\n".join([
f"[{chunk['source']}]\n{chunk['content']}"
for chunk in chunks
])
# This context block can easily be 50,000+ tokens
response = anthropic.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1024,
system=f"Answer the user's question using ONLY the context below.\n\n{context}",
messages=[{"role": "user", "content": query}]
)
return response.content[0].textWhat you’re paying
Let’s do the math for a single query with 200 retrieved chunks averaging 250 tokens each:
| Component | Tokens | Cost (Claude Sonnet) |
|---|---|---|
| System prompt + context | ~50,000 | ~$0.15 |
| User query | ~50 | negligible |
| Output | ~500 | ~$0.0075 |
| Total per query | ~50,550 | ~$0.16 |
At 10,000 queries/day, that’s $1,600/day or $48,000/month in LLM inference alone. And that’s one agent.
Now what if you sent 10 ranked results instead of 200 unranked chunks?
| Component | Tokens | Cost (Claude Sonnet) |
|---|---|---|
| System prompt + context | ~2,500 | ~$0.0075 |
| User query | ~50 | negligible |
| Output | ~500 | ~$0.0075 |
| Total per query | ~3,050 | ~$0.015 |
That’s $150/day or $4,500/month. A 10x cost reduction, and the answers are better because the LLM isn’t drowning in irrelevant context.
The question is: how do you pick the right 10?
Part 2: The Shaped Way, Rank Everything
Shaped replaces the “retrieve 200, stuff everything” pattern with a multi-retriever pipeline that retrieves from multiple sources, filters, scores with trained ML models, and reorders for diversity, all in one API call, under 50ms.
Architecture
+ user_id + history
(50 candidates)
(50 candidates)
Collab (50)
Popular (50)
(rules + metadata)
(ML model ensemble)
generates answer
Implementation
Step 1: Define your engine
# agent_context_engine.yaml
data:
item_table:
name: knowledge_chunks # Your docs, indexed with item_id
type: table
user_table:
name: agent_users # User profiles with user_id
type: table
interaction_table:
type: query
query: |
SELECT user_id, item_id, created_at,
was_helpful AS label # Track which context helped the agent
FROM context_feedback
index:
embeddings:
- name: text_embedding
columns: [content, title, source]
model: bge-large-en-v1.5
lexical:
- name: keyword_index
columns: [content, title]
training:
models:
- name: helpfulness_score # Learns what context is useful
policy_type: lightgbm
- name: elsa_collab # Collaborative signal from interactions
policy_type: elsa
strategy: early_stopping
deployment:
data_tier: fast_tier # Redis-backed for <50ms latencyWhat this does:
interaction_tabletracks which retrieved chunks actually helped the agent (thumbs up/down, task completion, user feedback). This is the signal that trains the ranking model.helpfulness_scoreis a LightGBM model trained on this interaction data. It learns patterns like “chunks from the API reference section are 3x more helpful for user_8f3a than chunks from the overview.”elsa_collabis a collaborative filtering model. It learns that users who found chunk A helpful also found chunk B helpful, even if A and B aren’t semantically similar.fast_tierdeploys the engine on Redis-backed infrastructure for sub-50ms query latency.
Step 2: Query with ShapedQL
-- Multi-retriever hybrid search with learned ranking
SELECT *
FROM
-- Semantic search
text_search(query='$query_text', mode='vector',
text_embedding_ref='text_embedding', limit=50,
name='vector_search'),
-- Keyword search
text_search(query='$query_text', mode='lexical',
fuzziness=2, limit=50,
name='lexical_search'),
-- Items similar to what this user found helpful before
similarity(embedding_ref='text_embedding',
encoder='interaction_round_robin',
input_user_id='$user_id', limit=50)
WHERE source_type IN ('doc', 'tool_output', 'memory')
ORDER BY score(
expression='0.4 * retrieval.vector_search
+ 0.2 * retrieval.lexical_search
+ 0.4 * helpfulness_score',
input_user_id='$user_id',
input_interactions_item_ids='$interaction_item_ids'
)
REORDER BY diversity(diversity_lookback_window=15)
LIMIT 10One query does what previously required five services:
- Vector search, semantic similarity (replaces Pinecone query)
- Lexical search, keyword matching (replaces BM25/Elasticsearch)
- Collaborative similarity, “users like you found these helpful” (replaces custom feature engineering)
- ML scoring, blends retrieval scores with a trained helpfulness model (replaces reranker API)
- Diversity reorder, ensures the 10 results cover different topics, not 10 variations of the same chunk (replaces custom dedup logic)
Step 3: Wire it into your agent
import requests
import anthropic
SHAPED_API_KEY = "your-api-key"
def get_ranked_context(query: str, user_id: str, recent_docs: list[str]) -> list[dict]:
"""
Retrieve ranked context from Shaped — 10 results from 10,000+ candidates.
"""
response = requests.post(
"https://api.shaped.ai/v2/engines/agent_context_engine/query",
headers={
"Content-Type": "application/json",
"x-api-key": SHAPED_API_KEY
},
json={
"query": """
SELECT *
FROM text_search(query='$query_text', mode='vector',
text_embedding_ref='text_embedding', limit=50, name='vs'),
text_search(query='$query_text', mode='lexical',
fuzziness=2, limit=50, name='ls'),
similarity(embedding_ref='text_embedding',
encoder='interaction_round_robin',
input_user_id='$user_id', limit=50)
ORDER BY score(
expression='0.4 * retrieval.vs + 0.2 * retrieval.ls
+ 0.4 * helpfulness_score',
input_user_id='$user_id',
input_interactions_item_ids='$interaction_item_ids')
REORDER BY diversity(diversity_lookback_window=15)
LIMIT 10
""",
"parameters": {
"query_text": query,
"user_id": user_id,
"interaction_item_ids": recent_docs
},
"return_metadata": True
}
)
return response.json()["results"]
def answer_question(query: str, user_id: str, recent_docs: list[str]) -> str:
"""
Answer a question with ranked context — 10 results, not 200.
"""
results = get_ranked_context(query, user_id, recent_docs)
# 10 ranked chunks ≈ 2,500 tokens instead of 50,000
context = "\n\n".join([
f"[{r['source']}] (relevance: {r['score']:.2f})\n{r['content']}"
for r in results
])
client = anthropic.Anthropic()
response = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=1024,
system=f"Answer the user's question using the ranked context below. "
f"Context is ordered by relevance — prioritize earlier items.\n\n{context}",
messages=[{"role": "user", "content": query}]
)
return response.content[0].textWhat changed
| Naive RAG | Shaped | |
|---|---|---|
| Chunks sent to LLM | 200 (unranked) | 10 (ranked by trained ML) |
| Context tokens | ~50,000 | ~2,500 |
| Cost per query | ~$0.16 | ~$0.015 |
| Retrieval latency | ~200ms (1 source) | <50ms (4 sources) |
| Personalized | No | Yes, per-user scoring |
| Learns from usage | No | Yes, continuous retraining |
| Diversity control | No | Yes, dedup + topic spread |
| Services to operate | 3-5 | 1 API |
Real-Time Behavioral Signals: The Missing Dimension
Here’s something that memory tools like Mem0, Letta, and Zep don’t capture: what’s happening right now.
Memory tools store and manage information from past conversations. They’re good at “this user prefers concise answers” or “we discussed the Q3 roadmap yesterday.” That’s valuable context.
But they don’t know what the user interacted with 30 seconds ago. They don’t know that across the platform, a specific document just spiked in views because of a production incident. They don’t know that users similar to this one have been clicking on “migration guide” content all morning.
These are real-time behavioral signals, and they’re the most predictive features for retrieval ranking.
Shaped’s connectors include real-time streaming sources (Kafka, Segment, Amplitude) that update interaction data continuously. When you define an interaction_table in your engine, Shaped tracks:
- What this user interacted with in the last 30 seconds, last minute, last 5 minutes
- What similar users are interacting with right now (collaborative signals)
- What’s trending across the platform (popularity signals)
- Recency of the content itself (freshness signals)
These signals feed directly into the ranking models. The helpfulness_score model retrains on a schedule, and the _derived_popular_rank column updates in real time.
This is the retrieval scaling law in action: keeping the model small but getting the data there faster. A LightGBM model with fresh signals beats a transformer reranker with stale data.
# Real-time connector example
data:
interaction_table:
name: agent_interactions
type: table
connector:
type: segment # Real-time streaming
source_id: your_segment_source
# Events appear in Shaped within 30 secondsCombined with a query that uses these signals:
SELECT *
FROM text_search(query='$query_text', mode='vector',
text_embedding_ref='text_embedding', limit=50),
column_order(columns='_derived_popular_rank ASC', limit=50)
ORDER BY score(
expression='0.6 * helpfulness_score + 0.4 * elsa_collab',
input_user_id='$user_id',
input_interactions_item_ids='$interaction_item_ids'
)
LIMIT 10The _derived_popular_rank retriever surfaces content that’s trending right now. The elsa_collab model captures what similar users are finding useful. The interaction_item_ids parameter passes the user’s recent interactions so the scoring model can personalize in real time.
Memory tools remember the past. Shaped ranks the present.
Comparison Table
| Stuff Everything (Naive RAG) | Vector DB + Reranker | Memory Layer (Mem0/Letta/Zep) | Shaped | |
|---|---|---|---|---|
| What it does | Retrieve top-k, stuff into prompt | Retrieve + rerank | Store and manage agent memories | Multi-retriever ranked retrieval |
| Context tokens | 50,000+ | 5,000-10,000 | Varies | ~2,500 (10 ranked results) |
| Cost per query | ~$0.16 | ~$0.04-0.08 | Depends on memory size | ~$0.015 |
| Ranking | Cosine similarity | Similarity + cross-encoder | Similarity + basic reranking | Trained ML models + ensembles |
| Personalized | No | No | User-scoped memory | Per-user ML scoring |
| Real-time signals | No | No | From conversations only | From all interaction data |
| Learns | No | No | From conversations | Continuous retraining on all data |
| Diversity | No | No | No | Yes, reorder step |
| Retrieval latency | 50-200ms | 200-500ms | 200ms-1.4s | <50ms p99 |
| Services to run | 2 (vector DB + LLM) | 3-5 | 2-3 | 1 API |
Note: These approaches are not mutually exclusive. Shaped complements memory layers. Use Mem0, Letta, or Zep for conversation management (summarization, conflict resolution, long-term memory). Use Shaped for ranking everything your agent retrieves, documents, tools, memories, and knowledge. You can even index your memory store’s outputs as items in a Shaped engine and rank them alongside your other data sources.
FAQ
Q: Why not just use a bigger context window?
A: Because of the quadratic cost. Gemini and Claude now support 1M+ token windows, but using them is expensive and slow. A 200K context query can take 30+ seconds and cost $1+. More importantly, research shows LLMs perform worse with large amounts of irrelevant context, they get confused by noise, miss key details buried in the middle, and produce lower-quality answers. The better approach: send less context, but make it the right context.
Q: How does the helpfulness_score model know what’s “helpful”?
A: You define it through the interaction_table. Track signals like: did the user thumbs-up the response? Did they complete the task? Did they ask a follow-up (indicating the first answer was insufficient)? Did they click through to the source document? These signals become the label column that the LightGBM model trains on. Over time, it learns which documents, sections, and content types are most useful for which users and queries.
Q: What if I don’t have interaction data yet?
A: Start without the training block. Shaped works as a hybrid search engine out of the box, vector search + lexical search + filtering + diversity reorder. This alone is a significant upgrade over single-source vector search. As you accumulate interaction data, add the training models. Ranking quality improves continuously.
Q: How is this different from a reranker like Cohere or Jina?
A: A reranker takes a list of candidates and re-scores them using a cross-encoder. Shaped does that and more: it handles the initial retrieval (from multiple sources), filtering, scoring (with models trained on your data, not generic models), and diversity reordering, all in one system. A reranker is one step in the pipeline. Shaped is the whole pipeline.
Q: Can I use Shaped with my existing vector database?
A: Yes. Use the candidate_ids retriever to pass pre-retrieved IDs from your existing vector DB into Shaped for scoring and reranking. Or migrate your data into Shaped’s connectors and let it handle retrieval end-to-end. Both work.
Q: What about tool selection for agents?
A: Index your tool catalog as items in a Shaped engine. Each tool’s description, parameters, and usage examples become searchable fields. When the agent needs to select tools, query Shaped with the user’s intent, it returns the top 5 tools ranked by semantic match and past usage patterns. This scales to hundreds of tools without stuffing all descriptions into the context.
Q: Does this work for multi-agent architectures?
A: Yes. Each agent can query the same Shaped engine with different parameters. Agent A retrieves context for code review, Agent B retrieves context for customer support, Agent C retrieves context for data analysis, all from the same underlying data, ranked differently based on each agent’s interaction patterns.
Conclusion
The scaling law for production agents isn’t about bigger models or longer context windows. It’s about what goes into the context window, ranked by learned signals, personalized to the user, drawn from multiple retrieval sources, and updated in real time.
The math is simple: 10 ranked results in 2,500 tokens outperforms 200 unranked chunks in 50,000 tokens. Every time. At 10x lower cost. With better answers.
Context window management is the infrastructure problem of the agent era. Solve it, and everything downstream improves: accuracy, latency, cost, user satisfaction. Ignore it, and you’re paying quadratic cost for linear (or negative) value.
See Shaped in action
Talk to an engineer about your specific use case — search, recommendations, or feed ranking.