
ShapedQL
Check out our new Free Playground(no login required) to see the engine in action
The Problem: The “Frankenstein” Stack
Most engineering teams today are forced to maintain what we call a “Frankenstein stack.”
To build a high-quality “For You” feed, a personalized search bar, or an AI agent with long-term memory, you typically have to glue together half a dozen fragmented tools:
- A Vector Database (like Pinecone) for semantic retrieval.
- A Search Engine (like Elasticsearch) for keyword matching.
- A Feature Store (like Redis) to hold user session data.
- Thousands of lines of Python “spaghetti code” to handle business logic, filtering, and re-ranking.
The result is a brittle “house of cards.” It’s stateless, slow to iterate on, and impossible to debug. When a user asks, “Why was this item ranked first?” engineers usually don’t have an answer.
The Solution: From Documents to Decisions
ShapedQL was built to move the industry from document retrieval to real-time decisions.
Unlike traditional search engines that are stateless by design, ShapedQL treats “User Context” as a first-class citizen. It doesn’t just look for items that are similar to a query; it finds items that a specific user is most likely to engage with right now.
We’ve collapsed the entire relevance lifecycle into a 4-stage pipeline that you can define in a single SQL query:
- Retrieve: Fetch candidates from multiple sources (Hybrid Search, Social Graphs, or Trending lists).
- Filter: Apply hard business constraints (e.g., “only show items in stock and under $200”).
- Score: Rank results using real-time machine learning models optimized for your business goals (Clicks, Conversions, or Watch Time).
- Reorder: Optimize the final list for Diversity and Exploration, ensuring the user experience stays fresh and avoids repetition.
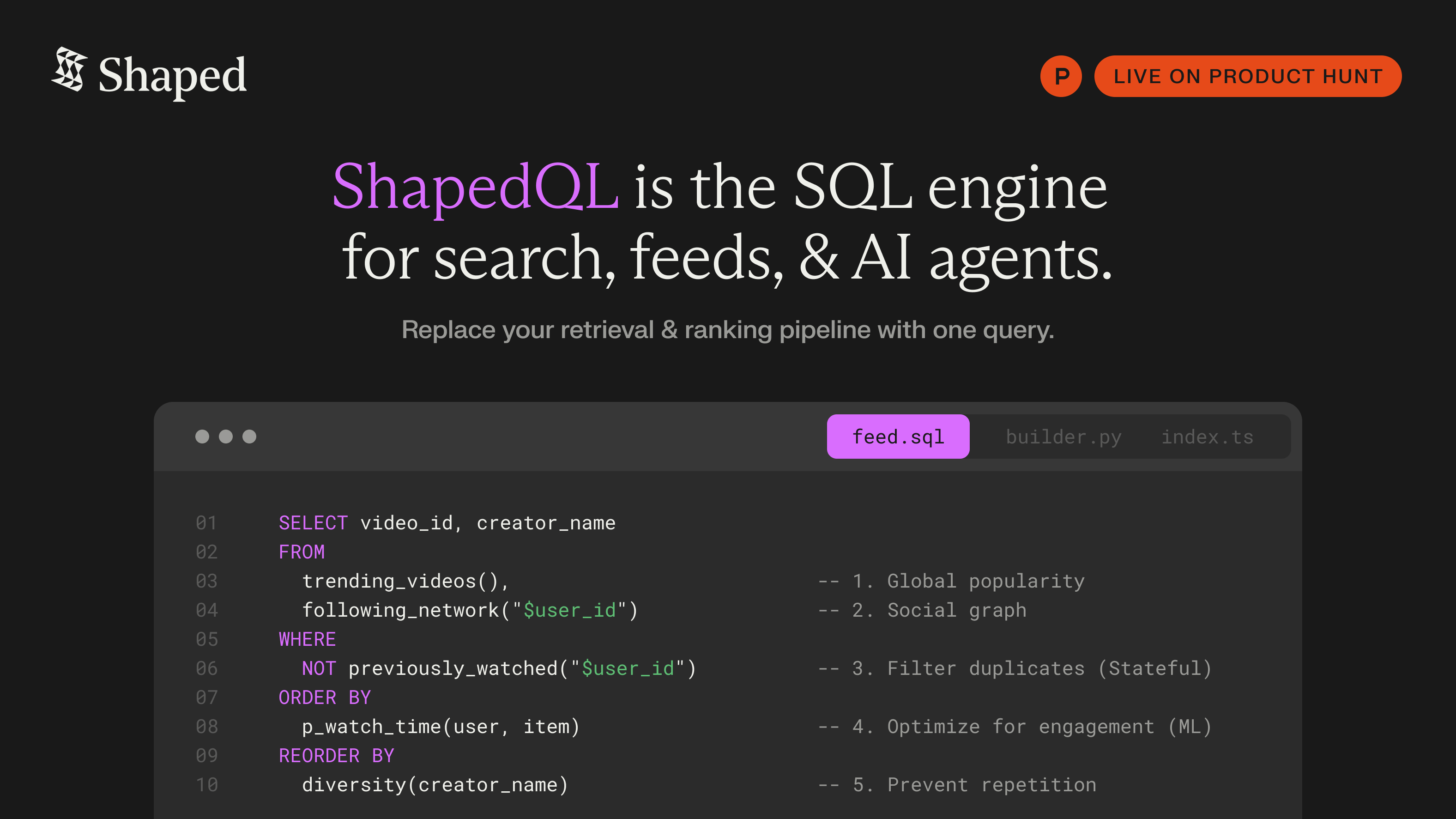
ShapedQL in Action
Here is what a modern discovery feed looks like in ShapedQL. This replaces roughly 2,000 lines of traditional backend infrastructure:
More than just a Query Language
ShapedQL isn’t just a syntax; it’s an end-to-end platform that automates the heavy lifting of data engineering and MLOps:
- Real-Time Connectors: Sync data from Snowflake, BigQuery, Kafka, or Segment in milliseconds.
- Generative Enrichment: Use LLMs to automatically tag images, clean messy product descriptions, and normalize data on the fly.
- Automated MLOps: Shaped continuously trains and fine-tunes your ranking models based on live user behavior, so you never have to manage a training pipeline again.
Real-World Impact
We’ve already seen the power of this approach our customers. By migrating their legacy search infrastructure to Shaped, one customer was able to replace a massive, unmaintainable 3000 lines of elasticsearch rules with a simple ShapedQL query.
The result? An 11% lift in search conversions and a 10x increase in experimentation velocity. They can now test new ranking theories in minutes, not weeks.
Start Building for Free
Whether you are building a TikTok-quality discovery feed, an e-commerce “similar items” widget, or an AI Agent that needs to make smart, personalized decisions, ShapedQL is built for you.
We are live on Product Hunt today! Check out our new Free Playground (no login required) to see the engine in action.
We can’t wait to see what you build.
Want a live walkthrough of this feature?
Book time with the team and we'll show you exactly how it works.